

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- diffusion model
- Vit
- 프로그래머스
- diffusion models
- noise optimization
- DP
- video editing
- 코딩테스트
- segmentation map
- 코테
- 3d generation
- Python
- memorization
- image editing
- visiontransformer
- Programmers
- flow matching
- flipd
- 논문리뷰
- transformer
- inversion
- BOJ
- 네이버 부스트캠프 ai tech 6기
- segmenation map generation
- VirtualTryON
- 3d editing
- masactrl
- diffusion
- video generation
- rectified flow
- Today
- Total
평범한 필기장
[평범한 청강생의 논문 맛보기] Improving Text-to-Image Consistency via Automatic Prompt Optimization (OPT2I) 본문
[평범한 청강생의 논문 맛보기] Improving Text-to-Image Consistency via Automatic Prompt Optimization (OPT2I)
junseok-rh 2024. 4. 17. 00:46https://arxiv.org/abs/2403.17804
Improving Text-to-Image Consistency via Automatic Prompt Optimization
Impressive advances in text-to-image (T2I) generative models have yielded a plethora of high performing models which are able to generate aesthetically appealing, photorealistic images. Despite the progress, these models still struggle to produce images th
arxiv.org
1. Introduction
기존의 T2I 모델들은 생성된 이미지의 퀄리티를 높이는 대신 다양성이나 prompt-image consistency를 내줬다. 흔한 consistency failure로는 missing object, wrong object cardinality, missing or mixed object attributes, non-compliance with requested spatial relationship among objects in image 등이 있다. 이를 해결하려는 연구가 많았다.
본 논문에서는 첫 ICL(in-context learning)-base로 T2I 모델들에서 prompt-image consistency를 향상시킨 방식을 제안한다. 본 논문에서 제안한 프레임워크 OPT2I (Optimization for T2I generative models)는 pre-trained T2I model, LLM, automatic prompt-image consistency score (CLIP score, DSG score)를 포함한다. ICL을 통해, LLM은 반복적으로 유저의 의도에 더 잘 맞는 이미지를 이끄는 대안 prompt를 제안함으로써 유저가 제공한 text prompt를 향상시킨다. Optimize된 prompt는 기대에 더 맞는 이미지를 생성할 것이다. OPT2I는 파라미터 업데이트가 필요하지 않기 때문에 다양한 T2I 모델들, LLMs, scoring functions에 plug-and-play solution으로 작동하는 다재다능한 접근법이 되도록 디자인됐다.

본 논문의 contributrion은 다음 세가지이다.
- Prompt-image consistency를 향상시키는 정제된 prompts를 제공하는 training-free T2I optimization-by-prompting 프레임워크인 OPT2I를 제안한다
- OPT2I는 특정 T2I 모델에 매여있지 않고 consistency metric 뿐만 아니라 LLM의 선택에 robust하다
- OPT2I는 paraphrasing baseline을 outperform하고 prompt-image consistency를 24.9%까지 올렸다
2. OPT2I : Optimization by prompting for T2I

