
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DP
- image editing
- flow matching models
- freeinv
- visiontransformer
- 프로그래머스
- Python
- 코테
- video generation
- shortcut model
- 3d generation
- ddim inversion
- diffusion
- 논문리뷰
- inversion
- rectified flow
- Programmers
- 3d editing
- BOJ
- video editing
- one step generation
- VirtualTryON
- 코딩테스트
- 네이버 부스트캠프 ai tech 6기
- Vit
- memorization
- diffusion model
- image generation
- transformer
- diffusion models
- Today
- Total
평범한 필기장
[평범한 청강생의 논문 맛보기] ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion 본문
[평범한 청강생의 논문 맛보기] ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
junseok-rh 2024. 4. 30. 20:54https://arxiv.org/abs/2403.18818
ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approache
arxiv.org
1. Introduction
Photorealistic한 이미지를 수정하는 것은 시각적인 appeal과 물리적인 그럴듯함을 동시에 필요로한다. Diffusion-based editing 모델들은 미적인 퀄리티를 강화해온 반면, 종종 물리적으로 실제적인 이미지를 생성하는데 실패한다. 예를 들면 object removal 방식은 object에 의해 가려진 픽셀들을 대체해야할 뿐만아니라, 그 object가 그 장면에 영향을 미치는지도 모델링해야한다. (그림자나 반사를 제거하는 것과 같은)
장면에 object의 효과를 추가하거나 없애는 것은 그 object가 있거나 없을 때의 장면이 어떨지에 대한 이해를 필요로 한다. Self-supervised 접근법들은 사실과 반대되는 이미지들의 접근이 부족한 채, 존재하는 이미지들의 관찰에만 의존한다. Disentanglement 연구들은 이 종류의 데이터만으로는 부정확한 수정을 이끈 채 내재적인 물리적인 프로세스를 확인하고 학습시키는 것은 어렵다고 강조한다. 이는 장면에서 완벽하지 않은 object 제거나 물리적으로 그럴듯하지 않은 변화를 드러낸다.
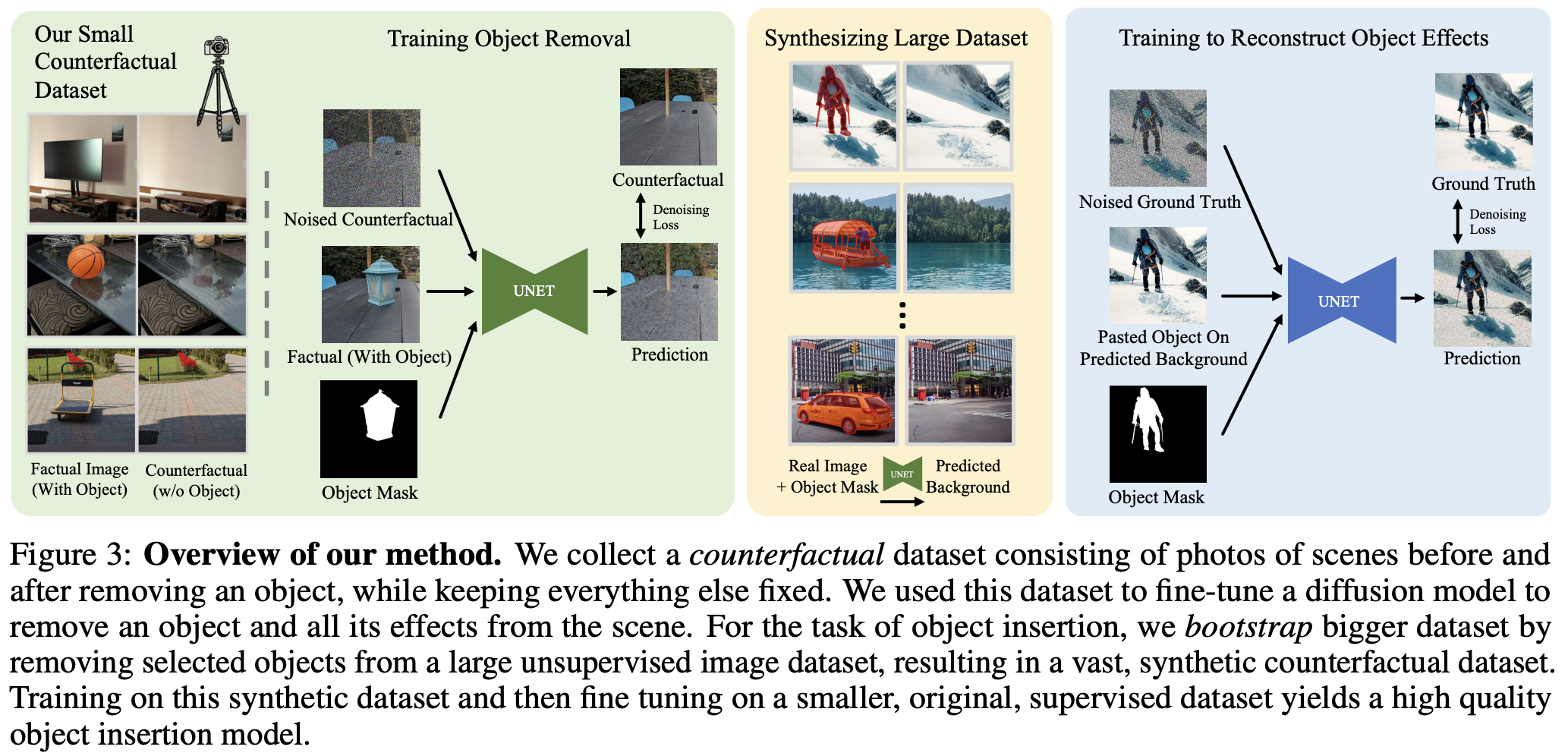
본 논문에서는 꼼꼼하게 curated된 "counterfactual"한 데이터셋에 대해 diffusion 모델을 학습시키는 실용적인 접근법을 제안한다. 각 샘플은 i) 장면을 묘사하는 사실적인 이미지와 ii) object변화 후의 장면을 묘사하는 counterfactual한 이미지를 포함한다. 이 데이터셋은 물리적으로 장면을 대체함으로써 만들어졌다. (장면을 찍고, object를 제거해서 장면을 다시 찍음) 이러한 접근법은 각 샘플들이 다른 변화 없이 object의 존재에 연관된 장면만을 반영한다.
이 접근법은 object를 제거하는 데에는 효과적이지만, 새로운 object를 넣는 데에는 불충분하다. 그림자와 반사를 합성해야하는 object insertion은 제거하는 것보다 복잡하기에 다른 방식을 도입한다.
