
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 논문리뷰
- 3d generation
- rectified flow matching models
- visiontransformer
- diffusion models
- Python
- flow models
- flow matching models
- diffusion
- VirtualTryON
- 코테
- memorization
- video editing
- video generation
- inversion
- ddim inversion
- BOJ
- rectified flow models
- 3d editing
- unlearning
- Concept Erasure
- image generation
- 프로그래머스
- Machine Unlearning
- 네이버 부스트캠프 ai tech 6기
- diffusion model
- rectified flow
- Programmers
- image editing
- flow matching
- Today
- Total
평범한 필기장
[평범한 대학원생이 하는 논문 간단 요약] Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models (CVPR 2025) 본문
[평범한 대학원생이 하는 논문 간단 요약] Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models (CVPR 2025)
junseok-rh 2025. 9. 21. 17:30Paper : https://arxiv.org/abs/2503.19783
Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
Existing unlearning algorithms in text-to-image generative models often fail to preserve the knowledge of semantically related concepts when removing specific target concepts: a challenge known as adjacency. To address this, we propose FADE (Fine grained A
arxiv.org
Abstract
기존 concept erasure method들은 target concept과 연관이 있는 concept들에도 영향을 끼치는 문제를 가진다. 본 논문에서는 FADE(Fine-grained Attenuation for Diffusion Erasure)을 제안해 이 문제를 해결하려 한다. FADE는 Concept Neighborhood와 Mesh Modules로 구성된다.

1. Fine-Grained Unlearning
본 논문은 LoRA를 이용한 방식으로 finetuning하는데, 이를 Mesh Modules이라고 본 논문에서는 부른다.
1.1 Problem Formulation
본 논문의 목적은 생성 모델에서 의미적으로 유사하거나 관련없는 concept들에 대한 성능은 유지하면서 target concept $c_{tar} \in \mathcal{C}$은 선택적으로 unlearning하는 것이다.
- $\mathcal{D} = \{ d_1, d_2, \cdots, d_N \}$ : concept들의 subset과 연관된 각 data point $d_i$의 dataset
- $\mathcal{C}$ : 모델 전체가 학습한 모든 concept들의 집합
- $\theta$ : Original Model Parameter
- $\theta^{\mathcal{U}}$ : Unlearning Model Parameter
- $\mathcal{A}(c_{tar})$ : $c_{tar}$과 연관된 concept들을 포함한 adjacency set
본 논문은 $c_{tar}$와 연관된 이미지를 생성 확률을 0에 가깝도록 하고($P_{\theta^\mathcal{U}}(y_{c_{tar}} \mid x) \to 0, \quad \forall x \in \mathcal{X}$), 인접한 concept들과 unrelated concepts들에 대한 모델의 performance를 유지하는 것을 목표로 한다.

1.2 FADE : Fine-grained Erasure

- $\mathcal{D}_u$ : target concept $c_{tar}$을 통해서 생성된 이미지로 구성된 unlearning set
- $\mathcal{D}_a$ : $c_{tar}$와 유사한 concept의 이미지들로 구성된 adjacency set
- $\mathcal{D}_r$ : 다양하과 관련없는 concept들의 이미지를로 구성된 retain set
$\mathcal{D}_a$는 Concept Neighborhood를 이용해서 구성한다.
Concept Neighborhood - Synthesizing Adjacency Set
$\mathcal{D}_a$는 구성하기 어렵기 때문에, Concept Neighborhood인 approximation $\mathcal{A}(c_{tar})$를 제안한다.
- $c_{tar}$을 포한한 각 concept들 $c \in \mathcal{C}$에 대해서, $\theta$로 이미지 set $\mathcal{I}_c = \{ x^c_1, x^2_2, \cdots, x^c_m \}$을 생성
- Pretrained image encoder $\phi : X \rightarrow \mathbb{R}^d$를 이용해서 각 이미지에 대한 embedding $\mathbf{f}^c_i = \phi(x^c_i)$를 계산
- 각 concept $c$에 대해서, mean feature vector $\bar{\mathbf{f}}^c = \frac{1}{N}\Sigma^N_{i=1}\mathbf{f}^c_i$를 계산하고 cosine similarity를 계산

위 similarity를 가지고 top-K concept들을 구한다. $\mathcal{A}(c_{tar}) = \{ c^{(1)},c^{(2)}, \cdots, c^{(K)} \}$
이 방식은 latent feature space 내에 내재된 fine-grained semantic relationships을 캡쳐함으로써 효율적으로 $\mathcal{A}(c_{tar})$를 구성한다. 본 논문에서는 이론적으로 Concept Neiborhood가 이론적으로 정당하다는 내용을 뒤에 설명하는데, 이는 생략하겠다.
Concept FADE-ing
FADE는 Erasing Loss, Guidance Loss, Adjacency Loss를 통해서, 주변 concept들에 대한 모델의 semantic integrity는 유지하면서 target concept $c_{tar}$을 mest $M$을 통해 선택적으로 unlearning한다.
1. Erasing Loss ($\mathcal{L}_{er}$)
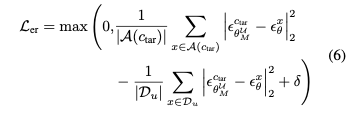
Target concept에 대한 noise prediction이 유사한 concept들에 대한 noise prediction에서 멀어지지 않게하면서, unlearning concept에 대한 noise prediction에서 멀어지도록 loss를 디자인했다.
2. Guidance Loss ($\mathcal{L}_{guid}$)

