
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- DP
- 코테
- Programmers
- Vit
- 3d gaussian splatting
- transformer
- autoregressive
- Visual Autoregressive
- text-to-video diffusion
- novel view synthesis
- 프로그래머스
- 3d generation
- 네이버 부스트캠프 ai tech 6기
- 코딩테스트
- text2room
- objectdrop
- visiontransformer
- Python
- sound-to-image generation
- VirtualTryON
- instructany2pix
- sonicdiffusion
- BOJ
- magic clothing
- 논문리뷰
- insturctnerf2nerf
- dreamfusion
- text-to-image diffusion
- diffusion
- 3d editting
Archives
- Today
- Total
목록AI/Multimodal (1)
평범한 필기장
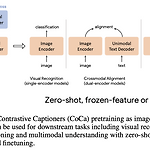 [평범한 학부생이 하는 논문 리뷰] CoCa : Contrastive Captioners are Image-Text Foundation Models
[평범한 학부생이 하는 논문 리뷰] CoCa : Contrastive Captioners are Image-Text Foundation Models
스터디 내에서 Vision Transformer를 공부하게 되었고 더 나아가 멀티모달 모델들에 대한 공부도 진행하게 되었다. 스터디에서 CoCa 논문을 발표하게 되었다. 그래서 발표 준비를 할 겸 블로그에 포스팅하게 되었다. https://arxiv.org/abs/2205.01917 CoCa: Contrastive Captioners are Image-Text Foundation Models Exploring large-scale pretrained foundation models is of significant interest in computer vision because these models can be quickly transferred to many downstream tasks. This p..
AI/Multimodal
2023. 11. 14. 14:30