
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- inversion
- Programmers
- visiontransformer
- video generation
- flow models
- ddim inversion
- diffusion
- 네이버 부스트캠프 ai tech 6기
- flow matching models
- flow matching
- image generation
- 3d editing
- 3d generation
- Concept Erasure
- 논문리뷰
- rectified flow
- Python
- memorization
- 프로그래머스
- image editing
- video editing
- diffusion models
- Machine Unlearning
- rectified flow models
- rectified flow matching models
- 코테
- VirtualTryON
- BOJ
- unlearning
- diffusion model
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code (ICLR 2024) 본문
[평범한 학부생이 하는 논문 리뷰] Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code (ICLR 2024)
junseok-rh 2025. 1. 8. 17:20Paper : https://arxiv.org/abs/2310.01506
Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code
Text-guided diffusion models have revolutionized image generation and editing, offering exceptional realism and diversity. Specifically, in the context of diffusion-based editing, where a source image is edited according to a target prompt, the process com
arxiv.org
Project Page : https://cure-lab.github.io/PnPInversion/
Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code
Text-guided diffusion models have revolutionized image generation and editing, offering exceptional realism and diversity. Specifically, in the context of diffusion-based editing, where a source image is edited according to a target prompt, the process com
cure-lab.github.io

1. Introduction
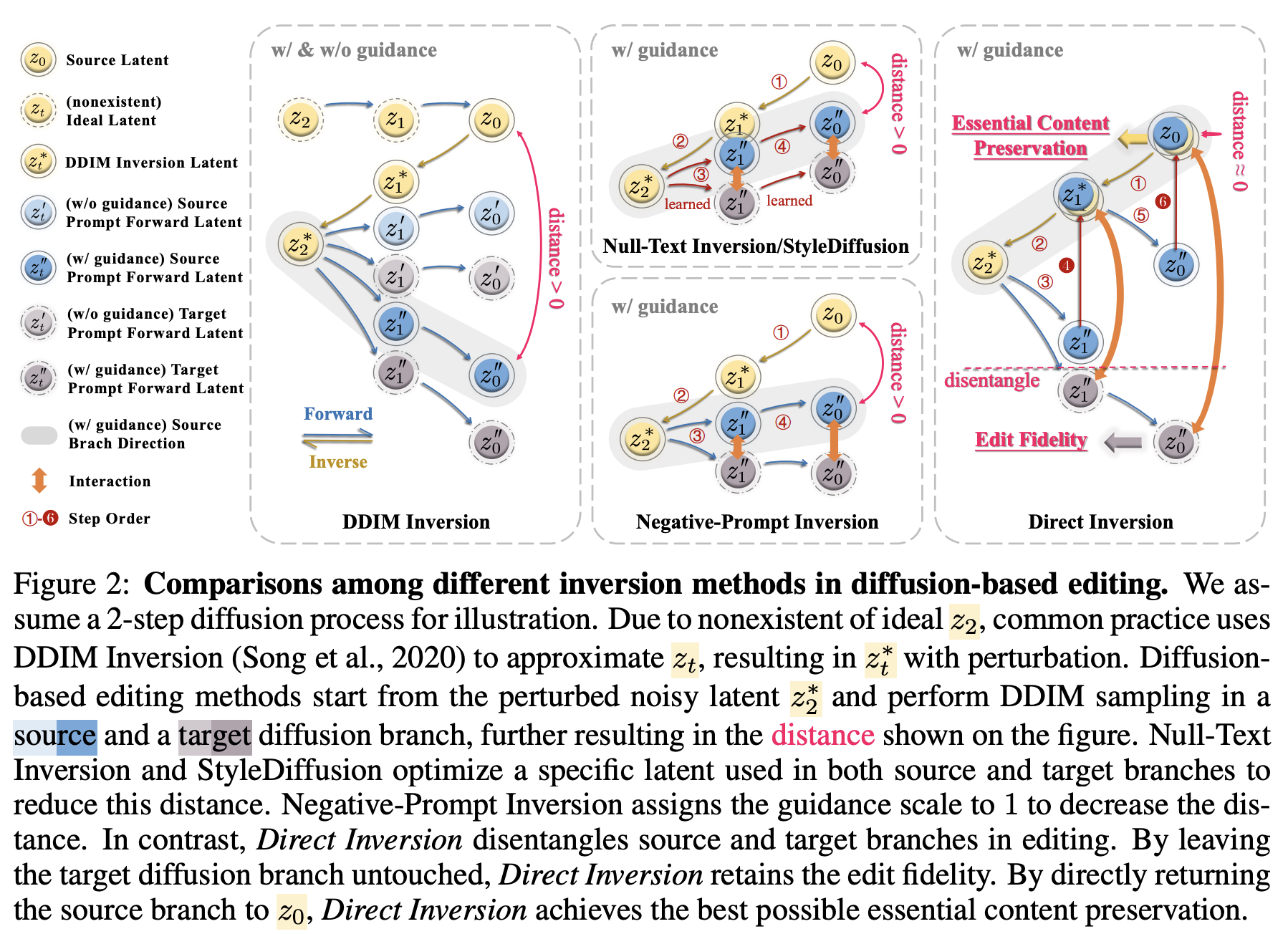
Image editing을 수행할 때, 그 image에 대한 latent space를 모르면 diffusion model을 inverting해서 latent vector를 얻어서 진행했다. 기존 Null-Text Inversion과 Negative-Prompt Inversion과 같은 optimization-based 방식들은 위 이미지와 같이 generation model의 input parameter를 간접적으로 조작함으로써 $z_0$와 $z^{''}_0$의 거리를 최소화하려 노력했다. 이러한 방식들은 target latent의 optimization을 단지 몇 번의 iteration으로 제한한다. 이는 결국 $z^{''}_0$와 $z_0$사이의 gap을 야기한다. 이러한 forced input assignment는 모델의 generation 능력을 방해하고, source와 editing branch의 integrity를 해친다.