위 이미지는 본 논문에서 제안한 T2I optimization-by-prompting 프레임워크를 나타낸 것이다. 이는 pretrain된 T2I model과, LLM, prompt-image consistency score로 이루어져있다. 과정은 다음과 같다.
- user prompt를 T2I model에 넣어서 이미지들을 생성한다.
- 생성된 이미지와 user prompt를 통해 consistency score를 계산하고 평균을 낸다.
- meta-history를 user-prompt와 consistency score로 초기화 한다.
- meta-prompt를 LLM에 주어서 개선된 prompts set을 받는다.
- 개선된 prompt를 T2I model에 넣어 새로운 이미지를 생성한다. (새로운 optimization step)
여기서 consistency score는 항상 user prompt에 관해서 계산된다. 각 optimization step에서, meta-prompt history는 top-k most consistent prompt를 포함하도록 업데이트된다. 위 과정은 iteration이 끝나거나, perfect/target consistency score에 도달하면 끝난다.
2.1 Problem formulation
우리의 목적은 샘플링된 이미지의 예상된 consistency score를 최대화하는 prompt paraphrase $\hat{p} \in \mathbb{P}$를 찾는 것이다.
$$\hat{p} = \underset{p_i \sim \mathbb{p}}{\rm argmax} \underset{I \sim g(p_i)}{\mathbb{E}}[\mathcal{S}(p_0,I)]$$
여기서 $p_0$는 user prompt이다. 본 논문에서 LLm에 의해 생성된 수정된 prompt들을 반복적으로 서칭함으로써 ICL과 최적화 문제를 접근한다.
$$P_t = f(C(\{ p_0 \} \cup P_1, \cdots, \cup P_{t-1}))$$
여기서 $P_i$는 $i$번째 iteration에서 생성된 prompts의 집합이고, $t$는 현재 iteration, $C$는 LLM에 들어간 prompt-score pairs의 context를 정의하는 함수이다.
2.2 Meta-prompt design
본 논문은 LLM에 T2I models를 위한 prompt를 최적화하라고 지시하는 prompt를 meta prompt라고 한다. Meta prompt는 task instruction과 이전에 수정된 prompt-score pairs의 history로 구성된다. Meta prompt는 T2I models, consistency metric, 최적화 문제에 대한 context를 제공한다. 또한 어떤 paraphrases가 과거에 특정 T2I model에 잘 작동했는지에 대한 prompt-score pairs의 history를 포함한다. 이는 LLM이 가장 성공적인 prompt를 세우도록 장려하고 T2I prompt를 어떻게 수정할지 명시할 필요를 제거한다.
2.3 Optimization objective
이 프레임워크에서 중요한 부분은 LLM에 시각적 피드백을 주는 것이다. 이 시각적 피드백은 consistency score에 의해 capture된다. OPT2I는 어떤 consistency score와도 작동하지만, 본 논문은 consistency score는 LLM이 후보 prompt를 어떻게 향상시킬지 추론할 수 있을 정도로 충분히 디테일해야한다고 주장한다. 그래서 CLIP score처럼 하나의 스칼라 값을 내는 것은 본 논문의 목적에 비해 너무 coarse하다고 한다.
본 논문에서는 두 가지 metric을 이용한다.
Davidsonian Scene Graph (DSG) score
DSG는 방식은 질문 생성과 답변 방식으로 consistency를 평가한다. 특히 이 방식은 user prompt로 부터 atomic하고 unique한 binary 질문을 생성한다. 그리고 따로 존재하는 VQA 모델을 통해 이 질문에 대한 대답을 생성한다. meta-prompt에 결과 question-answer pairs를 포함한다. 이러한 대답 score들을 평균내서 prompt-image pair당 global한 점수를 계산한다.
Decomposed CLIPScore
Decomposed CLIPScore는 user prompt에 있는 각 명사들에 대한 부분적인 consistency score를 계산한다. 그리고 이렇게 생성된 명사와 점수 pairs에 대한 list는 meta-prompt에 포함된다.

