
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- video editing
- rectified flow matching models
- Concept Erasure
- image generation
- unlearning
- Machine Unlearning
- 3d generation
- Programmers
- rectified flow models
- memorization
- VirtualTryON
- video generation
- 네이버 부스트캠프 ai tech 6기
- 코테
- image editing
- Python
- diffusion models
- inversion
- 논문리뷰
- flow matching
- rectified flow
- BOJ
- visiontransformer
- 프로그래머스
- diffusion
- diffusion model
- 3d editing
- flow matching models
- ddim inversion
- flow models
- Today
- Total
평범한 필기장
[평범한 대학원생이 하는 논문 간단 요약] LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers (NeurIPS 2025) 본문
[평범한 대학원생이 하는 논문 간단 요약] LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers (NeurIPS 2025)
junseok-rh 2025. 10. 9. 02:30Paper : https://arxiv.org/abs/2505.23758
LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers
We introduce LoRAShop, the first framework for multi-concept image editing with LoRA models. LoRAShop builds on a key observation about the feature interaction patterns inside Flux-style diffusion transformers: concept-specific transformer features activat
arxiv.org
Abstract
본 논문은 LoRA를 이용한 multi-concept image editing을 위한 첫 framework LoRAShop을 제안한다.

1. Method
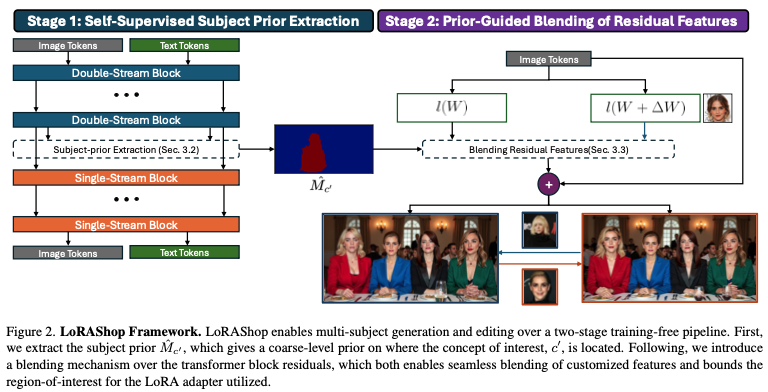
1.1 Self-Supervised Subject Prior Extraction
여러 adapter들을 joint하게 finetuning하면 각 컨셉끼리의 개입이나 distribution drift가 발생한다. 본 논문은 이를 해결하기 위해서, 먼저 latent space에서 각 personalized subject들이 어디에 나타나는지 예측하고 그 subject에 할당된 픽셀들에 각 adapter들의 영향을 제한한다. 이러한 구역을 제한하는 binary mask를 subject prior라고 부른다. 이 subject prior는 한번의 timestep $\gamma$까지의 pseudo-denoising을 통해서 추출된다. 마지막 double-stream block으로부터의 map은 sharpest separation을 제공한다. 하나의 subject인 token subset $c^\prime$에 대해서 다음과 같이 attention을 계산한다.

Raw attention은 특정 keyword에 대해서 흩뿌려진 형태로 나타나기 때문에, 본 논문은 $3 \times 3$ Gaussian kernel을 통해서 $M_{c^\prime}$을 반복적으로 blurring하고 super-threshold area가 하나의 연결된 요소를 형성할 때까지 renormalize한다. 상위 $\tau$%의 값들로 tresholding하는 것은 최종 binary mask를 생성하고 $\hat{M}_{c^\prime}$이라고 한다.
여러 subject들이 존재할 때, 이러한 마스크들이 겹치는 부분이 발생하는데, 이를 본 논문에서는 "LoRA cross-talk"라고 한다. Non-overlapping map을 얻기 위해서, 본 논문은 smoothed attention map $\{ \tilde{M}_u \}^M_{u=1}$을 쌓고 모든 위치 $(i,j)$에서 가장 강력한 반응을 가진 subject $u$를 결정한다.
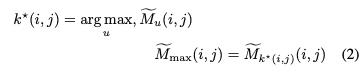
최종적으로는 one-hot prior를 정의한다.

