
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- VirtualTryON
- Python
- image generation
- video generation
- inversion
- 논문리뷰
- image editing
- diffusion models
- flow matching
- Programmers
- memorization
- diffusion model
- 3d editing
- 프로그래머스
- BOJ
- flow models
- video editing
- unlearning
- Machine Unlearning
- rectified flow models
- 코테
- rectified flow
- ddim inversion
- 네이버 부스트캠프 ai tech 6기
- Concept Erasure
- diffusion
- flow matching models
- 3d generation
- visiontransformer
- rectified flow matching models
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Video-P2P: Video Editing with Cross-attention Control (CVPR 2024) 본문
[평범한 학부생이 하는 논문 리뷰] Video-P2P: Video Editing with Cross-attention Control (CVPR 2024)
junseok-rh 2025. 1. 3. 23:21Paper : https://arxiv.org/abs/2303.04761
Video-P2P: Video Editing with Cross-attention Control
This paper presents Video-P2P, a novel framework for real-world video editing with cross-attention control. While attention control has proven effective for image editing with pre-trained image generation models, there are currently no large-scale video ge
arxiv.org
Github : https://github.com/dvlab-research/Video-P2P
GitHub - dvlab-research/Video-P2P: Video-P2P: Video Editing with Cross-attention Control
Video-P2P: Video Editing with Cross-attention Control - dvlab-research/Video-P2P
github.com
0. Abstract
본 논문은 Video-P2P이라는 새로운 video editing framework를 제안한다. Image editing모델인 prompt2prompt의 video 버전이라고 생각하면 될 것 같다.

1. Introduction
기존에는 video에서 local object만 editing하는 것이 어려웠는데, 본 논문은 video를 locally와 globally하게 editing할 수 있는 pipeline을 제안한다.
Image editing 기법들에서, attention control은 detailed image editing에 대한 가장 효과적인 pipeline으로 나타났다. 그래서 real image를 editing하기 위해서 다음 두 가지 step을 필요로 한다.
- Pre-trained diffusion model을 이용해서 image를 latent feature로 변환한다.
- Image에서 해당하는 부분을 editing하기 위해 denoising process에서 attention map을 controll한다.
Pretrain된 video genration model을 사용할 수 없으므로, 본 논문은 pretrain된 image diffusion model을 사용해서 detailed video editing을 하는 것을 보인다.

위 이미지에서 Image-P2P는 각 프레임에 독립적으로 pretrained image diffuion model을 사용한 결과이다. 이럴 경우 각 프레임에 대한 semantic consistency가 부족하다. Semantic consistency를 유지하기 위해서, 본 논문은 T2I를 Text-to-Set model(T2S)로 변환함으로써 모든 프레임에 대해서 attention controll과 inversion에 대한 structure를 사용하는 것을 제안한다.

본 논문은 Tune-A-Video라는 논문에서 제안한 방식을 적용해서 convolution kernel을 바꾸고 self-attention을 frame-attention으로 대체함으로써 T2I model을 T2S model로 변환한다. 이 방식으로 인해서 생성 퀄리티는 떨어지지만 orignal video에 대한 tuning 이후에 회복될 수 있다. Fig.3 (c)에서처럼 tuned T2S는 video에 대한 approximate inversion을 생성하는데 충분하다.
Inversion quality를 향상시키기 위해서, 본 논문은 denoising latent feature와 diffusion latent feature를 align하기 위해 모든 프레임들에 대해 shared unconditional embedding을 optimize하는 것을 제안한다. Fig. 3에서 볼 수 있듯이, 가장 효과적이고 효율적인 선택이다.
Initialized unconditional embedding으로의 approximate inversion은 editable하지만 reconstruction을 잘하지 않는다는 것을 발견했다. 그래서 본 논문은 이 문제를 해결하기 위해서, source prompt와 target prompt에 다른 guidance strategy를 활용하는 decoupled-guidance strategy in attention control을 제안한다. source prompt에 대해서는 optimized unconditional embedding을 사용하고 target prompt에 대해서는 initialized unconditional embedding을 사용한다. 이 두 가지에 대해서 attention map을 통합해서 target video를 생성한다.
2. Method

본 논문의 framework는 다음 두가지 key technical design을 지닌다.
- Video inversion을 위해 shared unconditional embedding을 optimizing한다.
- Source와 target prompt에 대해서 다른 guidance를 사용하고, 그들의 attention map을 통합한다.
2.1 Video Inversion
본 논문은 approximate inversion을 수행할 수 있는 T2S모델을 구성하는 것에서 시작한다. 본 논문의 다른 work처럼 $1 \times 3 \times 3$ pattern convolution kernel과 temporal attention을 사용한다. 또한 self-attention을 frame-attention으로 대체한다.

Frame-attention은 다음처럼 계산돼서 $v_0, v_i$를 input으로 받아서 $v_i$에 대한 feature를 update한다. 본 논문은 이 간단한 디자인이 reversed latent feature가 temporal information를 capture할 수 있기 때문에 video inversion에 충분하다고 한다.
Model inflation이 프레임에 대한 semantic consistency를 보존하는 것을 돕지만, T2I model의 생성 퀄리티에 영향을 끼친다. 이는 pre-train된적 없는 프레임 correlation을 계산되는데 self-attention parameter가 사용되기 때문이라고 한다. 이 문제를 해결하기 위해서, 본 논문은 frame과 cross attention, 추가적인 temporal attention의 query projection matrix $W^Q$를 finetuning한다. 이 후에는, T2S model이 각 프레임의 퀄리티는 유지하면서 semantically consistent image set을 생성할 수 있다.
Fine-tuning된 T2S model을 사용해서, 본 논문은 shared unconditional embedding을 optimize함으로써 video inversion을 수행한다. 본 논문은 DDIM inversion을 사용해서 latent feature $z^*_0, \cdots, z^*_T$를 생성한다. Unconditional embedding은 다음과 같이 정의되고 각 스텝마다 update된다.

