
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 프로그래머스
- inversion
- rectified flow matching models
- visiontransformer
- diffusion models
- unlearning
- Machine Unlearning
- rectified flow models
- flow matching
- BOJ
- video editing
- flow models
- flow matching models
- VirtualTryON
- ddim inversion
- diffusion
- image editing
- rectified flow
- image generation
- Python
- 3d editing
- 3d generation
- diffusion model
- 논문리뷰
- video generation
- Programmers
- 코테
- memorization
- 네이버 부스트캠프 ai tech 6기
- Concept Erasure
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] ControlNeXt: Powerful and Efficient Control for Image and Video Generation (arXiv 2408) 본문
[평범한 학부생이 하는 논문 리뷰] ControlNeXt: Powerful and Efficient Control for Image and Video Generation (arXiv 2408)
junseok-rh 2024. 11. 29. 17:02Paper : https://arxiv.org/abs/2408.06070
ControlNeXt: Powerful and Efficient Control for Image and Video Generation
Diffusion models have demonstrated remarkable and robust abilities in both image and video generation. To achieve greater control over generated results, researchers introduce additional architectures, such as ControlNet, Adapters and ReferenceNet, to inte
arxiv.org
Github : https://github.com/dvlab-research/ControlNeXt
GitHub - dvlab-research/ControlNeXt: Controllable video and image Generation, SVD, Animate Anyone, ControlNet, ControlNeXt, LoRA
Controllable video and image Generation, SVD, Animate Anyone, ControlNet, ControlNeXt, LoRA - dvlab-research/ControlNeXt
github.com
0. Abstract
최근 controllable generation method들은 종종 상당한 추가적인 computational resources를 필요로 하고, 학습에서 challenges를 직면하거나 weak control을 보인다. 그래서 본 논문에서는 ControlNeXt를 제안한다. 본 논문에서는 먼저 더 간단하고 효율적인 architecture를 디자인한다. 이러한 간단한 구조는 다른 LoRA weights에 매끄럽게 통합되게 하고 추가적인 training 없이 style alteration을 가능하게 한다. 또 Cross Normalization(CN)이라는 새로운 method를 제안해 zero convolution을 대체하여 빠르고 안전한 training convergence를 달성한다.
1. Introduction
최근 controllable generation method들로 ControlNet, T2I-Adapter, ReferenceNet등이 존재한다. 이 방식들은 text 뿐만 아니라 다른 extra condition을 통해 image를 생성한다. 이 방식들은 zero convolution과 cross attention을 이용해 conditional control을 한다.
하지만 이러한 operation들은 computational cost를 상당히 증가시키고 training challenge를 발생시킨다. GPU memory 사용량을 최대 2배로 늘리고, 학습에 대한 다수의 새로운 파라미터 도입을 필요로 한다. 게다가 zero convolution은 training challenge를 증가시키고 convergence를 느리게 하고 sudden convergence phenomenon을 야기한다.
본 논문은 controllable visual generation을 위한 powerful하지만 efficient한 method인 ControlNeXt를 제시한다.

본 논문은 ControlNet의 parallel control branch를 conditional control feature들을 추출하기 위한 가벼운 convolutional network로 대체했다. Training을 위해서는, pretrained 파라미터들의 매우 작은 subset을 선택적으로 학습했다. 이 접근법은 overfitting과 catastrophic fotgetting을 피하고 training 파라미터 수를 상당히 줄인다.
또한, 본 논문은 zero convolution을 대체하기 위해 Cross Normalization을 도입한다. 이는 data distribution들을 align하고, 이를 통해 더 효율적이고 안정적인 training process를 야기한다.
여러 실험들을 통해 ControlNeXt가 다양한 type의 conditional control과 network architecture에 대해 robust하고 compatible하다는 것을 보인다. 또, 적은 추가 component들을 도입해 기존 base model의 구조를 상당한 정도로 유지한다. ControlNeXt는 추가적인 학습 없이 style을 수정하기 위해 다른 LoRA weight에 통합될 수 있다.
Contribution을 요약하면 다음과 같다.

