
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- ddim inversion
- 논문리뷰
- VirtualTryON
- diffusion models
- rectified flow models
- image generation
- Python
- 네이버 부스트캠프 ai tech 6기
- Programmers
- 3d editing
- unlearning
- Machine Unlearning
- BOJ
- memorization
- video generation
- flow matching
- diffusion
- Concept Erasure
- 코테
- visiontransformer
- flow matching models
- video editing
- diffusion model
- rectified flow matching models
- 3d generation
- 프로그래머스
- image editing
- flow models
- inversion
- rectified flow
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix) 본문
[평범한 학부생이 하는 논문 리뷰] Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix)
junseok-rh 2023. 4. 3. 00:33GAN, DCGAN을 읽고 나서 이번에는 Conditional GAN에 관한 논문을 읽어 봐야겠다라는 생각이 들기도 했고, 스터디에서도 이 논문을 읽을 차례가 돼서 이번엔 Image-to-Image Translation with Conditional Adversarial Networks를 정리할 겸 리뷰하려한다.
원본 논문 링크 : https://arxiv.org/abs/1611.07004
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org
이 논문은 image to image translation을 위해 GAN모델을 이용하려한다. 그렇기에 GAN모델을 공부한 후에 이 글을 읽는 것을 추천한다.
이 논문에서 말하는 conditional GAN(cGAN) 모델은 Pix2Pix라 불리는 cGAN의 한 유형이라고 보면 된다.
Pix2Pix모델을 설명하기 전에 간단하게 conditional GAN에 대해 간단하게 설명하겠다.
Conditional GAN
Conditional GAN이란 데이터의 모드를 제어할 수 있도록 GAN 모델에 조건 정보를 추가해준 모델이라고 볼 수 있다.
cGAN의 Objective Function은 아래와 같다.


GAN의 objective function과 비교해보면 거의 동일하지만 y라는 조건이 추가된 것을 볼 수 있다.
cGAN은 label과 같은 조건이 주어지면 label에 맞는 데이터를 생성해준다.
아래의 이미지는 나동빈님이 하신 논문 리뷰에서 가져온 이미지이다.
GitHub - ndb796/Deep-Learning-Paper-Review-and-Practice: 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
꼼꼼한 딥러닝 논문 리뷰와 코드 실습. Contribute to ndb796/Deep-Learning-Paper-Review-and-Practice development by creating an account on GitHub.
github.com

위 이미지에서 볼 수 있듯이 MNIST 데이터로 한 실험에서 label이란 조건이 주어지면 label에 맞는 이미지를 생성하는 것을 볼 수 있다.
이 논문 이전에도 GAN에 conditional한 형태를 모델에 적용한 것이 많지만 그 모델은 특정 경우에만 적용할 수 있는 모델이였다고 한다. (application-specific)
이러한 점을 개선해서 image to image translation에서 일반적으로 사용할 수 있는 프레임워크인 Pix2Pix 모델을 이 논문에서 소개한다.
Contribution
Pix2Pix 모델은 2가지 기여점이 있다고 소개한다.
- 다양한 task에서 적용 가능한 일반적인 모델.
앞서 말한 기존의 cGAN은 application-specific했다. 그래서 task마다 parameter를 조정하거나 다른 loss function을 써야했다. 하지만 Pix2Pix 모델은 그럴 필요 없이 다양한 task에서 사용가능하다.
- 간단한 프레임워크로 좋은 결과를 얻을 수 있고, 몇 개의 중요한 구조적 선택을 분석하는데 기여.
Method
cGAN은 조건부로 label과 같은 것들을 입력으로 받지만, Pix2Pix 모델은 이미지 자체를 조건부로 입력받아 다른 이미지를 생성한다는 특징을 가진다.