본 논문은 기존의 exhaustive optimization이 optimal과는 거리가 있을 뿐만 아니라 실제로는 불필요하다는 것을 보인다. 본 논문은 Direct Inversion을 도입하면서 diffusion-based editing을 위한 간단하지만 강력한 inversion solution을 제공한다. Direct Inversion의 본질은 두 가지 주요 전략에 있다.
- Source와 target branch를 분리
- 각 branch가 preservation과 editing에서 탁월함을 보이도록 강화
특히, Direct Inversion에서 source branch는 이탈한 경로를 직접 수정한다. 이는 다음과 같은 기존 방법들의 문제들을 해결한다.
- 주요한 content preservation에 영향을 주는 바람직하지 않은 latent space distance
- 생성모델의 분포에 대한 misalignment
- 연장되는 processing time
Target branch에 대해서는, 변화를 주지 않고 target prompt에 대한 최상의 edit fidelity를 보장한다.
또한 본 논문에서는 PIE-Bench(Prompt-based Image Editing Benchmark)를 도입한다.
2. Method
2.1 Motivation
Why do optimization-based methods perform better among previous inversion methods?
Edit Friendly DDPM, Negative-Prompt Inversion, EDICT와 같은 inversion 기법들과 비교해서, optimization-based methods(Null-Text Inversion, StyleDIffusion)은 DDIM sampling에서 분포에 영향을 끼치지 않고, text condition들에 대한 충분한 guidance를 유지하고, diffusion model의 editability를 유지한다.
Are such optimizations indispensable and optimal for diffusion-based image editing?

Optimization-based inversion은 loss function $z_t^{''} - z_t^*$을 최소화함으로써 특정한 latent variable을 학습시켜, $z^{''}_t$를 $z^*_t$로 다시 수정하는 것이 target이다.
Source와 target branch에 대해서 unified variable의 optimizaton은 다음과 같은 몇 가지 문제를 야기한다.
- Inference동안에 process 시간이 늘어난다.
- Process time을 줄이기 위해서, 제한된 수의 iteration에 대해서만 target latent를 optimize하는 것을 선택한다. 이는 $z^{''}_0$와 $z_0$사이의 큰 gap을 가지는 learned latent space를 수반한다. (preservation 안좋아짐)
- Learned variable은 generation model의 input 파라미터 역할을 하고 이는 diffusion model의 기대되는 input 분포와 align되지 않는다. 그리고 이는 diffusion model integrity에 대해서 negative impact를 야기한다.
