
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- ddim inversion
- unlearning
- video editing
- diffusion models
- 3d editing
- rectified flow matching models
- BOJ
- rectified flow models
- Programmers
- image editing
- memorization
- 코테
- flow models
- 논문리뷰
- visiontransformer
- 네이버 부스트캠프 ai tech 6기
- 프로그래머스
- video generation
- inversion
- rectified flow
- diffusion
- flow matching
- Machine Unlearning
- Python
- Concept Erasure
- diffusion model
- flow matching models
- image generation
- VirtualTryON
- 3d generation
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation (ICCV 2025) 본문
[평범한 학부생이 하는 논문 리뷰] ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation (ICCV 2025)
junseok-rh 2025. 7. 6. 21:37Paper : https://arxiv.org/abs/2507.01496
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representa
arxiv.org
Abstract
본 논문은 multimodal transformer block들의 intermediate representations을 분석하고 3가지 key feature를 확인함으로써 ReFlow를 위한 새로운 real-image editing method를 제안한다.


1. Method
본 논문의 목표는 real image $\mathcal{I}$의 전체적인 구조는 유지하면서 target prompt $P_T$와 align되는 이미지를 생성하는 것이다.

1.1 Observations : three key features in MM-DiT
Two key features from the joint self-attention map
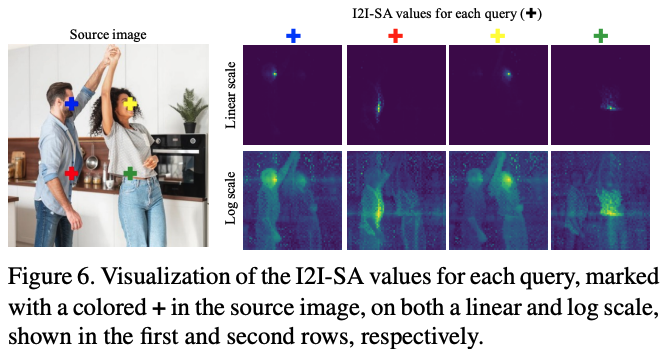
Reflow의 MM-DiT는 image와 text embedding을 함께 처리하는 joint self-attention을 사용한다. 본 논문은 joint self-attention map $Q \cdot K^T$를 I2I-SA, I2T-CA, T2I-CA, T2T-SA로 나눠서 생각한다.

위 결과를 보면, I2I-SA는 structural information을 encode하고, I2T-CA와 T2I-CA는 text-image relation을 capture한다. Editing을 해본 결과, I2I-SA와 I2T-CA를 주입하는 것이 target output에서 source image 구조를 보존한다.
- Attention의 output은 query dimension에 따라 합해지고, 이는 I2I-SA와 I2T-CA는 image token embedding에 직접적으로 영향을 미치고, T2T-SA와 T2I-CA는 text token embedding에 영향을 미친다.
- 마지막 layer로부터의 image token embedding만이 image decoder를 통과한다.
위 결과를 통해, 본 논문은 I2I-SA와 I2T-CA가 editing을 위한 key feature라는 것을 확인한다.
A key feature from residual connection
본 논문은 MM-DiT의 residual connection에서 두 가지 feature인 residual과 identity feature를 분석한다. $\text{MM-DiT}(x) = f(x) + x$로 나타낼 수 있는데, 여기서 image token embedding이 structure preservation에 중요하기 때문에 residual feature를 $f(x)_{image}$로 identity feature를 $x_{image}$로 정의한다. Fig. 4(b)의 결과를 보면, 두 feature 모두 구조적인 정보를 capture하지만, identity feature가 과도한 appearance detail을 유지하는 것을 보인다. 그래서, 본 논문은 residual feature를 key feature라는 것을 확인한다.
1.2 Mid-step feature extraction
추출된 feature가 source image와 관련이 없을 수 있기 때문에, early step에서 feature를 주입하는 것은 editing result를 안좋게 할 수 있다. 이는 ReFlow model들이 inverted latent로부터 이미지를 reconstruction하는 것을 잘 못하기 때문이다.

위 결과를 보면 early step에서의 latent로부터 reconstruction을 하면 결과가 안 좋은 것을 볼 수 있고, mid-step에서의 결과가 optimal한 것을 볼 수 있다. 그래서 본 논문은 mid-step feature extraction을 제안한다.
1.3 Two feature adaptation techniques
본 논문의 main idea는 mid-step latent $z_{t^\prime}$에서 3가지 key feature들을 뽑고 target image generation의 이른 timestep동안 그들을 주입하는 것이다. 그런데 feature를 뽑는 timestep과 그 feature를 주입하는 timestep이 다르기 때문에 고려할 것이 필요하다. 이 문제를 해결하기 위해, source와 target information의 밸런스를 맞추기 위해서 두 가지 feature adaptation technique를 도입한다.
I2T-CA adapation
본 논문은 target prompt로부터의 text token index를 받아서 source prompt에서 대응되는 text token index를 return하는 mapping function $f$를 정의한다. 만약 대응되는 token이 없으면 $\emptyset$을 return한다. 각 target text token index $i$에 대해서, $f$를 이용해서 다음과 이 adapted I2T-CA를 계산한다.

