

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- masactrl
- 네이버 부스트캠프 ai tech 6기
- Programmers
- 논문리뷰
- image editing
- video generation
- 코테
- visiontransformer
- DP
- VirtualTryON
- 3d editing
- diffusion model
- rectified flow
- Vit
- BOJ
- controlnext
- transformer
- diffusion models
- emerdiff
- Python
- diffusion
- segmentation map
- 프로그래머스
- 코딩테스트
- segmenation map generation
- score distillation
- flow matching
- dreammotion
- video editing
- 3d generation
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization 본문
[평범한 학부생이 하는 논문 리뷰] VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
junseok-rh 2023. 8. 2. 00:30최근에 Virtual Try-On이라는 분야에 관심을 갖게되면서 두번 째로 읽게 된 논문이 바로 VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization이라는 논문이다. 이 논문을 선택한 이유 중 하나는 바로 저자분들이 한국분들이라는 것이다. 특히 주재걸 교수님이 저자에 있어서 더 눈에 띄었다.
0. 기존 Virtual Try-On의 한계
Image-based Virtual Try-On은 주어진 인물사진에 대상 의상 아이템으로 변경한 이미지를 생성하는 모델이다. 기존 Virtual Try-On 모델들의 한계점은 바로 고해상도의 이미지를 만들 수 없다는 것이다. 해상도를 높일 수록 misaligned된 부분의 artifacts들이 더 두드러지게 보인다는 것이다. 그리고 기존 방식에서 사용되는 아키텍처는 고품질의 신체 부위를 생성하고 옷의 질감 선명도를 유지하는 데 성능이 낮다.
이러한 문제를 해결하기 위해서 이 논문의 저자들은 VITON-HD라는 모델을 개발했다!
1. Introduction
Virtual Try-on 모델을 통해 합성된 이미지는 아래와 같은 조건들을 만족해야 한다.
- 인물의 포즈, 체형, 신원이 보존되어야 한다.
- 인물의 포즈와 체형을 반영하여 해당 인물이 원하는 의상 부위에 자연스럽게 변형된 의류 제품이어야 한다.
- 의류 제품의 디테일은 그대로 유지되어야 한다.
- 원본 이미지에서 인물의 옷에 의해 가려진 신체 부위가 제대로 렌더링되어야 한다.
하지만 이런 조건들을 만족하기에는 쉽지 않다. 그리고 당시 나온 Virtual Try-On은 낮은 화질의 이미지만 생성이 가능했다. 그 이유로는 아래의 두 가지이다.
- Warped된 옷과 사람의 신체 사이의 misalignment는 misaligned 영역에 artifacts를 발생시키고 이미지 크기가 커질수록 눈에 띄게 된다.
옷 이미지를 신체에 완벽하게 맞도록 워핑하는 것은 어렵기 때문에 아래의 그림과 같이 misalignment가 발생한다.

- 기존 접근 방식에서 사용되는 단순한 U-Net 아키텍처는 초기에 가려진 신체 부위를 최종 고해상도 이미지로 합성하는 데 불충분하다.
고해상도 이미지를 생성하기 위해 단순한 U-Net 기반 아키텍처를 적용하면 불안정한 훈련과 생성된 이미지의 품질이 만족스럽지 못하고 이미지를 픽셀 단위로 한 번 refining하는 것만으로는 고해상도 의류 이미지의 디테일을 보존하기에는 부족하다고 한다.
이러한 한계점을 해결하기 위한 모델인 VITON-HD는 아래와 같은 contribution을 가진다.
- 고해상도의 이미지를 생성 가능.
- clothing-agnostic person representation을 도입하여 모델이 원래 착용한 옷에 대한 의존성을 제거할 수 있도록 함.
- ALIAS normalization과 ALIAS generator를 제안하고 이를 통해 misalignment 문제를 해결
- 새로운 데이터셋을 모아서 VITON-HD의 성능을 평가함
2. Proposed Method

