
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- BOJ
- 논문리뷰
- inversion
- Programmers
- flow matching
- unlearning
- image editing
- image generation
- ddim inversion
- 코테
- flow models
- Python
- Concept Erasure
- diffusion
- video generation
- rectified flow matching models
- Machine Unlearning
- diffusion model
- 프로그래머스
- video editing
- diffusion models
- 3d generation
- 네이버 부스트캠프 ai tech 6기
- visiontransformer
- rectified flow
- VirtualTryON
- rectified flow models
- memorization
- flow matching models
- 3d editing
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] FreeInv : Free Lunch for Improving DDIM inversion 본문
[평범한 학부생이 하는 논문 리뷰] FreeInv : Free Lunch for Improving DDIM inversion
junseok-rh 2025. 5. 1. 23:30https://yuxiangbao.github.io/FreeInv/
FreeInv: Free Lunch for Improving DDIM Inversion
Naive DDIM inversion process usually suffers from a trajectory deviation issue, i.e., the latent trajectory during reconstruction deviates from the one during inversion. To alleviate this issue, previous methods either learn to mitigate the deviation or de
yuxiangbao.github.io
Abstract
Naive DDIM은 reconstruction과 inversion에서의 latent trajectory가 다르다는 문제를 가진다. 본 논문에서는 이 문제를 효과적이고 효율적으로 해결하기 위해서 nearly free-lunch method (FreeInv)를 제안한다.
1. Methodology
1.1 DDIM Inversion Revisiting
DDIM sampling은 다음 formula를 따른다.
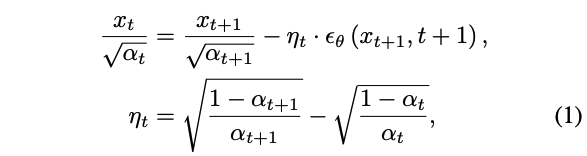
Sampling procedure가 deterministic하기 때문에, DDIM sampling process가 $t = 0$에서 $t = T$로 inverse하게 진행되면 original image의 initial noisy latent를 얻을 수 있다. Inversion process는 다음과 같다.

Discrete nature 때문에, 각 reconstruction time-step에 작은 error가 존재하고 이는 결점이 있는 reconstruction을 야기한다. 이 error는 다음과 같이 쓸 수 있다.
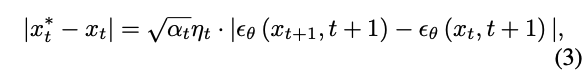
여기서 $x^*_t, x_t$는 reconstructed latent와 inverted latent이다. $\alpha_t$는 하이퍼파라미터이기 때문에, reconstruction error는 mismatch error $| \epsilon_\theta(x_{t+1}, t+1) - \epsilon_\theta(x_t, t+1) |$에 의해 결정된다. DDIM inversion과 reconstruction에서는 $\epsilon_\theta(x_{t+1},t+1) \approx \epsilon_\theta(x_t, t+1)$를 가정한다. 이러한 error는 time-step에 따라 쌓이고 이는 무시할 수 없게 된다. 결국, reconstruction의 trajectory는 inversion의 trajectory와 다르게 돼 reconstruction의 fidelity를 방해한다.
1.2 Multi-Branch DDIM Inversion
High-fidelity DDIM inversion의 key는 각 time-step에서 mismatch error를 최소화하는 것이다. 본 논문은 reconstruction fidelity를 강화하기 위해 multi branch DDIM inversion(MBDI)와 reconstruction을 구성함으로써 여러 trajectory를 ensemble하는 것을 제안한다.
구체적으로, 하나의 이미지를 inverting할 때, 임의의 수의 다른 이미지들이 샘플링되고 병렬적인 inversion과 reconstruction trajectory를 따른다. 각 time-step에서 각 branch를 독립적으로 inverting/reconstructing하는 대신에, 동시에 모든 branch를 invert/reconstruct해서 모든 branch들로부터의 noise prediction들의 ensemble을 만든다.