2.4 Exploration-exploitation trade-off
최적화 과정동안, LLM은 가능한 수정된 prompts를 탐구하거나 meta-prompt history에서 제공되는 context를 이용하는 것에 집중할 수 있기 때문에 OPT2I는 LLM의 exploration-exploitation trade-off에 대한 controlability를 필요로 한다. Iteration당 생성되는 수정된 prompt의 수와 LLM sampling temperature를 조정함으로써 이 밸런스를 컨트롤한다. 게다가 우리의 목적은 다른 T2I input noise sample들에 대해 잘 작동하는 prompt를 찾는 것이 목적이기 때문에, 각 iteration에서 prompt당 여러 개의 이미지들을 생성한다.
3 Experiments
3.1 Experimental settings
- Benchmarks : MSCOCO, PartiPrompts
- Evaluation metrics : decomposed CLIPScore, DSG score
- LLMs and T2I models : LDM-2.1, CDM-M,Llama-2, GPT-3.5
- VQA model : Instruct-BLIP
3.2 Main Results
T2I optimization by prompting
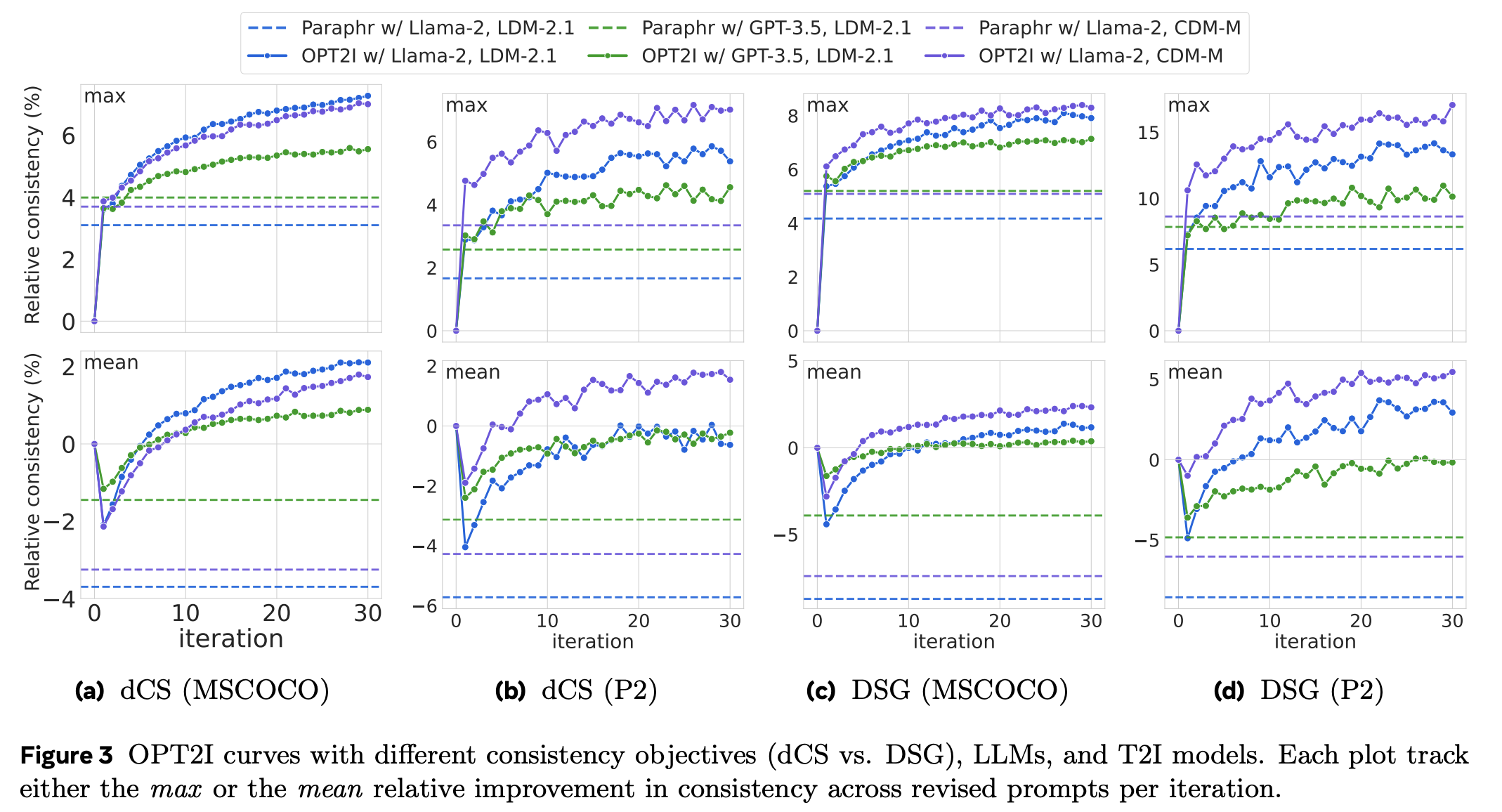
전체적으로 상승 곡선으로 OPT2I에서 LLM은 T2I prompt를 최적화할 수 있다는 것을 보인다.
Comparision to paraphrasing baselines

위 표는 OPT2I 프레임워크가 LLM, T2I model, optimization/evaluation objective에 robust하다는 것을 보여준다.
Qualitative results

위 결과를 보면 optimized prompt는 T2I model을 초기 phrasing에서 무시된 시각적 요소들을 생성하도록 조종할 수 있다는 것을 보여준다. 또한 LLM이 missing visual elements에 대해 더 디테일한 정보를 주거나 문장 앞쪽으로 위치시키는 등의 방식으로 강조하는 몇가지 전략을 사용하는 것이 관찰된다.
3.3 Trade-offs with image quality and diversity

위 결과를 보면, 본 논문의 방식은 consistencty를 위해 이미지 quality를 손해보지 않는다. 또한 더 적은 precision을 손해보고 더 높은 recall을 달성해 더 다양한 이미지를 생성하는 것을 볼 수 있다.
4. Conclusions
본 논문은 prompt-image consistency를 향상시키기 위해 첫 T2I optimization-by-prompting 프레임워크를 도입했다. OPT2I는 다른 조합의 LLM, T2I model, consistency metric에 적용할 수 있고, 성능 또한 baseline을 능가한다. 또한 consistency score의 선택에 대한 중요성을 강조한다. 복잡한 prompt에 대해서는 DSG와 같은 더 디테일한 score가 더 효과적이다. Prompt 수정은 학습된 mode로 부터 떨어진 이미지들을 생성하게 한다. 이는 높은 recall(diversity)을 야기한다.
Limitations
이 방식의 한계점은 consistency score가 잘 작동한다는 기대 하에 사용된다는 것이다. DSG와 같은 VQA-based prompt-image consistency metric들은 질문 생성이나 그에 대해 대답하는 것에서의 한계로 고통받는다. 또한 이러한 metics를 최적화 objective로 사용하면 적대적인 방식에서 높은 점수를 받기 위한 요건을 충족하는 이미지를 생성하는 프롬프트를 찾아내어 실패 modes를 악화시킬 수 있다.
또 다른 한계점은 inference-time 최적화이기에 runtime에서의 한계점을 지닌다.


