
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Machine Unlearning
- rectified flow matching models
- BOJ
- diffusion
- video generation
- diffusion model
- image generation
- flow matching models
- memorization
- image editing
- rectified flow models
- VirtualTryON
- video editing
- flow models
- Concept Erasure
- unlearning
- diffusion models
- 코테
- Python
- 3d generation
- inversion
- rectified flow
- ddim inversion
- visiontransformer
- Programmers
- 네이버 부스트캠프 ai tech 6기
- 3d editing
- flow matching
- 프로그래머스
- 논문리뷰
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers (ICML 2025) 본문
[평범한 학부생이 하는 논문 리뷰] EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers (ICML 2025)
junseok-rh 2025. 7. 16. 11:18Paper : https://arxiv.org/abs/2412.20413
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3
arxiv.org

0. Obstacles in migrating concept erasure methods to Flux
본 논문은 T5의 sentence-level embeddings와 명백한 cross-attention의 부재, keyword obfuscation을 다루는데 포함된 복잡성에 의한 기존 SD에서의 concept erasure methods가 Flux에 적용되지 않는 limitation에 대해 논의한다.
Erasing method evaluation
기존 SD에 적용된 erasing method들인 ESD, UCE, MACE는 cross attention layer를 최적화하는데, 명백한 cross attention layer가 존재하지 않는 Flux에는 적용할 수 없다. 적용하게 되면 concept이 불완전하게 지워지는 concept residue가 나타난다. 이는 Flux에 적용할 수 있는 새로운 방식이 필요하다는 것을 나타낸다.
Irrelevant prompt preservation
Irrelevant prompt preservation technique인 EAP와 Real-Era를 사용하는 것에는 CLIP을 사용하는 SD와 T5를 사용하는 Flux의 차이 때문에 문제가 발생한다. Word-level embedding과 유사도 측정에 적합한 CLIP과 다르게 T5는 sentence-level embeddings을 위해 디자인돼, T5의 word-level embedding은 word similarity를 효과적으로 capture하지 못한다. 이는 Flux에서 irrelevant prompt preservataion을 구현하는 것을 덜 적합하게 만든다.

또한 다른 문제로는 T5 embedding의 size이다. 이는 vocabulary로부터 adversarial prompts의 adaptive selection을 computationally intesive하고 time consuming하게 만든다.
Cross attention
Flux에는 cross attention이 존재하지 않지만, 본 논문은 Flux에도 text embedding과 attention maps 사이의 linear relationship이 존재한다는 것을 보인다.
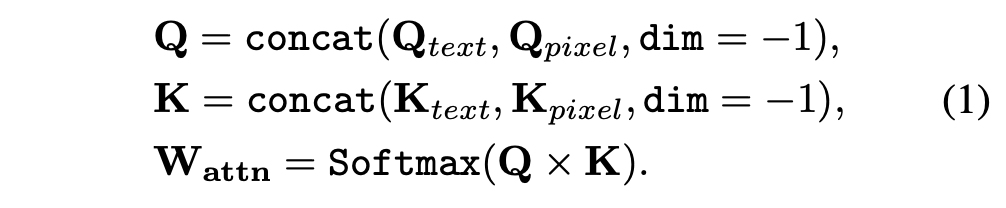
본 논문은 text와 image사이의 연관성이 $W_{attn}$안에 내재적으로 구성된다는 것을 발견한다. Prompt안에 target word의 token index를 정확히 찾음으로써, prompt-specific characteristic들을 정확하게 정의할 수 있다. $W_{attn}$의 관련된 column을 0으로 바꿈으로써 이를 할 수 있고, 이를 통해 정확하게 내재된 feature를 설명할 수 있다.
So far, Not so good

