[평범한 학부생이 하는 논문 리뷰] FlowAR : Scale-wise Autoregressive Image Generation Meets Flow Matching (ICML 2025)
Paper : https://arxiv.org/abs/2412.15205
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
Autoregressive (AR) modeling has achieved remarkable success in natural language processing by enabling models to generate text with coherence and contextual understanding through next token prediction. Recently, in image generation, VAR proposes scale-wis
arxiv.org
Abstract
기존 VAR은 다음 두가지의 문제점을 지닌다.
- 복잡하고 경직된 scale design은 next scale prediction에서 일반화를 제한한다.
- 동일한 복잡한 scale 구조를 discrete tokenizer에 대한 generator의 의존성은 tokenizer를 update하는데 modularity와 flexibility를 제한한다.
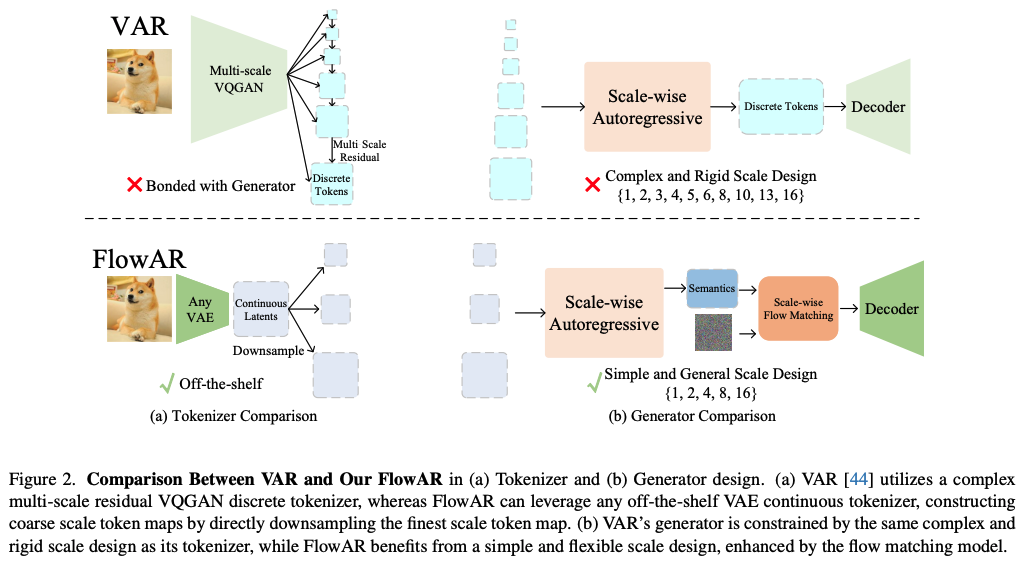
본 논문은 이러한 문제를 해결하기 위해서 FlowAR을 제안한다. 이는 VAR의 복잡한 multi-scale residual tokenizer에 대한 필요를 없애고 어떤 종류의 VAE든 간에 이에 대한 사용을 가능하게 한다.
1. Method
1.1 FlowAR
Overview

VAR과 비교해서 두가지 improvements를 도입한다.
- multi-scale VQGAN discrete tokenizer를 off-the-shelf VAE continuous tokenizer로 대체
- flow matching을 사용해서 per-scale prediction을 modeling
Simple Scale Sequence with Any VAE Tokenizer
이미지가 주어지면, off-the-shelf VAE를 이용해서 continuous latent representation $F \in \mathbb{R}^{c \times h \times w}$를 추출한다. 그러고 나서 다음과 같이 latent $F$를 downsampling함으로써 coarse-to-fine scale의 set을 구축한다.
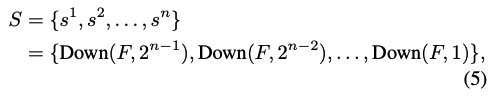
본 논문의 multi-scale token maps $S$는 highest-resolution latent $F$를 직접 downsampling함으로써 얻어지고 이는 복잡한 multi-scale residual VQGAN design에 대한 필요를 없앤다.
Autoregressive Transformer를 이용해서 각 scale의 categorical 분포를 modeling하는 VAR과 다르게, 본 논문은 각 scale에 대한 conditioning information을 생성하기 위해서 Transformer를 활용하고, scale-wise flow matching model은 이 information을 기초로 scale의 확률분포를 capture한다.
Generating Conditioning Information via Scale-wise Autoregressive Transformation
각 후속 sclae에대한 conditioning 정보를 생성하기 위해서, 본 논문은 모든 이전의 scale로부터 얻어진 condition을 활용한다.

본 논문은 $\hat{s}^i$를 i번째 scale에 대한 semantics라고 한다. 이는 per-scale probability distribution을 학습하도록 flow matching module에 condition으로 사용된다.
Scale-wise Flow Matching Model Conditioned by Autoregressive Transformer Output
FlowAR은 flow matching을 autoregressive Transformer의 output $\hat{s}^i$을 condition으로 받아 scale latent $s^i$를 생성하도록 flow matching을 확장한다. 학습동안, target distribution으로부터 scale latent $s^i$가 주어지면 본 논문은 time step $t \in [0,1]$와 source noise distribution에서 source noise sample $F^i_0$를 샘플링한다. Diffusion model에서와 유사하게 conditioned latent $\hat{s}^i$의 형태와 맞추기 위해서 일반적으로 $F_0^i \sim \mathcal{N}(0,1)$으로 셋팅한다. 그러고 나서 interpolated input $F^i_t$를 다음과 같이 구축한다.

