

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 3d editing
- 네이버 부스트캠프 ai tech 6기
- ddim inversion
- flow matching models
- Programmers
- 프로그래머스
- DP
- Vit
- image editing
- 논문리뷰
- BOJ
- visiontransformer
- image generation
- freeinv
- flow matching
- diffusion model
- rectified flow
- diffusion models
- VirtualTryON
- video editing
- diffusion
- memorization
- 코딩테스트
- 코테
- video generation
- transformer
- inversion
- shortcut model
- Python
- 3d generation
- Today
- Total
평범한 필기장
[최종 프로젝트 일지 - 2주차] 삽질의 연속... 본문
1주차에는 데이터 수집하고 제작하고 클랜징을 주로하면서 ControlNet 논문을 읽고 공식 깃헙에 있는 튜토리얼을 진행하면서 ControlNet이 뭔지를 익혔었다. 이번 주에는 이제 우리의 데이터로 ControlNet을 학습시키기 시작했다. 이 부분은 내가 전담으로 맡아서 했다. 처음 계획은 아무것도 건들이지 않고 custom 데이터셋으로 학습시키고 결과를 지켜보면서 데이터를 수정하고 모델을 잘 학습시키기 위한 여러 기법(DreamBooth, LoRA 등)을 논문을 읽어보고 직접 적용해서 우리의 서비스에 맞게 finetuning을 해나가는 것이었다. 당연히 데이터셋만 바꾸면 될 줄 알았기에 금방 실험을 진행할 수 있을 줄 알았다...
튜토리얼 데이터로 진행된 학습
Diffusers를 이용해서 다들 diffusion 모델들을 이용을 다들 해볼 것이다. 나는 이번 프로젝트를 통해 diffusion을 직접 학습해보고 inference 결과를 보는 것이 처음이었고, 당연히 Diffusers라는 라이브러리를 쓰는 것도 처음이였다. 그래서 튜토리얼로 어떻게 진행되는지를 저번 주차에 맛보기를 진행해본 것이었다. 나는 당연히 dataset에 내 custom 데이터셋의 경로를 넣으면 쉽게 진행될 줄 알았다.
하지만 역시나 세상은 그렇게 호락호락 하지 않았다. dataset이라는 함수에 custom 데이터셋의 경로를 넣고 학습시키니까 아래와 같은 결과가 나왔다.