- 위에 제시한 데이터셋을 통해 object removal model을 학습시킨다.
- Removal model을 통해 방대한 합성 데이터셋을 만든다.
- 이 데이터셋을 통해 diffusion model을 finetune시킨다.
본 논문에서 이 방식을 bootstrap supervision이라고 부른다.
이 논문의 contribution은 다음과 같다.
- 그림자, 반사 등 장면에서 object의 효과를 편집하기 위한 self-supervised training의 한계에 대한 분석
- 사실적인 object 제거를 위한 효과적인 couterfactual supervised training 방식
- Object insertion 시 라벨링 부담을 완화하는 bootstrap supervision 방식.
2. Task Definition
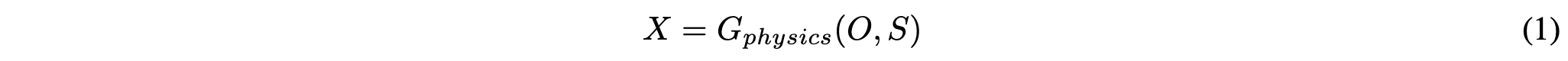
여기서 $X$는 input image로 물리적인 3D 장면 $S$를 묘사한다. $O$는 object로 모델이 object $O$가 장면에 추가되거나 제거됐을 때 장면이 어떻게 보일지를 생성하는 것이 목적이다. $G_{physics}$는 물리적인 rendering 메커니즘을 나타낸다. 이렇게 desired된 output은 couterfactual image $X^{cf}$이고 다음과 같이 쓸 수 있다.
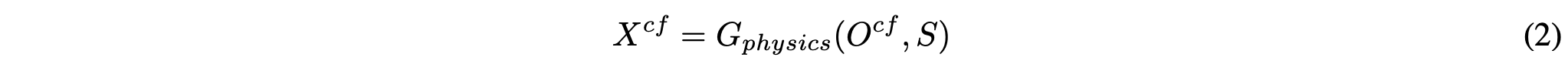
Object removal에서는 원래 object가 존재하기에 $O = o$이고 $O^{cf} = \phi$로 해서 object를 제거하기를 원한다. Object insertion에서는 반대로 볼 수 있다.
물리 렌더링 메커니즘인 $G_{physics}$는 비교적 잘 알려져 있지만, 식 1은 물리적 object와 장면에 대한 완벽한 지식이 필요하기 때문에 편집에 직접 사용할 수 없으며, 이는 거의 불가능합니다.
3. Self-Supervision is Not Enough
숨겨진 변수 ($O, S$)와 생성 mechanism ($G_{physics}$)를 추론하는 task를 disentanglement라고 부른다. 이 문제를 해결하려는 다양한 시도가 있었다.
첫 번째 시도는 바로 diffusion-based inpainting이다. 하지만 이 방식에서의 가장 큰 한계점은 segmentation mask에 대한 의존도이다. Segmentation mask를 너무 보수적으로 잡으면 장면 pixel을 지우게 되고, 너무 tight하게 잡으면 그림자나 반사와 같은 것들이 남아서 객체에 대한 정보가 남게된다.
Prompt-to-prompt와 같은 attention-based 방식 또한 제안됐는데 이 방식은 inpainting의 실패 mode를 해결했지만 unrealistic한 수정을 야기하고 종종 그림자는 지우지 못한다.
위 self-supervised 접근법들의 핵심 한계점은 실제 생성 mechanism과 인과적인 hidden 변수들을 추론하지 못한다는 것이다.
4. Object Removal
4.1 Collecting a counterfactual dataset
다음과 같은 세 과정을 거쳐서 "counterfactual" 데이터셋을 제작했다.
- Object $O$와 장면 $S$을 포함한 "factual" 이미지 $X$를 찍는다.
- 카메로 움직임, 빛 변화, 다른 물체의 움직임을 피하면서 물리적으로 object $O$를 제거한다.
- Object $O$는 없지만 장면은 같은 "counterfactual" 이미지 $X^{cf}$를 찍는다.
