
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python
- Programmers
- Vit
- transformer
- diffusion
- VirtualTryON
- video generation
- image editing
- diffusion model
- segmentation map
- noise optimization
- 논문리뷰
- flipd
- 네이버 부스트캠프 ai tech 6기
- 코테
- 3d generation
- visiontransformer
- inversion
- BOJ
- rectified flow
- video editing
- masactrl
- 코딩테스트
- diffusion models
- 프로그래머스
- DP
- 3d editing
- flow matching
- segmenation map generation
- memorization
- Today
- Total
목록AI/GAN (6)
평범한 필기장
 [평범한 학부생이 하는 논문 리뷰] StarGAN : Unified Generative Adversarial Networks for Multi_Domain image-to-image Translation
[평범한 학부생이 하는 논문 리뷰] StarGAN : Unified Generative Adversarial Networks for Multi_Domain image-to-image Translation
https://arxiv.org/abs/1711.09020 StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for eve arxiv.org GAN 스..
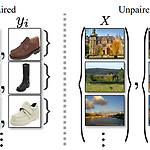 [평범한 학부생이 하는 논문 리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network (CycleGAN)
[평범한 학부생이 하는 논문 리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network (CycleGAN)
기존 image to image translation의 문제점 기존 pix2pix모델을 통한 image to image translation은 paired된 데이터로만 가능했다. 그러나 paired된 데이터는 실제로는 흔하지 않다. 그렇기에 unpaired된 데이터에 대해서도 image to image translation이 가능한 모델이 필요하다. 이러한 문제를 해결하기 위해 나온 모델이 바로 CycleGAN이다. CycleGAN은 그럼 어떤 차이점을 가졌길래 앞선 문제를 해결했을까? CycleGAN의 특징 위의 이미지(a)가 CycleGAN의 가장 특징을 보여준다. 기존의 GAN은 $G : X \rightarrow Y$ 라는 하나의 매핑함수만 가지고 이미지를 생성했다. 하지만 $X$라는 도메인에서 Y..
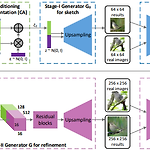 [평범한 학부생이 하는 논문 리뷰] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
[평범한 학부생이 하는 논문 리뷰] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
기존 Text to Image의 문제점 기존에 conditional GAN을 이용해서 Text to Image문제를 해결하려했지만 여러 문제점을 지녔다. text description의 의미를 rough하게 반영은 하지만 이미지의 detail이 떨어지고 생생한 object를 생성하지 못했다. 즉, 고화질의 사실적인 이미지를 생성하지 못했다. GAN에 upsampling layer를 더 쌓아서 해결하려했지만, instability를 보였고, nonsensical한 결과를 생성했다. 그래서 이러한 문제점들을 해결하려 했고, 그 결과로 StackGAN이라는 모델을 만들었다! Contribution StackGAN을 알아보기 전에 이 모델이 가지는 기여점에 대해 먼저 설명하겠다. Text로부터 photo-rea..
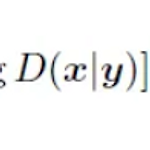 [평범한 학부생이 하는 논문 리뷰] Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix)
[평범한 학부생이 하는 논문 리뷰] Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix)
GAN, DCGAN을 읽고 나서 이번에는 Conditional GAN에 관한 논문을 읽어 봐야겠다라는 생각이 들기도 했고, 스터디에서도 이 논문을 읽을 차례가 돼서 이번엔 Image-to-Image Translation with Conditional Adversarial Networks를 정리할 겸 리뷰하려한다. 원본 논문 링크 : https://arxiv.org/abs/1611.07004 Image-to-Image Translation with Conditional Adversarial Networks We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation probl..
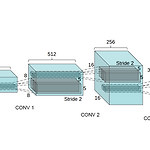 [평범한 학부생이 하는 논문 리뷰] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
[평범한 학부생이 하는 논문 리뷰] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
기존 vanilla GAN이 가지는 한계점 학습이 불안정적이다. 불안정적으로 학습이 되다보니, Generator와 Discriminator사이의 힘의 균형이 깨져 한쪽이 계속 이겨버리는 상황이 발생한다. 그러다 보니 Generator가 종종 어처구니없는 이미지를 생성하게 된다. 결국 우리가 원하는 결과를 얻을 수 없게 된다. mode collapse GAN에서 Generator는 Discriminator를 속이는 방향으로 학습이 되는데 그러다 보니 데이터가 많은 이미지만 계속해서 생성하게 된다. 이렇게 되면 Discriminator를 속이는 것은 맞지만 다양한 이미지를 생성하는 것과는 맞지 않게 된다. Black-Box 방식 왜 이런 결과가 나왔는지 알 수 없다. 어떤 특징 때문에 이런 이미지가 생성됐는..
 [평범한 학부생이 하는 논문 리뷰] Generative Adversarial Nets (GAN)
[평범한 학부생이 하는 논문 리뷰] Generative Adversarial Nets (GAN)
3-2학기 학부연구생을 하면서 처음으로 읽게 된 논문이 바로 이 Generative Adversarial Nets라는 논문인데, 딥러닝 기초만 조금 봐본 제가 공부하면서 정리하는 느낌으로 하는 리뷰이니 틀린 부분, 잘못 이해한 부분이 많을 수 있다는 점 말씀드리고 리뷰 시작해보도록 하겠습니다! 0. Abstract 일단 이 논문의 abstract에서는 저자들이 두 개의 모델을 적대적인 process로 학습시켜서 생성 모델을 평가하는 프레임 워크를 목적으로 했다고 밝혔다. 여기서 두 개의 모델은 생성 모델인 G와 판별 모델인 D로 설명을 했다. generative model G : 데이터의 분포를 모사해 D가 실수할 확률을 최대화하는 방향으로 학습 discriminative model D : sample ..