$W_{attn}$에서 대응되는 index column을 지움으로써 간단하게 target concept을 지울 수 있다. 하지만 이 방식은 기초적인 prompt attack strategy들에 대해서 비효율적이다.
1. Method
본 논문은 removal과 preservation 사이의 미세한 밸런스를 bi-level optimization strategy를 통해 해결한다. Low-level은 robust concept erasure를 강화하도록 디자인되고, upper-level은 irrelevant concept의 유지를 보장한다.
1.1 Bi-Level Finetuning Framework
Lower-Level Problem : Concept Erasure
Lower-level optimization phase에서, 본 논문은 unlearned dataset $D_{un}$에 대해 LoRa를 통해 Flux의 finetunable parameter들을 refine한다.
Lower-level optimization에서 첫번째 sub-loss function은 다음과 같다.

- $\eta$ : negative guidance factor로 concept erasure의 정도에 상당한 영향을 준다.
- $\Delta \theta$ : concept erasure를 위한 learnable LoRA weights
- $c_{un} \in D_{un}$ : erasure를 위한 특정한 concepts
본 논문은 전체 input prompt안에 keywords에 할당된 attention weight을 약화함으로써 erased concepts의 activation을 약화시키려한다.
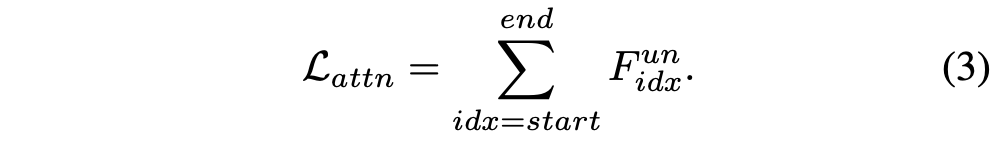
민감한 단어들의 고정된 index 위치가 overfitting을 야기할 수 있기 때문에, 본 논문은 suboptimal results를 직면했다. 이를 해결하기 위해서, 문장의 순서를 섞음으로써 index 위치를 dynamic하게 한다. 이는 Flux가 랜덤으로 섞인 문장으로 비슷한 content를 생성할 수 있기 때문에 일리 있는 방식이다.
Upper-Level Problem : Irrelevant Concept Preservation
본 논문은 고전된 $c$와 random seed로부터 6-10개의 이미지 $I_f$를 생성하고 image generation process에서 shift를 유도하기 위해서 LoRA를 학습한다.

- $v = x_T - u_{pix}$, where $x_T \sim \mathcal{N}(0,I)$
- $u_{pix}$ : $I_f$로부터의 이미지를 VAE로 encoding한 latent code
- $u_t = (1-t)u_{pix} + tx_T$
더 넓은 범위의 irrelevant concepts을 위해서 이 간단한 학습 레시피는 부족하다. 이미지들의 컬렉션과 그에 대응되는 irrelevant concepts에 대한 prompt list를 통합하는 것은 모호하고, T5 feature는 word-level similarity를 측정하기에 충분치 않다.
이를 해결하기 위해서, keyword의 attention map에 기초한 contrastive learning approach를 제안한다. 본 논문은 erasure를 위한 target concept과 irrelevant한 $D_{ir}$를 생성하기 위해서 LLM을 사용한다. 먼저 GPT-4o를 이용해서 $c_{ir} \in D_{in}$을 샘플링한다. 그리고 NLTK를 이용해서 지우려고 하는 concept의 synonym("nude"에 대해서는 "nake")을 생성한다. $x_T$를 고정하고 "nude"를 "nake"로 대체하고 $c$에 $c_{ir}^i, \ i = \{1,2,3\}$를 넣어서 개별적오르 denosing process를 진행한다. 정확한 concept-related activation을 위해서 higher timesteps에서 attention map을 고른다.
본 논문의 목표는 central feature $F^{un}$을 dynamically shifting $F^{ir}$으로 align하면서, synonym feature $F^{syn}$으로부터 멀리 떨어지도록 하는 것이다. 이를 위해서 Reverse Self Contrastive loss (RSC)를 제안한다.

