
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- flow matching
- diffusion model
- 3d generation
- inversion
- Programmers
- 코테
- video editing
- flow matching models
- VirtualTryON
- 3d editing
- 프로그래머스
- unlearning
- image generation
- memorization
- 논문리뷰
- rectified flow matching models
- Concept Erasure
- BOJ
- image editing
- diffusion models
- flow models
- ddim inversion
- video generation
- rectified flow models
- visiontransformer
- Python
- rectified flow
- Machine Unlearning
- 네이버 부스트캠프 ai tech 6기
- diffusion
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Stable Flow: Vital Layers for Training-Free Image Editing (CVPR 2025) 본문
[평범한 학부생이 하는 논문 리뷰] Stable Flow: Vital Layers for Training-Free Image Editing (CVPR 2025)
junseok-rh 2025. 7. 1. 00:55Paper : https://arxiv.org/abs/2411.14430
Stable Flow: Vital Layers for Training-Free Image Editing
Diffusion models have revolutionized the field of content synthesis and editing. Recent models have replaced the traditional UNet architecture with the Diffusion Transformer (DiT), and employed flow-matching for improved training and sampling. However, the
arxiv.org
Abstract
최근에는 UNet보다는 DiT를 많이 이용하고 또한 flow matching을 통해 성능을 높인 방식들이 많이 연구되고 있다. 하지만 이러한 연구들은 제한된 생성 다양성을 가진다. 본 논문은 attention feature의 선택적인 주입을 통해 consistent image editing을 수행하기 위해 이러한 limitation을 활용한다. DiT의 문제점은 UNet과 다르게 coarse-to-fine synthetic architecture가 부족한데, 이는 어떤 layer에 injection을 해야하는지 불명확하게 만든다. 본 논문은 DiT 내의 "vital layer"를 찾는 automatic method를 제안하고 이러한 layer들이 어떻게 다양한 image editing을 유용하게 만드는지 보인다. 또한 real-image editing을 위해서, flow model을 위한 improved image inversion을 도입한다.
1. Method
본 논문의 목적은 source image의 unedited region들은 충실히 보존하면서, text prompts에 대해 이미지를 editing하는 것이다. 본 논문은 FLUX model의 제한된 diversity를 활용하고 edited image $\hat{x}$를 생성하는 과정에 source image의 attention feature들을 선택적으로 주입하는 것을 통해 stable image editing을 가능하게 하도록 FLUX model을 제한한다.
1.1 Measuring the Importance of DiT Layers

기존 UNet을 사용한 것과 다르게, FLUX와 SD3과 같은 DiT model들에서 다른 layer들의 역할은 분명하지 않아서 어떤 layer가 image editing에 가장 적합한지 결정하기 어렵다.
FLUX model에서 layer importance를 측정하기 위해서, 본 논문은 systematic evaluation approach를 고안한다. 위 이미지처럼 모든 layer를 한번씩 bypassing해서 이미지를 생성하고, 그 이미지를 모든 layer를 사용해 생성된 이미지와 비교한다. Layer $\ell$의 vitality는 다음과 같이 계산한다.

여기서 $d$는 perceptual similarity이다. 이 때, DINOv2를 사용해 perceptual similarity를 계산한다. 각 layer에 대한 perceptual similarity는 다음과 같은데, 여기서 중요한 점은 영향력있는 layer는 특정 구역에 있는 것이 아니라 transformer 전반에 분포해 있다.