여기서 $\tilde{\boldsymbol{\lambda}} = [\tilde{\lambda}_1, \tilde{\lambda}_2, \cdots, \tilde{\lambda}_N] = [\frac{1}{N}, \frac{1}{N}, \cdots, \frac{1}{N}]$이고 $x^i_t$는 timestep $t$에서 $i$번째 branch의 latent이다. (1)과 (2)와 비교해서, 각 branch에서 latent는 $\epsilon_\theta(x_t, t+1), \epsilon_\theta(x_{t+1}, t+1)$대신에 $\epsilon^e_{\theta, \tilde{\boldsymbol{\lambda}}}(x_t, t+1), \epsilon^e_{\theta, \tilde{\boldsymbol{\lambda}}}(x_{t+1}, t+1)$을 가지고 invert되고 reconstruct된다. 이는 절차의 deterministic nature에 영향을 끼치지 않는다는 점에서 원래 이미지가 여전히 이론적으로 reconstruct될 수 있다.
MBDI reduces mismatch error
MBDI에서, inversion과 reconstruction에서 추정된 noise 사이의 mismatch error는 다음과 같다.

Triangle inequality에 따라, 위 식은 다음과 같다.

부등식의 우항은 각 독립적인 branch의 mean error이다. 이 term은 mismatch error의 기댓값 $\mathbb{E} \{ \epsilon_\theta(x_{t+1},t+1) - \epsilon_\theta(x_t, t+1) \}$에 대한 unbiased estimation이다. 이는 (3)에 비례하기에, multi-branch의 reconstruction error는 각 스텝에서 single branch의 것보다 기댓값상에서 크지 않다. 그러므로, multiple trajectories의 ensemble을 수행하는 것은 더 좋은 reconstruction result를 생성할 것이다.
1.3 Free-lunch DDIM inversion
N-branch inversion framework의 computation과 memory cost는 높고 이 비용은 standard DDIM inversion보다 대락 $N$배 이상이다. FreeInv에서는 효율성을 향상시키기 위해서 두 modification을 수행한다.
(1) One-time MC sampling at each time-step
(4)에서 deterministic $\tilde{\boldsymbol{\lambda}}$와 다르게, 본 논문은 random variable $\boldsymbol{\lambda}^t = [\lambda^t_1, \lambda^t_2, \cdots, \lambda^t_N] \sim \operatorname{Categorical}(\frac{1}{N}, \frac{1}{N}, \cdots, \frac{1}{N})$을 도입한다.
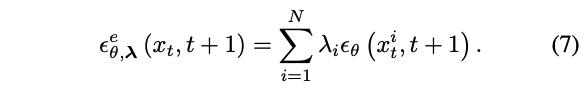
$\boldsymbol{\lambda}$에 대한 $\epsilon^e_{\theta,\boldsymbol{\lambda}}(x_t, t+1)$의 기댓값은 다음과 같이 쓸 수 있다.

이는 $\mathbb{E}_{\boldsymbol{\lambda}}[\epsilon^e_{\theta,\boldsymbol{\lambda}}(x_t, t+1)]$은 MBDI를 수행하는 것과 동일하는 것을 의미한다. 그러므로 $\mathbb{E}_{\boldsymbol{\lambda}}[\epsilon^e_{\theta,\boldsymbol{\lambda}}(x_t, t+1)]$를 계산하는 것이 key이다. 효율성을 위해, 각 inversion time-step에서 한 번의 MC sampling만 수행한다.