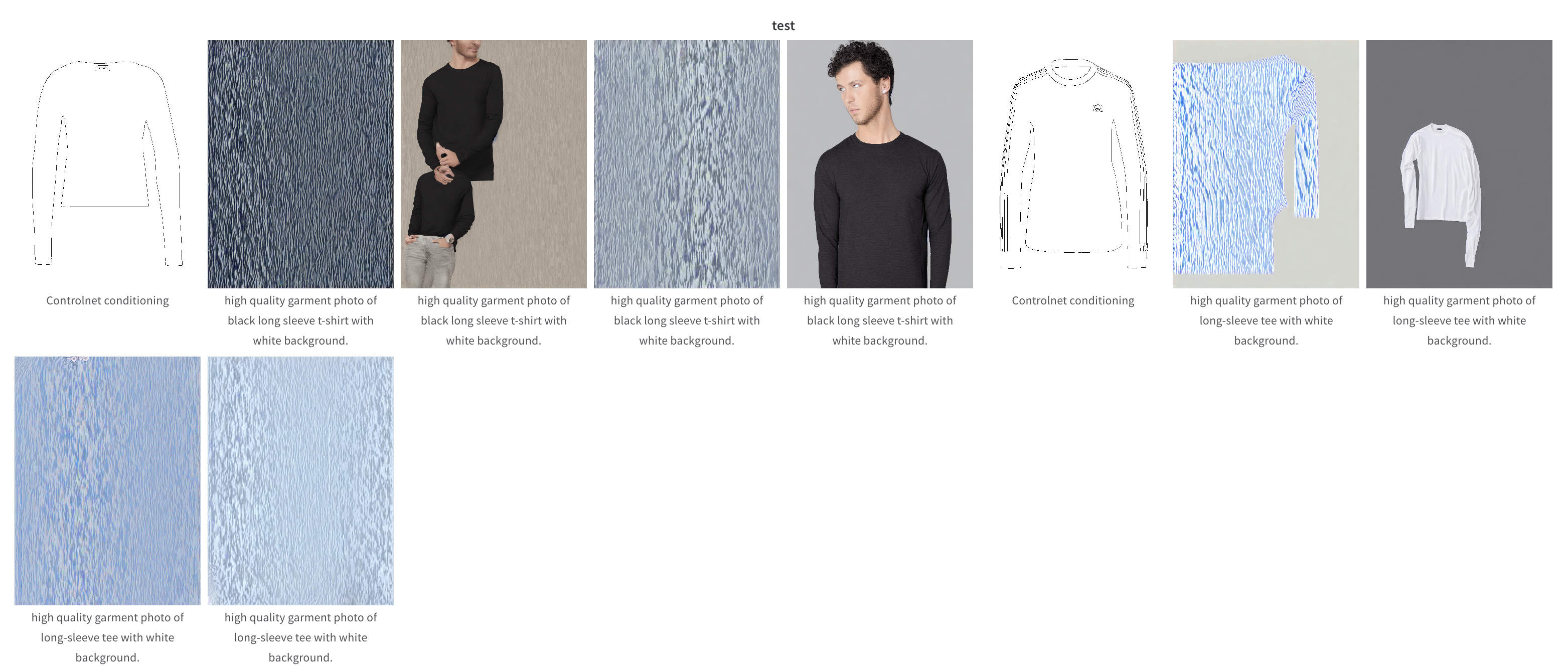
오른쪽 이미지는 input text 형식을 변경해서 실험을 진항한 것인데 역시나 결과는 좋지 않았다. 아무리 생성모델을 학습시키는 것이 쉽지 않다지만 이렇게 말도 안되는 결과가 나오느게 맞나?라는 생각이 들었다. 그래서 다음 실험 때는 input이미지 몇개를 wandb에서 볼 수 있도록 설정을 했다. 그렇게 input 이미지를 보니 내 데이터가 아닌 튜토리얼을 할 때 사용되는 데이터가 들어간 것이다. 이 문제는 어떻게 해결을 했는지 기억은 자세히 나지 않지만.... 깃헙 이슈들을 엄청 뒤져서 이 문제는 겨우 겨우 해결을 했다.
하지만 이후에 또다른 문제가 발생했다. 바로 "ValueError: image at conditioning_images/00001.png doesn't have metadata in metadata.jsonl" 라는 오류가 발생했다. 이 문제 또한 diffusers 깃헙 이슈를 뒤지고 뒤져서 해결을 했다. 해결 방식은 다음과 같았다.
일단 학습 데이터 폴더를 아래와 같이 구성해야한다.
train
├── conditioning_images
│ ├── conditioning_image_1.jpg
│ └── conditioning_image_2.jpg
├── images
│ ├── image_1.jpg
│ └── image_2.jpg
├── metadata.jsonl
└── train.py
그리고 metadata.jsonl 파일을 기존에 아래와 같이 구성을 했었는데,
{"file_name": "images/00001.jpg", "conditioning_image": "conditioning_images/00001.png", "text": "a man in a suit and tie speaking into a microphone"}
{"file_name": "images/00002.jpg", "conditioning_image": "conditioning_images/00002.png", "text": "a bald man in a suit and tie giving a speech"}
다음과 같은 형식으로 변경을 해줬다.
{"images": "00001.png", "conditioning_images": "00001.jpg", "text": "a man in a suit and tie speaking into a microphone"}
{"images": "00002.png", "conditioning_images": "00002.jpg", "text": "a bald man in a suit and tie giving a speech"}
또한 https://huggingface.co/datasets/fusing/fill50k/tree/main를 참고해서 train.py라는 python파일을 학습 데이터셋 폴더에 넣어줬다. 여기서 아래 함수 부분의 경로를 내 metadata.jsonl, images, conditioning_images의 경로를 넣어줬다.
def _split_generators(self, dl_manager):
metadata_path = r'/path/train/metadata.jsonl'
images_dir = r'/path/train/images/'
conditioning_images_dir = r'path/train/conditioning_images/'
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
# These kwargs will be passed to _generate_examples
gen_kwargs={
"metadata_path": metadata_path,
"images_dir": images_dir,
"conditioning_images_dir": conditioning_images_dir,
},
),
]
이렇게 하니 앞에서 겪었던 문제들을 다 해결하고 내 데이터셋으로 학습을 시킬 수 있게 됐다.
(이번 문제를 통해 정말 깃헙 이슈를 뒤지는게 얼마나 중요한지를 배웠다...)
실험 결과
며칠 간의 삽질을 끝내고 드디어 제대로 실험을 시작했다. 나는 ControlNet자체가 약간 StableDiffusion을 conditional generation을 하기 위한 transfer learning방식? 정도로 이해를 했기 때문에 from scratch로 학습을 진행할 수 있을 것이라고 생각했다. 그리고 우리의 데이터셋 자체도 1만장이 조금 넘었으니까 충분히 가능할 것이라고 생각했다. 그래서 from sratch로 학습을 하는 방식을 처음에는 택했다.
실험 1.
첫 실험은 high quality garment photo of {prompt} with white background. 형태로 input text를 모든 데이터에 대해 고정해서 실험을 진행했다. ControlNet 논문을 보니 high quality, high resolution이라는 input을 줘서 고화질의 이미지가 생성되는 것 같아서 나도 그런 방식을 택했다. {promp}에는 우리가 쓰는 multimodl viton-hd데이터 셋에 있는 caption중에서 첫번 째 caption을 넣었다. (multimodal viton-hd 데이터셋을 제시한 논문에서 평가 score를 기반으로 가장 높은 score를 가진 text 3개를 caption으로 선정했다고 한다.)