1. Objective
아래의 필기는 논문에 나온 objective를 그대로 쓴 것이다. 아래와 같이 기존의 cGAN objective에서 L1 term을 추가해줬는데, 그 이유로는 cGAN objective만으로는 현실적인 이미지는 생성할 수 있겠지만, 정답과 가까운 이미지를 생성하지 못하기 때문에 그러한 이미지를 생성하기 위해 L1 term을 추가해줬다고 한다. (L2가 아닌 L1을 추가한 이유로는 L1이 덜 blurry한 이미지를 생성하기 때문이라고 한다.)

여기서 일반적인 GAN과 다르게 노이즈 z를 없애줬는데, 이 논문에서의 주 목적은 다양한 이미지를 생성하는 것이 아니고 조건 이미지인 x에 맞게 이미지를 생성하는 것이 주 목적이기 때문에 노이즈 z를 빼서 deterministic한 결과를 생성하게 했다.
아래 이미지는 loss에 따라 이미지가 어떻게 생성되는지를 보여주는 이미지이다. L1 loss만 이용했을 경우에는 대강의 형태는 잘 생성했지만, 매우 blurry한 것을 볼 수 있다. 그리고 cGAN loss만 이용할 경우 훨씬 sharp 이미지이지만 특정 부분에서 artifact한 것이 생성되는 것을 볼 수 있다. (cGAN의 마지막 이미지에서 집 지붕에 이상한 것이 생성됨.) 두 loss를 다 이용하면 이러한 artifact한 부분이 줄어든 것을 확인할 수 있다.

그리고 아래의 표는 여러가지의 loss를 통해 생성한 이미지들의 FCN score를 측정한 결과를 표로 나타낸 것이다. L1 + cGAN의 경우가 점수가 제일 높은 것을 볼 수 있다. 게다가 GAN 과 cGAN을 비교해보면 차이가 많이 나는 것을 볼 수 있는데, 그 이유로는 GAN은 Input 이미지와 output 이미지의 mismatch 에대해 penalize 하기보단 realistic한 이미지를 다양하게 생성한다. 하지만 image to image translation에서는 이미지가 주어졌을 때 그에 맞게 이미지를 생성하는 것이 중요하기 때문에 GAN loss가 이러한 task에서는 적절하지 않은 것을 알 수가 있는 실험이다.
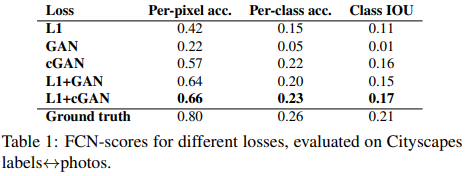
- FCN score : 실제 이미지들로 pre-train된 semantic classifier들을 이용해 생성된 이미지들을 얼마나 잘 분류하는지를 점수화. (생성된 이미지가 실제와 거의 유사하다면 classifier가 실제 이미지로 분류할 것이다.)
또한 cGAN loss는 colorfulness에 기여한다. L1 loss는 픽셀에 어떤 색을 채울지 모를 때 grayish color를 넣으려한다. 정답에 가깝게 하기위해 정답을 모를 때는 평균인 grayish color를 넣으려 한다는 뜻인 것 같다. 그렇지만 그러한 색은 realistic하지 않기 때문에 cGAN의 loss를 높이기 때문에 cGAN loss에 의해 true color distribution을 match한다.
2. Network Architectures
Pix2Pix 모델에서 나타나는 구조적 특징 2가지가 있는데, 하나는 Generator에서 U-Net을 사용한 것이고, 다른 하나는 Discriminator에서 PatchGAN을 사용한 것이다.
2.1 U-Net

위 이미지를 보면 encoder-decoder와 u-net을 볼 수 있다. 여기서 두 네트위크의 차이는 바로 skip connection이다. Image to image translation을 잘 하기 위해서는 Input이 가지는 정보를 Output도 가져야한다. 그렇기 때문에 encoder-decoder에서 앞단이 추출한 정보(representation, feature)들을 뒷단으로 넘겨주는 skip connection을 넣으면 성능이 더 좋아진다. 그렇기 때문에 skip connection을 가진 U-Net의 구조를 Generator에 사용한다고 한다.
(U-Net은 자세하게 공부해서 따로 글을 써볼까 생각중입니다,,,ㅎ)
아래 이미지를 보면 endcoder-decoder를 이용할 때보다, U-Net을 이용할 때 생성된 이미지의 퀄리티가 좋은 것을 볼 수 있다. loss를 L1만 사용할 때, L1 + cGAN을 사용할 때 둘다 더 현실적으로 이미지를 생성한 것을 볼 수 있다.