Guidance loss는 $c_{tar}$에 대한 noise prediction이 "null" concept으로 향하도록 디자인했다. $c_{tar}$을 null state로 향하게 함으로써, target concept의 영향을 효과적으로 nullify한다.
3. Adjacency Loss ($\mathcal{L}_{adj}$)
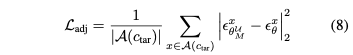
Adjacency loss는 updated model $M_{\theta^\mathcal{U}}$에서 adjacency set $\mathcal{A}(c_{tar})$의 concep들의 embedding을 유지하는 것으로써 regularization term 역할을 한다. 이 loss는 유사한 concept들이 보존되도록 디자인했다.
최종 loss term은 다음과 같다.
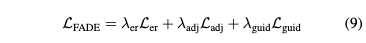
2. Experimental Details and Analysis
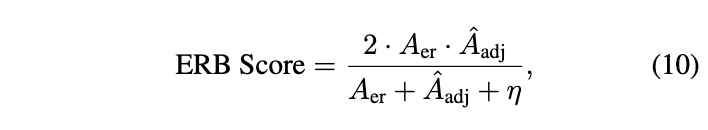
본 논문은 위 Erasing Retention Balance(ERB) Score를 도입한다. 이는 unlearning과 $\mathcal{A}(c_{tar})$에 대한 retention balance를 평가하는 harmonic mean을 제공한다.
- $A_{er}$ : Erasing Accuracy로 target concept의 erasure에 대한 정도를 측정
- $A_{adj}$ : Adjacency Accuracy로 $c \in \mathcal{A}(c_{tar})$에 대한 retention을 측정
- $\hat{\mathcal{A}}_{adj} = \frac{1}{\vert C \vert} \Sigma_{c \in C} A_{adj}$ : mean Adjacency Accuracy
2.1 Results of Fine-Grained Unlearning (FG-Un) Results


2.2 Coarse-Grained Unlearning (CG-Un) Results

Nudity Erasure in I2P
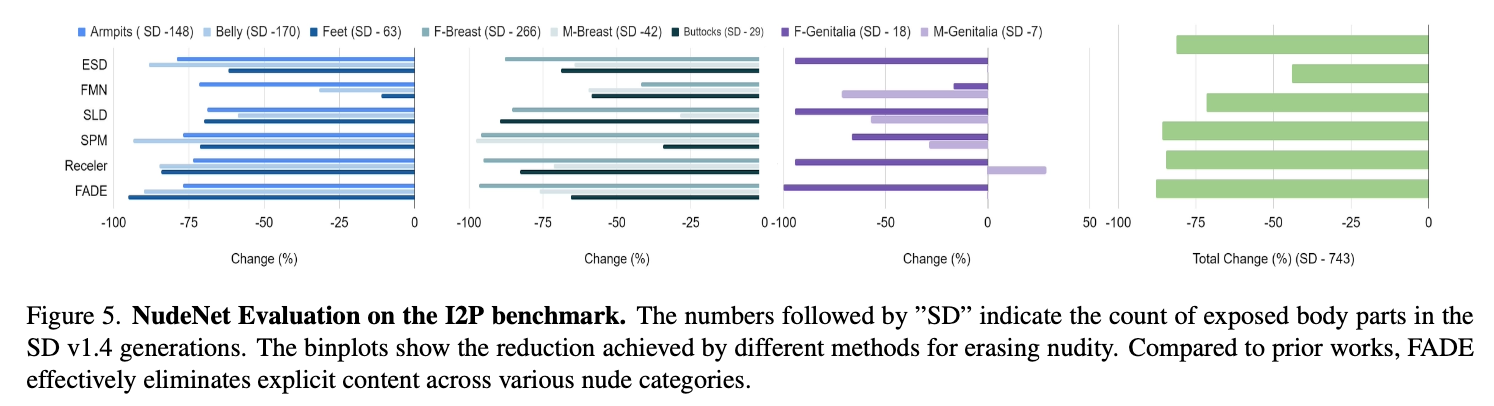

2.3 Ablation Study
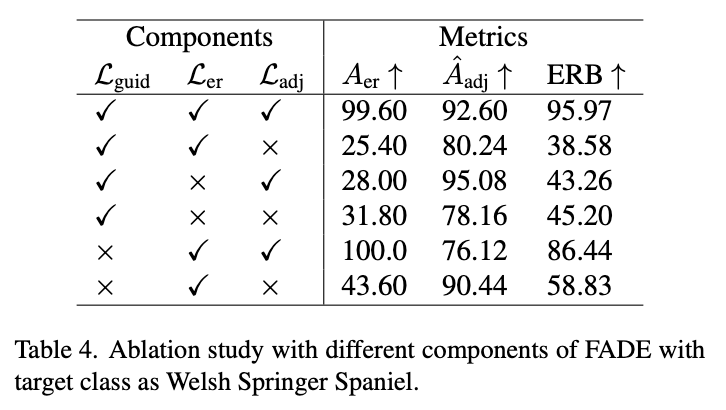
Take Away
- LoRA를 finetuning하는 방식이고, 3가지의 loss function을 통해 학습한다. Loss function들을 연구에 활용해봐도 좋을 듯?
- 유사한 concept들을 구하는 방식(Concept Neighborhood)가 인상적