위 문제들은 practicality와 editability를 방해한다.
2.2 Method
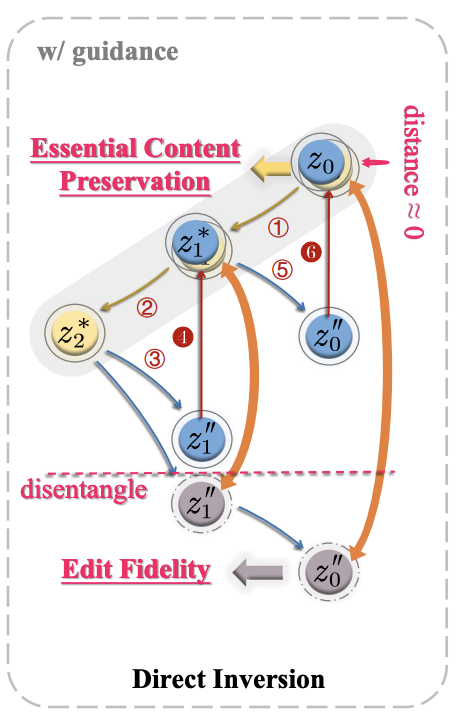
이러한 문제들을 고려해서, Direct Inversion을 제안한다. Direct inversion의 key는 source와 target branch를 분리(disentangle)하는 것이다. Source branch에 대해서는 직접적으로 $z_t^{''}$에 $z^*_t - z^{''}_t$를 다시 더해준다. 이는 deviation path를 직접적으로 수정할 수 있는 간단한 방식이며 다른 다양한 editing methods에 끼워 넣어질 수 있다. Target branch에 대해서는 그대로 놔두는 것이 target image generation에 대한 diffusion model의 potential을 최대화할 수 있다. 이 방식은 기존의 optimization-based inversion에 대한 세 가지 issue를 다음과 같이 해결한다.