Model은 $F^i_t$를 사용해서 velocity $V^i_t$를 예측하도록 학습된다.
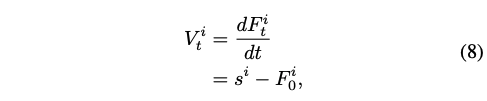
Class나 textual information에 대해서 velocity prediction을 condition하는 기존 방식들과 다르게, 본 논문은 autoregressive Transformer의 output인 scale-wise semantics $\hat{s}^i$에 대해 condition을 준다. FlowAR에서는 condition과 image latent가 동일한 길이를 가진다. Scale-wise flow matching의 training objective는 다음과 같다.

이 방식은 model이 scale-wise information을 bi-direction으로 capture할 수 있도록하고, 이는 이미지 생성에서 유연성과 효율성을 강화시킨다.
Scale-wise Injection of Semantics via Spatial-adaLN
Key design은 어떻게 semantic information $\hat{s}^i$를 잘 주입하는지 결정하는 것이다. 단순히 concat하는 방식은 다음 두가지 문제를 지닌다.
- Flow matching model의 input의 sequence length를 증가시키고 이는 computational cost를 증가시킨다.
- 간접적인 semantic 주입을 제공하고 semantic guidance의 효과를 약화시킨다.
이러한 문제점들을 해결하기 위해서, 본 논문은 position-by-position semantic injection을 위한 spatially adaptive layernorm (Spatial-adaLN)을 사용하는 것을 제안한다.

Scale, shift, gate parameter가 공간적인 정보가 부족한 전통적인 adaptive normalization과 다르게, spatial adaptive normalization은 positional control을 제공하고, 이는 autoregressive Transformer로부터의 semantics에 대한 의존성을 가능하게 한다. 본 논문은 flow matching module의 모든 Transformer block에 Spatial-adaLN을 적용한다.
Inference Pipeline
Inference 초기에, autoregressive Transformer는 class condition $C$만을 이용해서 초기 semantics $\hat{s}^1$을 생성한다. 이 semantic $\hat{s}^1$은 flow matching module에 컨디션되고, 점진적으로 $s^1$에 대한 target distribution으로 변환된다. 결과로 나온 token map은 2로 upsampling되고 class condition과 결합된다. 그 후에 autoregressive Transformer로 들어가 semantics $\hat{s}^2$을 생성한다. 이는 다음 scale을 위해서 flow matching module에 condition된다. 이 과정을 $n$번 반복해서 최종적으로 final token map $s^n$가 추정되고 VAE decoder를 통해 decode돼 이미지를 생성한다.
2. Experiments
2.1 Main Results
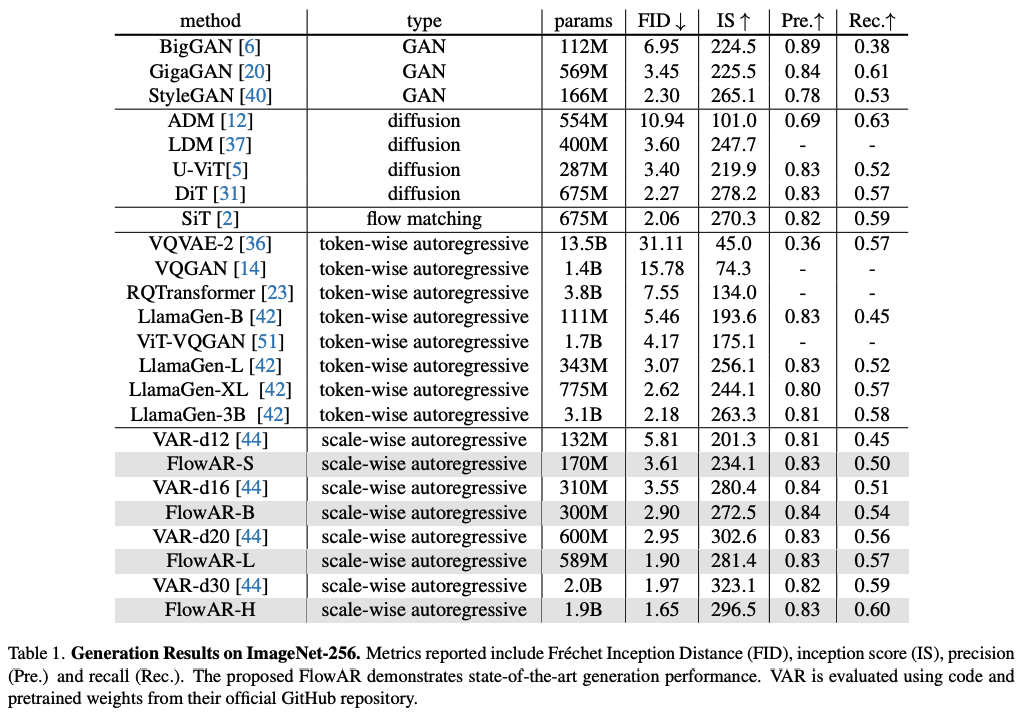
Quantitative Results
Visualization

2.2 Ablation Studies
Tokenizer Compatibility

Construction of Scale Sequence
이미지를 downsampling을 하냐, latent를 downsampling을 하냐에 대한 실험을 진행한다.

Scale Configurations

Scale-wise Flow Matching Model

Injection of Semantics