T2S 모델의 frame-attention은 다음 스텝에서의 해당하는 feature를 계산하기 위해 두 latent feature를 사용한다. $varnothing_t$는 모든 프레임에 대해서 공유된다. 모든 프레임에 대해서 동일한 unconditional embedding을 사용하는 것은 attention control에서 semantic consistency를 불안정하게 하는 것을 막는다.
2.2 Decoupled-guidance Attention Control
Video inversion은 original video를 잘 reconstruction하는 inference pipeline을 만들도록 한다. 하지만 video로의 pretraining이 부족하기 때문에 T2I 모델처럼 robust하지 않다. 결국, editability는 optimized unconditional embedding에 의해서 제한되고, 이는 prompt를 바꿀 때 generation 퀄리티를 떨어뜨린다. 본 논문은 initialized unconditional embedding이 reconstruction을 완벽하게 못하지만 모델을 더 editable하게 만든다는 것을 발견했다. 그래서 source prompt에 대해서는 CFG에서 optimized unconditional embedding을 사용한다. 또 target prompt에 대해서는 initialized unconditional embedding을 사용한다. 그러고 나서 editing된 video를 생성하기 위해, 이 두 가지에서의 attention map을 통합한다.

Pseudo algorithm은 위와 같다. $M_t, M^*_t$는 cross-attention map을 나타낸다.$DM$은 tuned T2S model이다. $Edit$ function은 다음과 같다. (Word swap에 대한 예시)

$\bar{M}_{t,w}$는 $t$ 스텝에서 계산된 단어 $w$에 대한 average attention map이다. 계산은 다음과 같이 된다.

$B(\bar{M}_{t,w})$는 attention map을 통해 얻어진 binary mask로 threshold보다 크면 1의 값을 가진다.
3. Experiments
3.1 Implementation Details

3.2 Applications

Word swap, prompt refinement, attention re-weighting의 결과를 볼 수 있다.
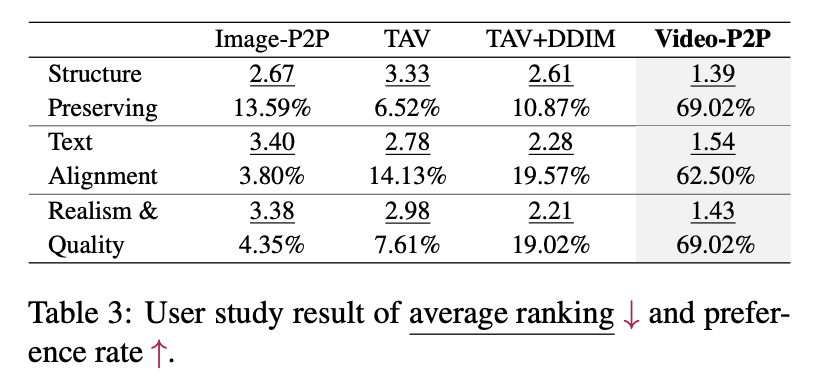
3.3 Comparison
Comparison with Tune-A-Video

Comparison with Dreamix

Video-P2P는 temporal prior의 부족때문에 video motion editing을 할 수 없지만, 디테일과 motion consistency를 보존하는 것에서는 Dreamix를 능가한다.
Quantitative results
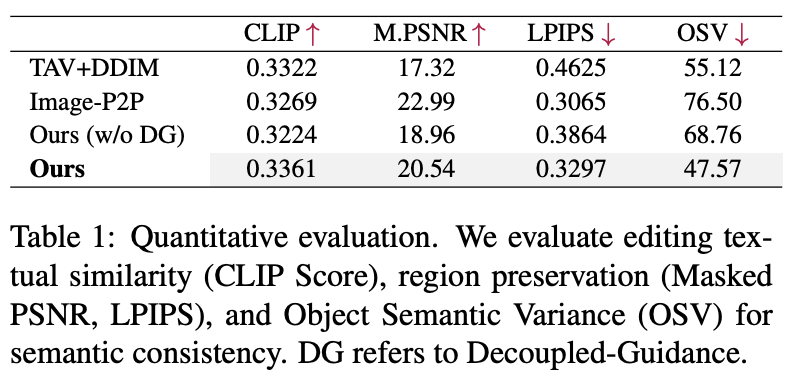
- CLIP score : text와 video간의 similarity
- Masked PSNR, LPIPS : structure preservation의 퀄리티
- Object Semantic Variance (OSV) : 프레임에 따른 semantic consistency
3.4 Ablation Study
Model initialization

직접적으로 inflated T2S model을 사용하는 것은 부정확한 background를 가진 unrealistic results를 생성한다. 이 문제를 완화하기 위해서, 본 논문은 주어진 video로 finetuning함으로써 T2S model을 initialize한다.
Shared unconditional embedding

Multiple unconditional embedding을 사용하는 것은 PSNR을 0.2밖에 못올리고 파라미터는 훨씬 많다. 또 attention control후에는 결국 shared unconditional embedding을 사용할 때 보다 PSNR이 떨어진다.
Decoupled-guidance attention control

Optimized unconditional embedding은 source prompt에만 적합하다. 그래서 target prompt에 사용하게 되면 생성 결과의 퀄리티를 낮출 수 있다.
4. Conclusion