- Optimization이 필요 없기 때문에 최소한의 추가적인 time overhead가 발생한다.
- $z^*_t - z^{''}_t$를 더하는 것은 $z^{''}_0$와 $z_0$사이의 discernible gap을 없앤다.
- Diffusion model의 input의 distribution에 대한 impact를 가지지 않는다.

전체적인 알고리즘은 위와 같다. 본 논문은 8번 줄에서 $z^{''}_{t-1} = z^*_{t-1}$를 하는 대신에 latent space에서 source prompt의 difference를 단지 더하고 $z^{''}_{t-1}$을 update한다. 이 부분이 target prompt의 latent space의 editability를 유지하는 key이다.
2.3 Benchmark Construction

3. Experiments
3.1 Evaluation Metrics
- Structure Distance
- Background Preservation (PSNR, LPIPS, MSE, SSIM)
- Edit Prompt-Image Consistency (CLIPSIM)
- Inference Time
3.2 Comparison with Inversion-Based Editing


3.3 Comparison with Essential Content Preservation Methods
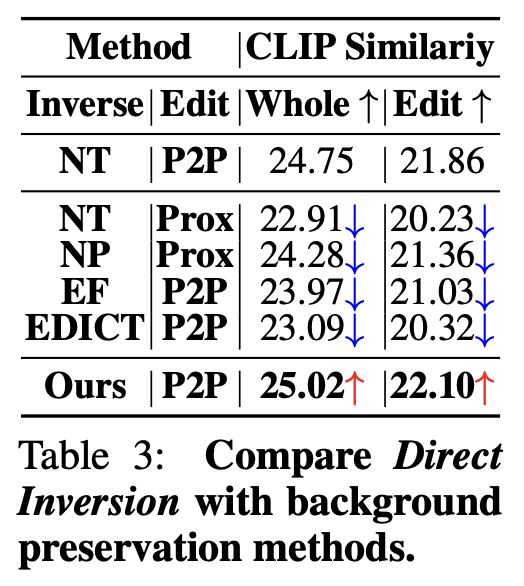
3.4 Comparing Direct Inversion and Null-Text Inversion
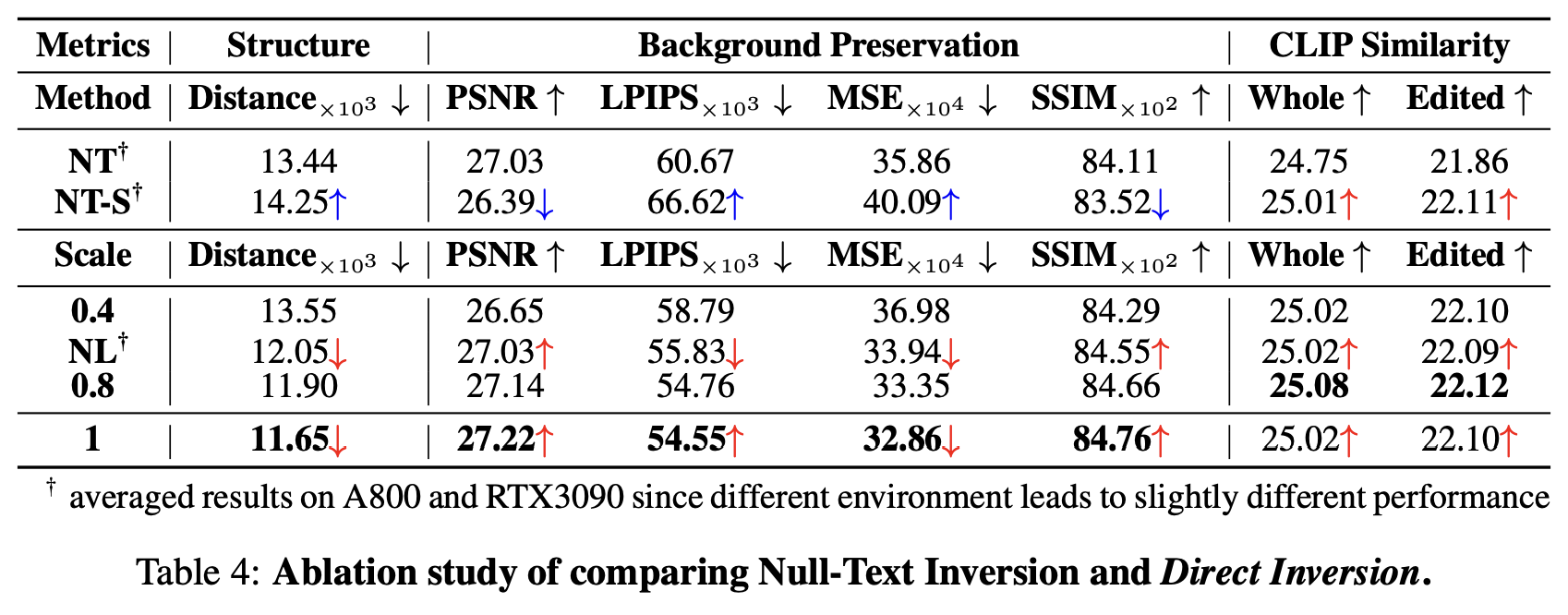
- NT-S : Null-Text Inversion에서 source branch에만 learned null-text latent 할당