Segment Anything 논문의 모델을 사용해서 object $O$의 segmentation map을 $M_o$를 만든다. 최종적인 데이터셋은 factual 이미지와 binary object mask $(X,M_o(X))$로 된 input과 $X^{cf}$ output으로 구성된다.
4.2 Counterfactual distribution estimation
본 논문의 목표는 factual image $x$와 segmentation mask가 주어졌을 때, counterfactual images의 분포 $P(X^{cf}|X = x,M_o(x))$를 추정하는 것이다. 본 논문에서는 이를 본 논문에서 제안한 데이터셋으로 large-scale diffusion model을 finetuning함으로써 한다. 다음 수식을 최소화함으로써 추정이 가능하다.
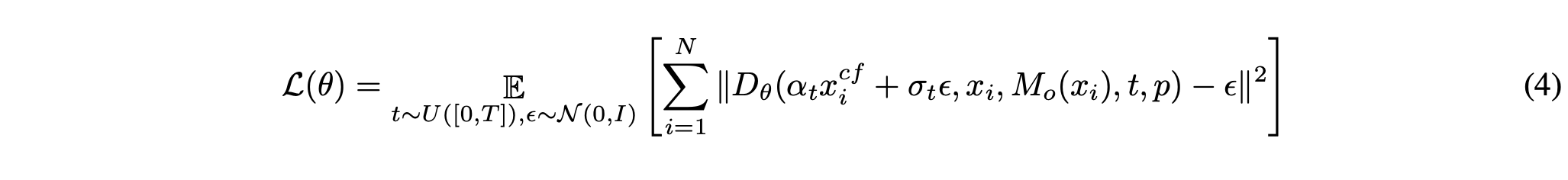
여기서 $D_\theta(\tilde{x_t},x_{cond},m,t,p)$는 denoiser network로 counterfactual image의 noised latent representationd인 $\tilde{x_t}$, 우리가 제거하고 싶어하는 object를 포함한 이미지의 latent representation $x_{cond}$, object의 위치를 나타내는 mask $m$, timestep $t$, text prompt의 encoding $p$를 input으로 받는다.
전통적인 inpainting 방식과 다르게, object의 pixel을 uniform gray나 black pixel로 바꾸는 것을 피한다. 이 접근 방식을 사용하면 모델이 마스크 내에 보존된 정보를 활용할 수 있으므로 부분적으로 투명한 object나 불완전한 마스크가 포함된 시나리오에서 특히 유용하다고 한다.
4.3 Advantages over video supervision
Video로부터 얻어진 supervision을 사용하면 더 싸지만 심각한 한계점을 지닌다. i) Counterfactual dataset에서는 유일하게 바뀌는 것이 object이지만 video에서는 다른 많은 특성이 바뀐다. 이는 object removal과 다른 특성 사이의 가짜 상관관계를 이끈다. ii) 이 방식은 움직이는 object에서만 작동한다. 논문 섹션 6에서 본 논문에서 제시하는 방식이 video supervision을 능가하는 것을 보인다.
5. Object Insertion
이 테스크에서, object의 이미지, 위치, target 이미지가 주어진다. 이를 통해 우리의 목표는 object가 주어진 채로 사진을 찍었을 때, target image가 어떻게 보일지를 예측하는 것이다. 본 논문에서 수집한 데이터셋은 상대적으로 작기 때문에 object removal에서는 성공적이었지만 object insertion에서는 불충분하다.
5.1 Bootstrapping counterfactual dataset
본 논문에서는 본 논문의 counterfactual dataset을 활요해 large-scale counterfactual object insertion 데이터셋을 제작하는 방식을 제안한다. 외부의 거대한 이미지 데이터셋을 가져와서 foreground detector를 통해 object를 먼저 detect한다. 그리고 본 논문의 object removal model $P(X^{cf} | X,M_o(X))$을 통해 장면에서 object와 그것에 대한 효과를 제거한다. 그 결과를 다음과 표현한다.
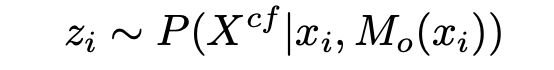
그리고 마지막으로 $z_i$에 object를 붙인다. 이 때 이미지에는 그림자나 반사는 없다.