여기서 $\hat{\boldsymbol{\lambda}} = [\hat{\lambda}_1, \hat{\lambda}_2, \cdots, \hat{\lambda}_N]$는 $\boldsymbol{\lambda}$의 분포에서 샘플링된 one-hot vector이다. 그러므로, inversion의 각 time-step마다 하나 만의 branch가 sampling된다.
(2) Image transformation as a branch
앞선 방식에도 $N$개의 branch들의 latent representation를 유지하는 것이 필요되기 때문에, 여전히 memory cost는 여전히 높다. 효율성을 더 높이기 위해, multi-branch image sampling을 흉내내기 위해서 본 논문은 image/latent를 transform한다. (9)는 다음과 같이 표현될 수 있다.
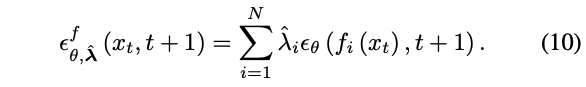
여기서 $f_i(\cdot)$은 $i$번째 branch를 함축적으로 표현하는 transformation을 나타낸다.
(1,2)를 따라, FreeInv의 inversion과 reconstruction은 다음과 같다.

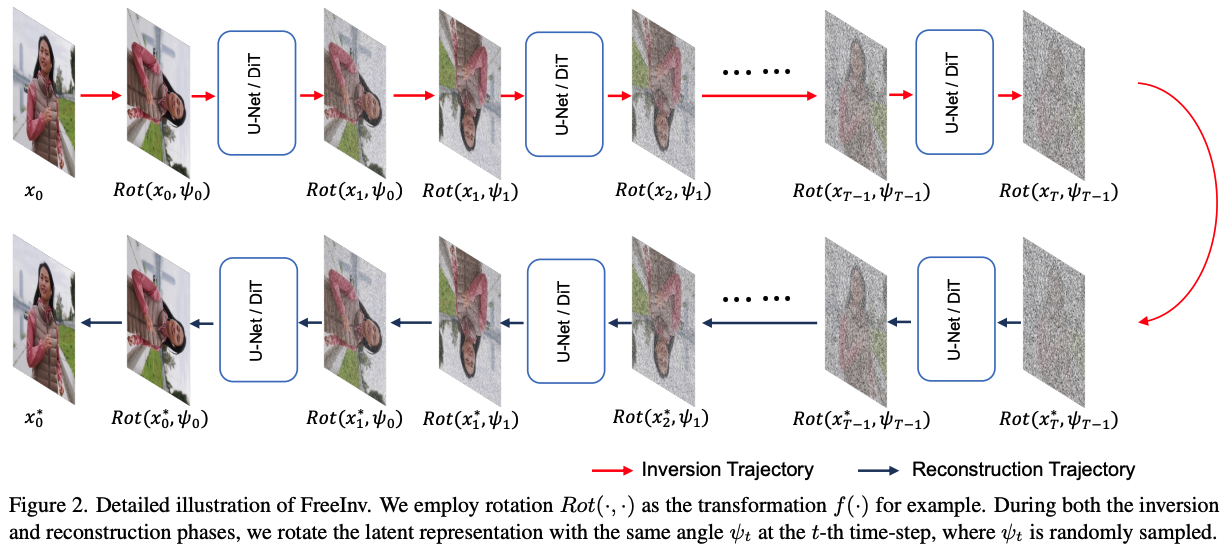
Fig 2는 transformation으로 rotation operation을 사용해 진행한 것을 나타낸 것이다. Inversion 과정 동안, 하나의 이미지에 대해 랜덤으로 선택한 각으로 각 time-step $t$에서 latent code $x_t$를 rotate해서 noise를 예측한다. Reconstruction process에 대해서, 유사한 operation을 적용한다. Consistency를 보장하기 위해, 각 timestep에서 inversion과 reconstruction사이에 동일한 rotation 각을 유지한다.
추가적인 computational consumption은 transformation과 transformation 종류를 저장할 memory로 제한된다. 이는 이전 방식들과 비교해서 무시할만하다.
FreeInv for image/video editing
FreeInv가 free-lunch manner으로 reconstruction 퀄리티를 향상시키기 때문에, 어떠한 존재하는 image/video editing 방식에도 결합될 수 있다.
2. Experiments
2.1 Image Editing
Quantitative Evaluation

Qualitative Comparison



2.2 Video Editing

2.3 Ablation Study
MC sampling vs MBDI

Transformation vs Multiple Images

Comparison between different types of transformations

Applicability to DiT

Cross-attention map visualization