Target image generation동안 $CA_S$ 대신에 $CA^\prime$을 주입한다. Source prompt가 주어지지 않거나 target prompt와 문장 구조가 다르면, 모든 $i$에 대해서 $f(i) = \emptyset$로 정의한다.
I2I-SA adapation
I2I-SA를 변형 없이 주입하면 target prompt가 구조적인 변화를 많이 줄 때 안 좋은 editing 결과를 야기한다고 한다.
본 논문은 source의 I2I-SA에서 과도하게 집중된 top-k attention value를 target의 I2I-SA에 대응되는 value들로 대체하는 것을 제안한다. 이 방식은 source image의 전체적인 구조는 유지하면서 과도하게 local 구조를 유지하는 것으로부터 source injection을 막는다. 이는 다음과 같이 나타낸다.
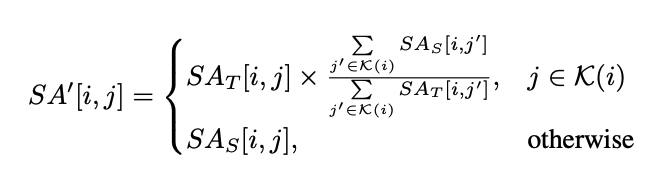
$\mathcal{K}(i)$는 $SA_S$에서 $i$번째 행에서 top-k attention value를 가지는 인덱스의 집합을 나타낸다. 본 논문은 target image generation동안 $SA_S$대신에 $SA^\prime$을 주입한다.
1.4 Mask generation for latent blending
이미지의 특정 구역에서 수정을 제한할 때, source prompt가 주어지면 작동하는 mask generation process를 제안한다. 먼저 editing을 하려는 subject인 blended word가 주어지면, 본 논문은 blended word의 I2T-CA를 추출하고 Gaussian smoothing을 적용하고 Otsu's thresholding method를 사용해서 target image generation의 첫 $m$ timestep에 대한 binary mask $M_t$를 생성한다. 이 mask는 $z^{blend}_t = M_t \odot z_t + (1-M_t) \odot z^{source}_t$를 통해 blended latent $z^{blend}_t$를 계산하는데 사용된다. $z_t$를 사용하는 대신, target image generation의 첫 $m$ timestep동안 ReFlow iteration에서 $z^{blend}_t$를 사용한다.
2. Experiments
Source prompt가 주어질 때는, I2T-CA를 초기 $0.4T$ step동안, I2I-SA를 $0.25T$동안, residual feature를 $0.15T$동안 주입한다. Source prompt가 주어지지 않을 때는, I2T-CA는 주입하지 않고 I2I-SA를 $0.4T$동안 residual feature를 $0.25T$동안 주입한다.
2.1 Qualitative evaluation

2.2 Quantative evaluation
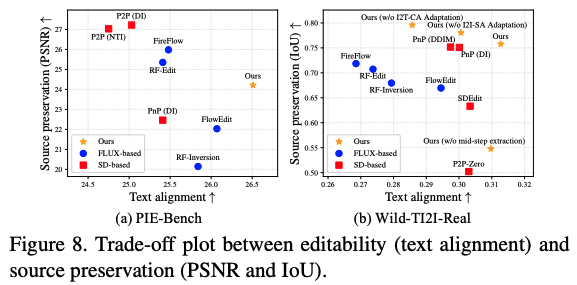
2.3 User study

2.4 Ablations
Role of key techniques

Effect of varying $t^\prime$ in mid-step feature extraction

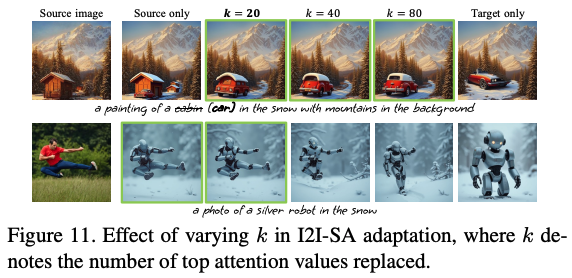
Effect of varying $k$ in I2I-SA adaptation
Effect of varying $\alpha$ in I2T-CA adaptation

3. Limitations

(a) Editing돼야하는 subject가 다른 subject와 겹쳐있으면 겹친 subject도 변화가 나타난다.
(b) I2T-CA를 통해 생성된 editing mask는 editing region을 완벽하게 localize하지 못한다.