실험 결과는 위와 같이 나오는데 뭔가 많이 아쉽다.... 옷의 형태가 input의 conditioning image와도 맞지가 않았다.
실험 2.
위 실험 결과의 문제점을 보완하기 위해, 논문에서 text의 의존성을 줄이고 conditioning image의 style을 많이 반영하기 위해서 학습 시에 prompt를 ""로 주는 기법을 추가해서 실험을 진행했다. Proportion_empty_prompts 0.5로 설정로 설정해서 실험을 진행했다.

앞의 실험 결과보다는 나아졌다고 볼 수 있겠지만 확실히 아직 많이 부족했다... 그래서 from scratch로 학습하는 것은 포기를 했다. 이런 sketch형태의 이미지를 통해 실제 이미지를 생성하는 pretrained된 ControlNet 모델을 찾아서 이 pretrain된 모델을 finetunning하는 방식으로 바꿨다.
실험 3.
앞의 설정과 동일하게 pretrained된 ControlNet을 써서 실험을 진행했다.

확실히 pretrained 된 모델을 쓰니까 성능은 훨씬 좋아졌다. 이 이미지들 외에 test 데이터들에 대해 다 결과를 내봤는데 퀄리티는 많이 많이 좋아졌다. 하지만 아직 색을 잘못 입히는 경우가 많이 발생하는 것으로 보여졌다... 이러한 문제들이 발생한 이유로는 일단 test 이미지들에 대한 text 데이터중에 색을 나타내는 단어가 없는 text가 있는 것도 있다. 학습 데이터도 마찬가지이다.
이러한 이유로 다음 주에는 text 데이터를 수정을 하고 학습을 진행할 예정이다. 물론 1만장의 이미지들에 대한 모든 text를 다 수정할 수 없기에 image captioning을 통해 이미지가 어떤 색의 물체인지를 뽑아내서 그것을 text 데이터에 붙이는 방식 등을 고려해볼 생각이다. 또한 DreamBooth와 LoRA 논문을 읽고 있는데 이 두가지도 적용을 할 수 있으면 해볼 생각이다.
마무리...
첫 프로젝트가 본격적으로 시작하면서 내가 맡은 부분을 정말 깊게 파보는 중이다. 처음이다 보니 어려움을 많이 겪고 있는데 그래도 하나하나 헤쳐나가면서 많은 것들을 배우는 중인 것 같다. 모델링 전반을 나 혼자 맡다싶이 하고 있기 때문에 물어볼 사람이 없어서 혼자 이것 저것 많이 찾아보면서 하고 있는데 이러다보니 처음 해보는 것이 정말 정말 많은 것 같다. 특히 깃헙 이슈를 뒤지면서 내가 겪은 문제를 해결을 하는 것이 처음이었다. 이번 한주동안 이 부분이 가장 크게 얻어가는 부분이었다.
이제 2주 조금 넘게 남았는데, 마무리만 잘 했으면 좋겠다!ㅎㅎ
'Experience > Naver Boostcamp 6기' 카테고리의 다른 글
| 네이버 부스트캠프 그 후 이야기 (1) | 2024.06.20 |
|---|---|
| [최종 프로젝트 일지 - 3주차] 멘토님 피드백 준비 (0) | 2024.03.23 |
| [최종 프로젝트 일지 - 1주차] 최종 프로젝트 시작! (3) | 2024.03.12 |
| [최종 프로젝트 일지 - 0주차] 쉽지 않았던 준비 기간... (1) | 2024.03.10 |
| [모델 구현] Vision Transformer 구현 (3) | 2023.11.25 |