2. Method

2.1 Architecture Pruning
Motivation
ControlNet에 대한 포스팅 : https://juniboy97.tistory.com/52
[평범한 학부생이 하는 논문 리뷰] Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet)
이번 논문은 최종 프로젝트에서 메인으로 쓰일 ControlNet이다.프로젝트에 관한 포스팅은 여기에서 확인할 수 있다.Why ControlNet?본 논문에서 ControlNet을 왜 제시했을까? 일단 먼저 기존의 text-to-image g
juniboy97.tistory.com
ControlNet의 design은 control 능력을 도입하지만 상당한 cost를 발생시킨다. 추가적인 branch는 대략 50% latency를 증가시킨다. 이는 특히 video generation에서는 치명적이다. 게다가, trainable parameter는 양이 상당하고 fixed되어있다. 또한 ControlNet을 optimizing하는 것은 pretrained model에 영향을 끼치지 않기 때문에 전체 모델의 upperbound로 제한된다. 효율성과 명확성을 향상시키기 위해서, 본 논문은 먼저 추가적인 branch를 없앰으로써 ControlNet의 구조를 단순화한다. 그러고 나서 pretrained model의 선택된 subset을 학습시킨다. 이렇게 함으로써 더 효과적이고 효율적인 구조를 야기한다.
Architecture Pruning
Pretrained Model은 거대한 양의 data로 학습이 잘 됐기에, 본 논문에서는 pretrained large generation model은 유지하고 control generation 능력을 달성하기 위해 많은 양의 추가적인 parameter를 도입하는 것은 필요 없다고 생각한 것 같다.
그래서 본 논문은 control branch를 제거하고 이를 다수의 ResNet block들로만 구성된 가벼운 convolution module로 이를 대체한다. 이 module은 conditional control로부터 guidance 정보를 추출하고 denoising feature들과 align하도록 디자인됐다. 작은 사이즈덕분에, control signal을 처리하기 위해서 generation model 그 자체에 더 의존한다. 학습 동안에는 pretrained generation model로부터 trainable 파라미터들의 작은 subset을 선택적으로 최적화시킨다. 이 접근법은 forgetting에 대한 위험성을 최소화한다. 또한 이는 LoRA와 같은 parameter-efficient fine-tuning method들과도 결합될 수 있다. 그러나 본 논문에서는 original architecture에서 상당한 변화를 피함으로써 모델 구조의 consistency를 유지하도록 노력한다. 모델을 직접적으로 학습하는 것 또한 훨씬 더 큰 효과와 효율성을 이끈다. 그리고 다양한 task에 맞도록 learnable parameter들의 scale을 적응적으로 적용할 수 있다.

여기서 $\Theta^\prime_m \subseteq \Theta_m$은 pretrained parameter의 trainable subset이고, $\mathcal{F}_c$는 lightweight convolution module이다. 이 process를 통해 가능한한 추가적인 expense와 latency를 최소화하면서 모델의 consistency를 유지하려 한다.
대부분의 controllable generation task에 대해, control들은 간단한 형태를 지니거나 denoising feature들과 높은 수준의 consistency를 유지한다. 그렇기에 여러 stage들에 control을 주입할 필요가 없다. 본 논문은 control들을 Cross Normalization을 통해 normalization을 시킨 후에 denoising feature들에 직접 더함으로써 하나의 선택된 middle block에서 control들을 denoising branch와 통합한다. 이는 light weight convolution module과 learnable parameters로 구성된 plug-and-play module로 제공될 수 있다.