최종적으로 데이터셋은 input $(y_i, M_o(x_i))$과 output인 original image $x_i$로 구성된다.
Input과 output이미지는 objective $o_i$를 포함하지만 input 이미지는 object의 효과를 포함하지 않고 output은 포함한다.
5.2 Diffusion model training
식 (4)를 통해 diffusion model을 학습시킨다. Object removal 과정과 다르게, inpainting pre-training을 겪지 않은 pre-train된 text-to-image model $D_\theta(x,t,p)$를 사용한다. Input mask때문에 input 차원이 커지기 때문에, T2I model의 input에 새로운 채널을 넣고 weight를 0으로 초기화한다.
5.3 Fine-tuning on the ground truth counterfactual dataset
합성 데이터가 충분히 realistic하지 않기 때문에 pre-training에만 사용된다. 마지막 단계로 원래의 counterfactual 데이터셋으로 모델을 fine-tune한다. Bootstrapped 데이터셋으로 pre-training하는 것은 작은 ground-truth 데이터셋을 사용한 효율적인 fine-tunning을 가능하게 한다.
6. Experiments
6.1 Object Removal
Qualitative results

Quantitative results

User study

6.2 Object Insertion
Qualitative results


Quantitative results

User study

6.4 Ablation Study
Bootstrapping

Dataset size

Text-to-image vs. inpainting pretrained model

7. Limitations
본 논문에서 제시한 방식은 장면에 대해 object가 가지는 효과를 시뮬레이팅하지, object에 대한 장면의 효과를 시뮬레이팅하지 않는다. 그렇기 때문에 object의 방향과 빛이 장면과 호환성이 없는 시나리오에서 unrealistic한 결과를 낸다. 또 본 논문에서 제시한 모델은 물리적은 3D 장면과 빛을 완벽하게 알지 못하기에 현실과 유사하지만 정확하지 않은 그늘 방향을 야기한다.
8. Conclusion
ObjectDrop은 기존의 self-supervised 접근법들의 한계점을 극복한 object removal/insertion를 위한 접근법이다. 기존의 sota를 능가했다.