실험을 통해 $\tau = 0.07$을 설정한다.
Bi-Level Optimization
Bi-level optimization은 다음 수식으로 나타내진다.

Algorithm

2. Experiments
2.1 Results
Nudity Erasure

Miscellaneousness Erasure



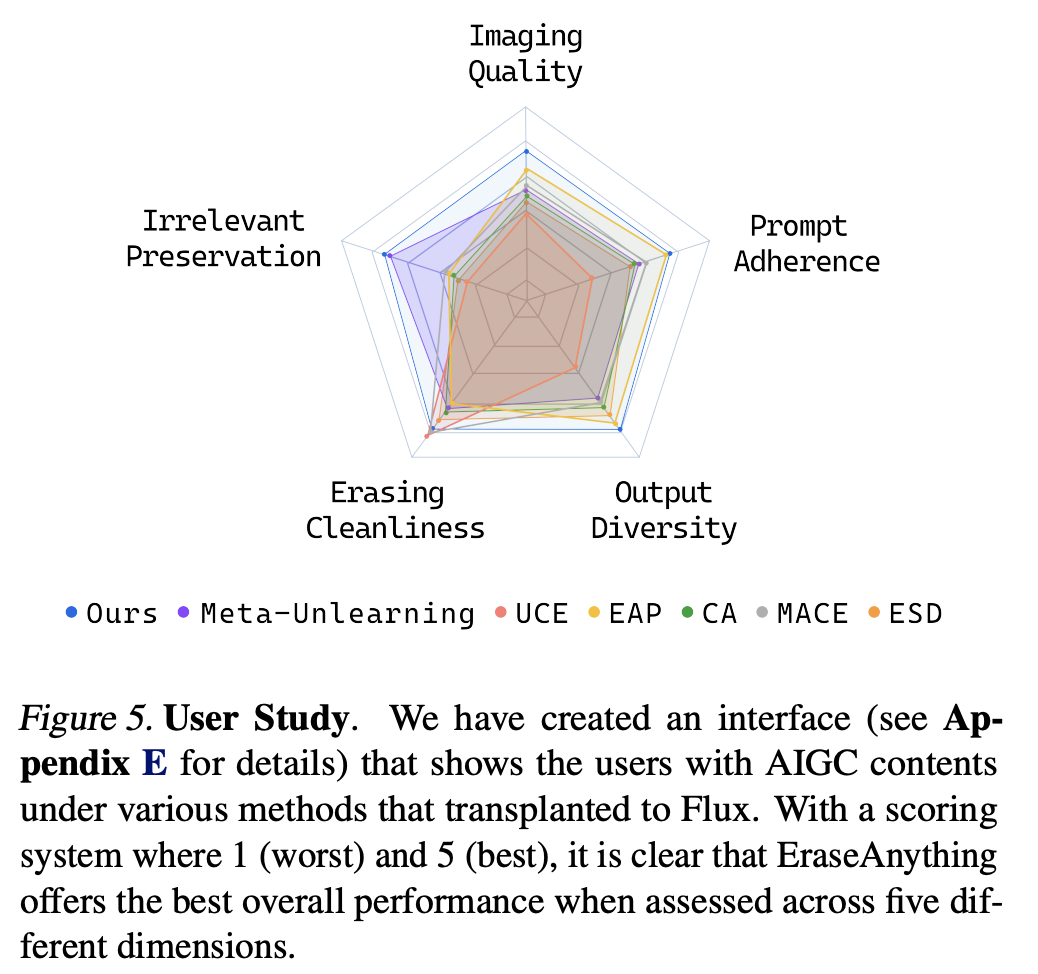
User Study
2.2 Ablation study

3. Limitations
Extensive Concept Erasure
10개 이상의 컨셉을 지우는 경우 각각의 concept의 erasure의 영향이 비례하게 줄어든다.
Fine-grained Control
Erasure의 강도를 보장할 수 없다는 문제가 존재한다.