2.2 Cross Normalization
Motivation
Pretrained large model들의 continual training에서의 전형적인 문제는 '어떻게 적절하게 additional parameter들과 module들을 도입할 것인가?'이다. 기존에는 zero convolution과 같은 zero initialization 방식을 사용했다. 하지만 이러한 방식들은 module들이 loss function으로부터 정확한 gradient를 받는 것을 막기 때문에 느린 convergence를 야기하고 training challenge들을 증가시킨다. 또한 "sudden convergence"현상도 일으킨다.
Cross normalization
본 논문에서는 training collapse의 주요 이유는 pretrained model과 introduced module간의 data 분포의 unaligned와 incompatible이라는 것을 발견했다. Pretrained model은 안정적인 feature와 data 분포를 보여준다. 하지만 새롭게 도입되는 module은 gaussian initialization과 같이 weight가 initial되는데, 이는 평균과 분산이 상당히 다른 feature ouput을 생성한다. 이러한 feature들을 직접 더하거나 합치면 model instability를 야기한다.
그래서 본 논문에서는 conditional control과 main branch feature를 align해서 training 안정성과 속도를 보장하는 cross normalization을 제안한다. Cross Normalization의 key는 main branch $\mathbf{x}_m$로부터 평균과 분산을 구해 control feature $\mathbf{x}_c$를 normalization하는데 사용하는 것이다. 이를 통해 alignment를 보장한다.
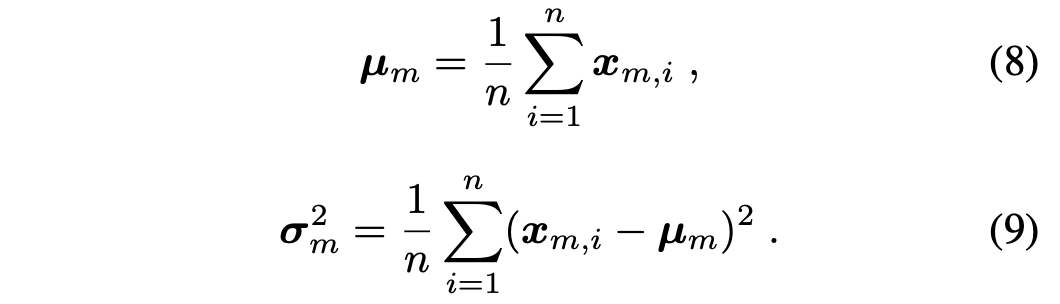
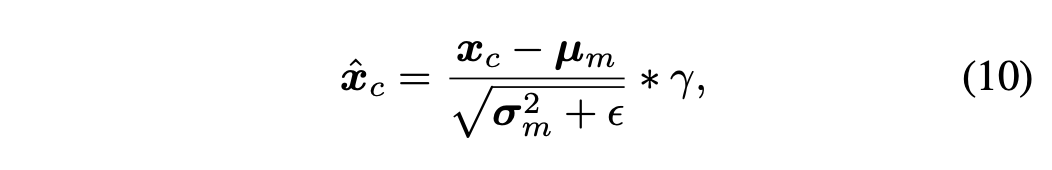
여기서 $\gamma$는 normalized value를 모델이 scale하도록 하는 파라미터이다. (모델이 학습하는 파라미터인 것 같다.)
Cross Normalization은 control feature와 denoising feature사이의 분포를 align해서, diffusion과 control feature를 연결하는 다리 역할을 한다. 이를 통해 training process를 가속화하고, training의 시작에서 조차 생성에 대한 control의 효과를 보장하고, 초기 weight에 대한 민감도를 줄인다.
3. Experiments
3.1 Generality
본 논문은 ControlNeXt의 robustnest와 generality를 보이기 위해, 여러 backbone에 대해서 실험을 진행했다.

다양한 task에 대한 qualitative results는 위 이미지에서 확인할 수 있다.
여러 모델을 backbone으로 해서 여러 condition에 대한 이미지 생성은 아래 이미지들에서 확인할 수 있다.



3.2 Training Convergence
Controllable generation의 전형적인 문제는 training convergence가 어렵다는 것이다. 그래서 conditional control을 위해서는 수천에서 만번의 iteration이 필요하다. 초기에 control 능력을 학습하는 것에 실패해서 sudden convergence라는 현상이 발생한다.
- Zero Convolution은 loss function의 영향을 억제해서 모델이 효율적으로 학습하기 시작하는 것을 방해하는 장시간의 warm-up phase를 야기한다.
- Pretrained generation model은 완전히 frozen되고 ControlNet은 모델에 즉시 영향을 끼칠 수 없는 adapter로 작동한다.
ControlNeXt는 위 두 가지 한계점을 제거해 상당히 빠른 학습 convergence를 보인다.