2.2 PatchGAN
위에 나온 objective를 보면 cGAN term과 L1 tern으로 되어있는 것을 확인했다. L1 loss는 low-frequency를 capture한다. 이미지에서 low-frequency는 픽셀 값의 변화가 적은 부분이다. 이미지 내에서 사물의 경계는 픽셀의 변화가 크기 때문에 high-frequency인데 이러한 것들은 L1 loss가 잘 잡아내지 못하므로 cGAN loss가 그러한 부분을 잘 잡도록 프레임워크를 디자인하면 된다. 그런데 이러한 경계를 잡는데에는 이미지 전체를 학습할 필요가 없다. 그렇기에 Pix2Pix 모델은 discriminator로 PatchGAN을 이용했다고 한다.
논문에서 PixelGAN, PatchGAN, ImageGAN 이렇게 3 종류의 GAN을 이용해 실험을 진행했다. 각 모델을 이용해 생성한 이미지들이고 아래의 표는 생성된 이미지들을 통해 계산한 FCN score을 정리한 표이다.


70*70 patch를 이용한 PatchGAN을 이용할 때 점수가 제일 높은 것을 확인할 수 있다. ImageGAN과 PatchGAN의 차이점은 이미지를 판별할 때 ImageGAN은 이미지 전체를 보고 이미지 전체가 실제와 같은지를 통해 판별하지만, PatchGAN은 N*N patch에 해당하는 이미지의 부분만 실제와 같은지를 판단하는 방식을 전체 이미지에 적용해 전체 이미지를 판단한다. 그렇기 때문에 논문에서는 ImageGAN의 경우는 파라미터 수가 더 많고, 깊이가 더 깊어서 학습이 더 어렵기 때문에 위와 같은 결론이 나온거 같다고 설명한다.
PatchGAN의 이점으로 고정된 사이즈의 patch discriminator가 더 큰 사이즈의 이미지에 적용될 수 있다는 것이다. 예를 들면, 256*256의 이미지 사이즈로 학습된 generator가 512*512의 이미지를 생성할 수 있다.
(PatchGAN의 경우에는 따로 자세히 공부할 필요가 있을 것 같다,,,,)
Conclusion
다양한 실험들을 통해 이 논문에서 제안한 모델은 다양한 상황에서 일반적으로 (살짝의 수정을 가지고) 적용가능한 모델이라는 것을 보였다. 하지만 한계점 또한 존재한다. 앞에서 설명했듯이 Pix2Pix 모델을 학습시킬 때, 조건이 필요하다. 그런데 그 조건은 이미지 x 자체가 된다. 그렇기 때문에 모델을 학습시키기 위해서는 이미지 pair 데이터 셋이 필요하다. 하지만 현실에는 그런 데이터 셋이 많이 존재하지는 않는다.
Pix2Pix의 이러한 한계점을 해결하는 모델이 cycleGAN이라는데 이와 관련된 논문도 읽어야겠다,,,,
이번 논문도 내가 공부한 것을 정리하기 위해 논문 리뷰 글을 썼는데 역시나 아직 많이 부족한 것 같다. 설명도 매끄럽지 않고 부족한 부분도 많아서 글을 올리는 거 자체가 살짝 부끄럽다,,,
앞으로 더 쓰면서 설명을 좀 매끄럽고 이해하기 쉽게 쓰도록 노력을 더 해야겠다
혹시라도 틀린 설명이나 부족한 부분을 피드백해주시면 감사하겠습니다!
Reference
https://arxiv.org/abs/1611.07004
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org