Mask 집합 $\hat{M}_u$은 overlap없이 latent canvas를 나누고 adapter mixing을 위한 spatial guide 역할을 한다.
1.2 Prior-Guided Blending of Residual Features
전체적인 diffusion transformer는 원래와 같이 처리되지만, 본 논문은 subject prior가 활성화되는 곳마다 residual feature tensor(residual connection이 존재하는 모든 layer에서의 residual feature $\mathbf{F}^{base}_{l,r}$)들을 overwrite한다.
각 token position $p$에 대해 본 논문은 prior들을 weight로 바꾼다. 그래서 weight들은 subject token에 대해서는 더해서 1이 되거나 background token들에 대해서는 0이 된다.
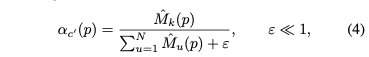
어떤 block에서든 간에, 본 논문은 image token들만 섞고, prompt token들은 기존 backbone residual들을 그대로 유지한다. Image token $p$와 모든 residual index $r$에 대해서 다음 값으로 대체한다.

만약 token $p$에 subject가 없다면 ($\Sigma_u \hat{M}_u(p) = 0$), $\mathbf{F}^{base}_{l,r}(p)$를 그대로 둔다. 이 blending과정은 첫 timestep $t$까지는 적용할 수 없다. 전체적은 layout이 생성되고 그 후에 적용한다. 본 논문은 weight를 바꾸는 대신 모든 layer의 residual output을 섞기 때문에, 그에 대한 prior에 의해 정확하게 선택된 token들에 영향을 끼친다.
1.3 Editing with LoRAShop
LoRAShop은 noise schedule과 어떤 model weight도 건들지 않는다. 이 operation이 local하고 linear하기 때문에, global denoising trajectory와 전체적인 scene layout은 그대로이다. 그래서 본 논문은 RF-Solver의 방식을 통해서 image를 reconstruction하는 latent noise를 찾고, 이를 통해 real image editing을 진행한다.

2. Experiments
2.1 Qualitative Results


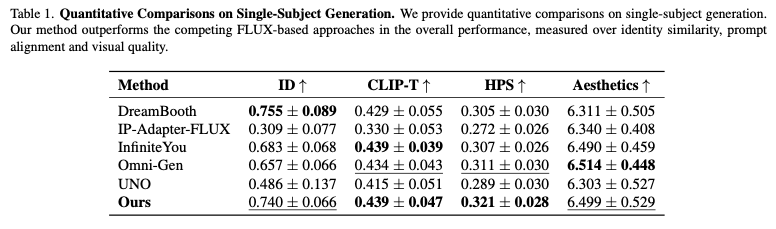
2.2 Quantitative Results
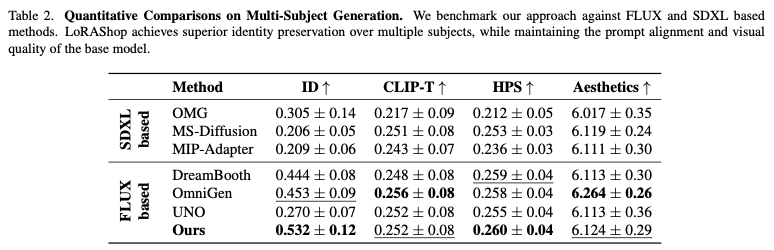
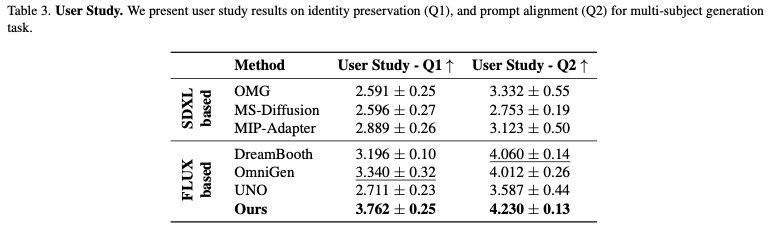

2.3 Ablation Studies


TakeAway
- Attention map으로 mask를 생성해서 그 mask에 해당하는 subject에 대한 LoRA의 feature로 기존 layer의 residual feature를 대체하는 방식은 내 연구에도 고려해볼만 하다
- Flux에서 Dual Stream의 마지막 block의 map을 사용!
- Attention map으로 mask를 생성하다보니 스타일같은 것들은 못지울 것 같은 느낌...