위 결과를 보면 ControNeXt는 수백번의 iteration만에 convergence를 보이는 반면 ControlNet은 수천번의 iteration을 지나야 convergence를 보인다.
3.3 Efficiency
Parameters
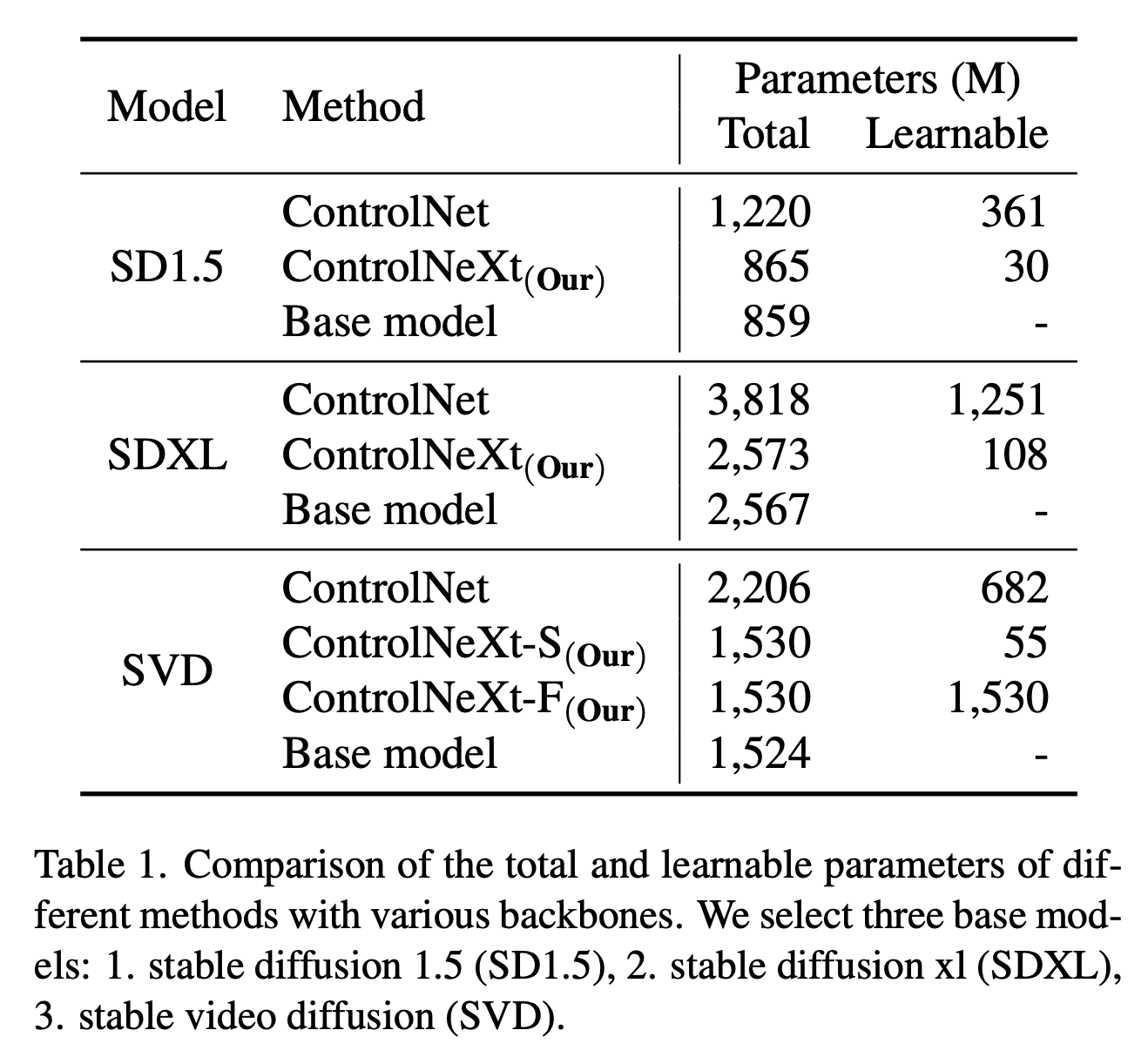
Inference Time

3.4 Plug-and-Play
Training free intergration

Stable generation