- NL : source latent에 null-text embedding을 넣는 것 대신에 difference를 더함
- Scale : source latent에 scaled distance를 더함
3.5 Influence of Adding Difference to Target Latent

A. Quantitative Results
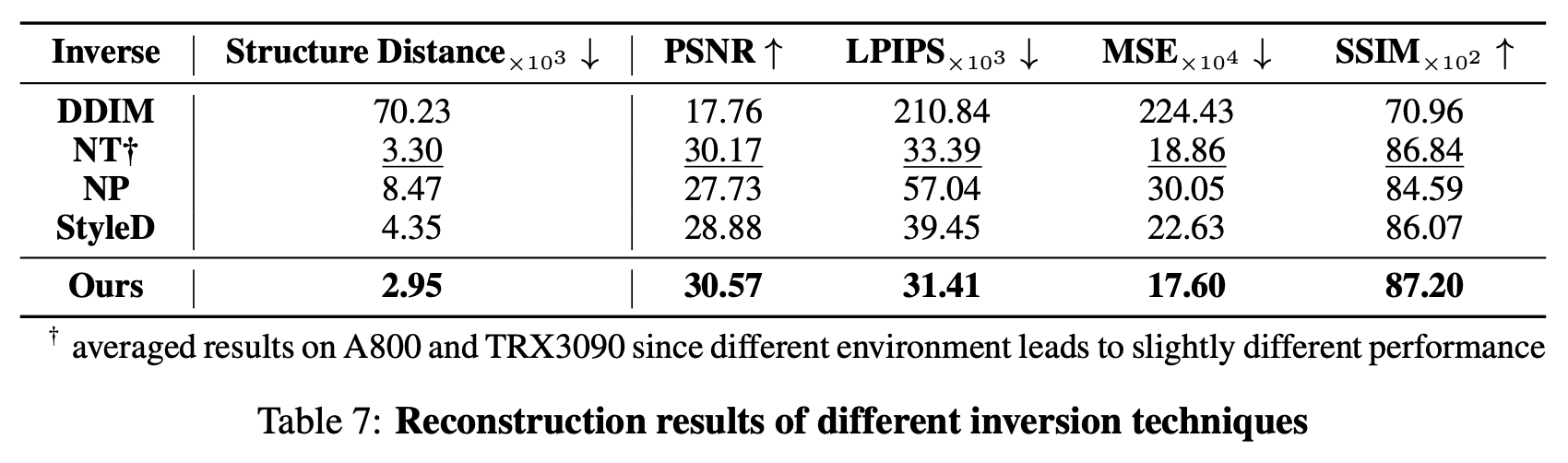
A.1 Reconstruction Ability of Different Inversion Methods
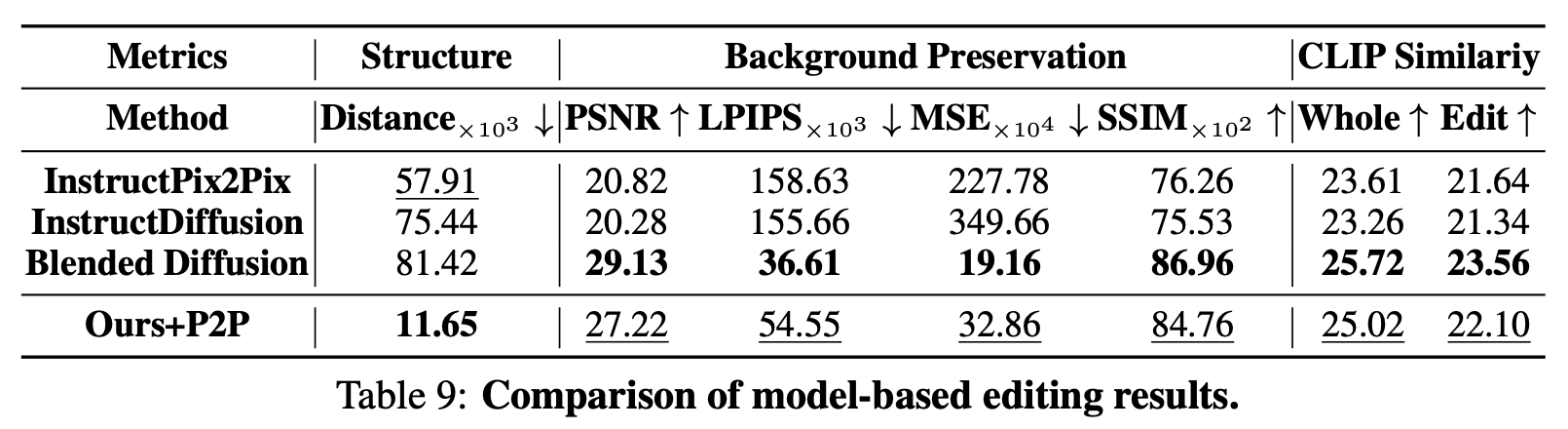
A.2 Comparison with Model-Based Editing
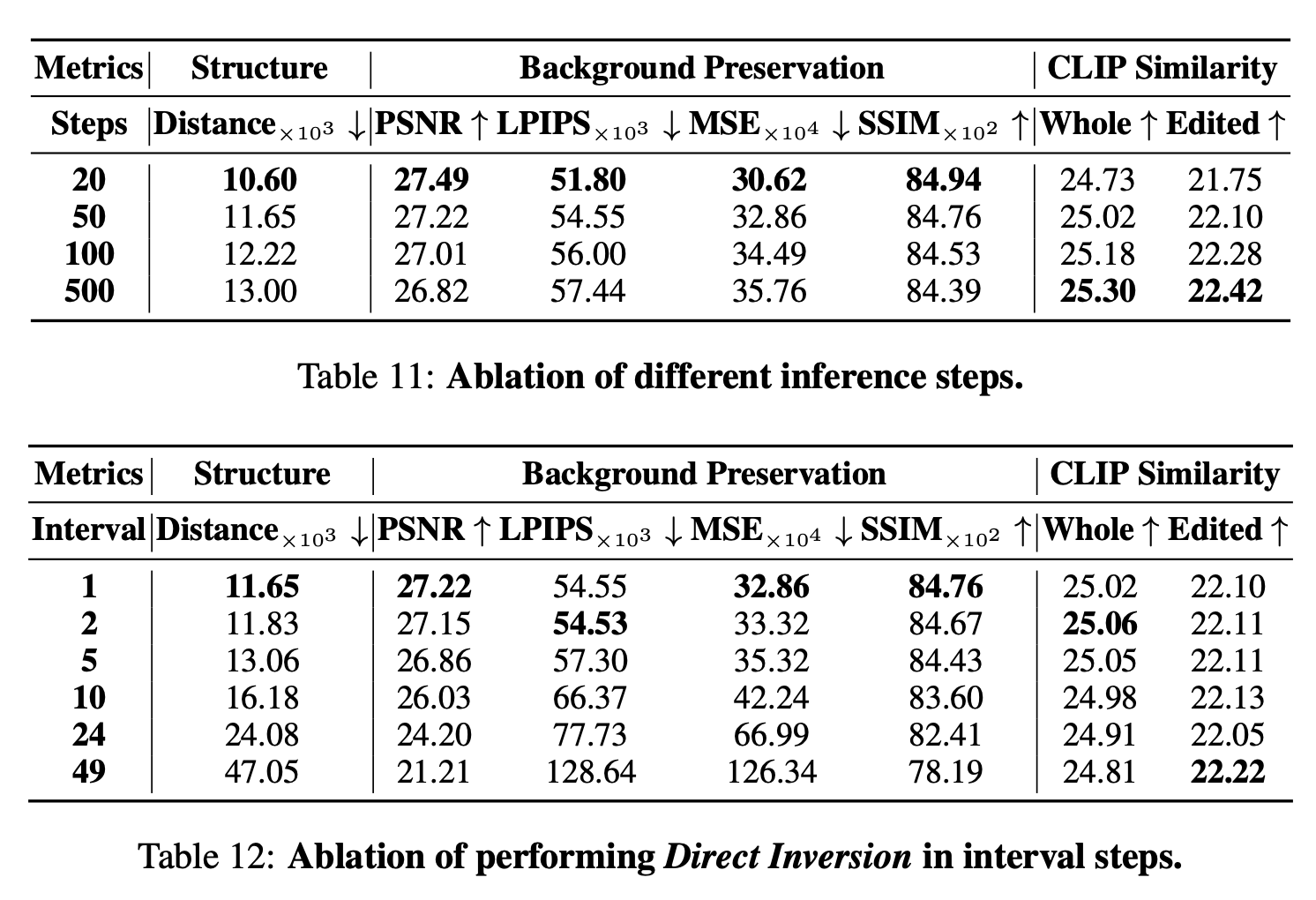
A.3 Ablation of Step of Interval
B. Limitations