Vital layer들의 set $V$는 다음과 같이 정의된다.
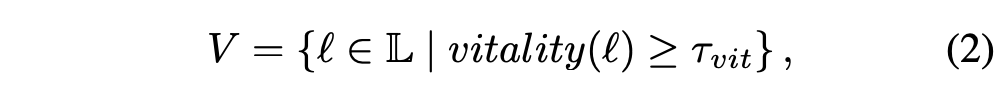

위 결과는 vital layer와 non-vital layer 사이의 정성적인 차이를 보여준다.
1.2 Image Editing using Vital Layers
본 논문은 기존에 UNet-based diffusion model에서 성공적으로 보인 self-attention injection mechanism을 DiT-based FLUX architecture에 적용한다. 각 DiT layer는 image와 text embedding의 sequence를 처리하기 때문에, vital layers set $V$에서만 $\hat{x}$의 image embedding을 $x$의 것으로 선택적으로 대체하면서 $x$와 $\hat{x}$를 벙렬적으로 생성하는 것을 제안한다.
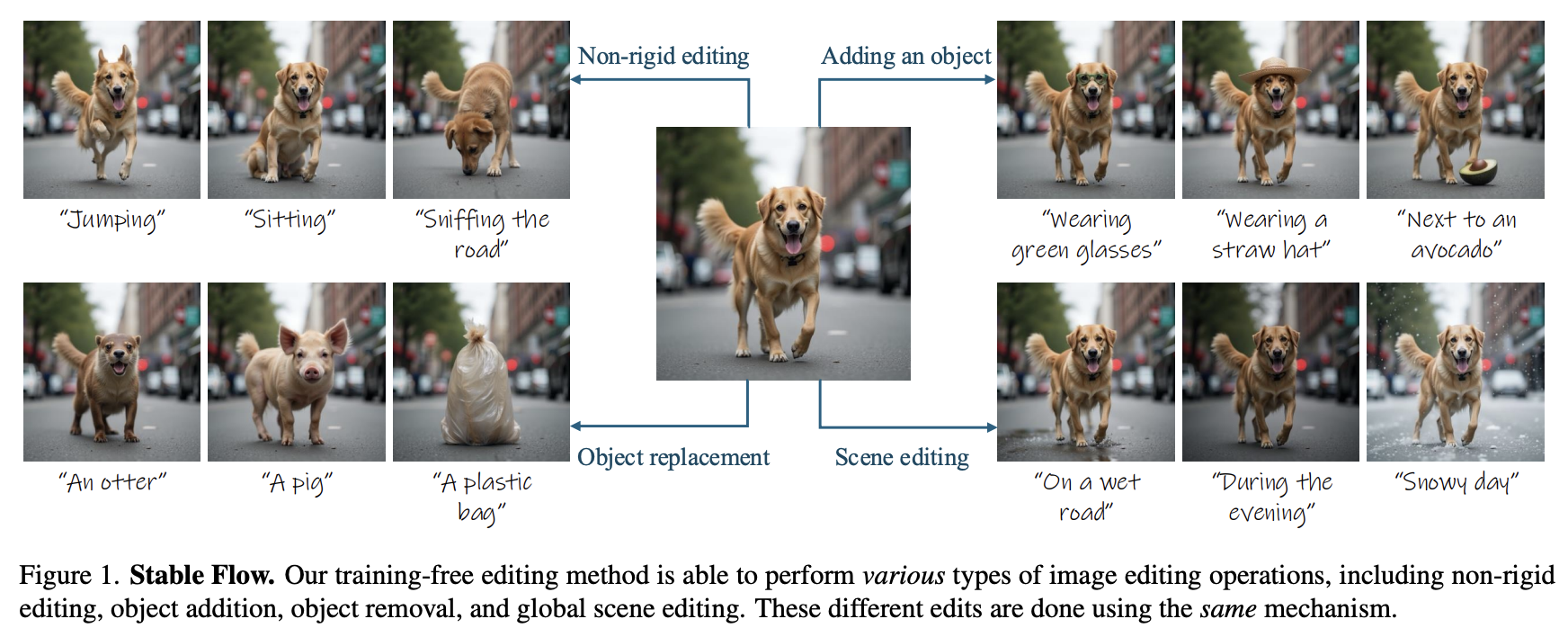
위 이미지의 결과는 동일한 set of vital layers $V$를 사용한 결과이다.
효과를 이해하기 위해서, 본 논문은 FLUX model에서 multimodal attention pattern을 분석한다. 모든 visual token들은 모든 visual and texn token들에 attend한다.

위 이미지는 vital과 non-vital layer사이의 attention pattern들을 두가지 key point에서 비교한다.
- Vital layer에서는, 변하지 않은 point들은 visual feature에대해 dominant attention을 보이고 editing을 위한 point들은 연관된 text token에 강한 attention을 보인다.
- Non-vital layer에서는, editing region에서도 image-based attention을 보인다.
이는 vital layer로 feature를 주입하는 것이 source content를 보존하는 것과 text edit을 통합하는 것 사이의 좋은 multimodal attention balance를 보여준다는 것을 시사한다.
1.3 Latent Nudging for Real Image Editing
Real image editing을 위해서는 real image들을 latent space로 변환시켜야한다. Forward Euler step이 다음과 같을 때,

inverse step은 다음과 같다.

여기서 $u_t(z_t) \approx u_t(z_{t-1})$를 가정한다.
하지만, 이는 corrupted image reconstruction과 unintended modification을 야기한다.

이를 해결하기 위해서, 본 논문은 latent nudging을 제안한다. 이는 initial latent $z_0$에 small scalar $\lambda = 1.15$를 곱해서 training 분포로부터 살짝 상쇄시킨다. 이는 시각적으로 구별할 수 없지만, reconstruction error를 상당히 줄이고 의도된 구역으로 editing을 제한한다.
2. Experiments
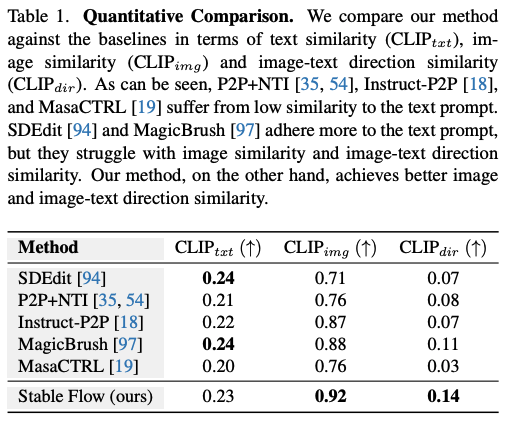
2.1 Qualitative and Quantitative Comparison

2.2 User Study

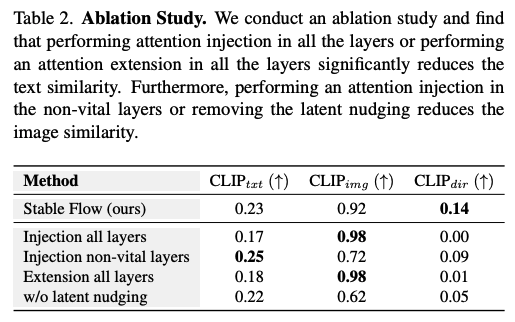
2.3 Ablation Study
2.4 Applications

3. Limitations