위 이미지는 VITON-HD의 전체적인 구조를 나타낸 것이다. 위 모델은 기존 이미지 $I$와 의상 이미지 $c$, $c$를 입힌 합성 이미지 $\hat{I}$를 가지고 모델을 학습시키는 것이 간단하지만 데이터셋 구축이 힘들기에 $c$를 입은 이미지 $I$를 가지고 $(I,c,I)$를 쌍으로 모델을 학습시킨다.
하지만 $(I,c,I)$를 가지고 학습시키는 것은 모델의 일반화 능력을 해칠 수도 있기에 $c$를 입고있는 기준 이미지 $I$를 가지고 $c$를 입고있는 새로운 $I$를 합성해내 학습시킨다. 이러한 과정을 단계별로 좀 더 자세히 알아보자.
2.1 Clothing-Agnostic Person Representation
Virtyal Try-on에서는 이미 $c$를 착용한 $I$와 $c$의 쌍으로 모델을 훈련하기 위해 $I$에 의복 정보가 없는 person representation을 활용한다. 이러한 person representation은 아래와 같은 조건을 만족해야 한다.
- 대체할 원래의 의복 항목이 삭제되어야 함.
- 사람의 포즈와 체형을 예측할 수 있는 충분한 정보가 유지되어야 함.
- 사람의 신원을 유지하기 위해 보존할 영역(예: 얼굴과 손)이 유지되어야 함.

Problems of Existing Person Representation.
이미지에서 의류 정보를 완벽하게 제거하는 것은 매우 어려운 일이다. 그리고 이것이 테스트에서 문제를 발생시킨다.
Clothing-Agnostic Person Representation.
- $I_a$ : clothing-agnostic 이미지
- $S_a$ : clothing-agnostic segmentation map
Pre-trained된 network를 활용하여 이미지 $I$의 segmentation 맵 $S$와 포즈 맵 $P$를 예측한다. Segmentation 맵 $S$는 대체할 의류 영역을 제거하고 나머지 이미지를 보존하는 데 사용된다. 포즈 맵 $P$는 팔을 제거하는 데 사용된다 (손은 제외). $S$와 $P$를 기반으로 $I_a$와 $S_a$를 생성하여 모델이 원래의 의상 정보를 철저히 제거하고 나머지 이미지를 보존할 수 있도록 한다. 또한 각 채널이 하나의 키포인트에 대응하는 포즈 히트맵을 채택한 기존 작업과 달리, 골격 구조를 나타내는 RGB 포즈 맵 $P$에 $I_a$ 또는 $S_a$를 concat하여 생성 품질을 향상시킨다.(다음 과정에서 이용됨)
$I_a$를 생성할 때, 팔과 다리는 소매와 바지 기장과 같은 의복의 정보를 제공할 수 있으므로 제거해야한다. 해당 영역을 회색으로 마스킹하여 정규화된 이미지의 마스킹된 픽셀의 값이 0이 되도록 한다. 이러한 영역을 완전히 제거하기 위해 마스크에 패딩을 추가한다.
2.2 Segmentation Generation

Clothing-agnostic person representation $(S_a,P)$과 대상 의류 아이템 $c$가 주어지면, segmentation generator $G_S$는 참조 이미지에서 $c$를 착용한 사람의 segmentation 맵 $\hat{S}$를 예측한다. $S$와 $(S_a, P, c)$ 사이의 매핑을 학습하도록 $G_S$를 훈련시킨다.
Segmentation Generator의 loss function.
Segmentation genrator $G_S$는 clothing-agnostic segmentation 맵 $S_a$, 포즈 맵 $P$, 의류 아이템 $c$를 입력으로 사용하여($\hat{S} = G_S(S_a, P, c))$ 기준 이미지에서 대상 의류 아이템을 착용한 인물의 segmentation 맵 $\hat{S}$를 예측한다. Segmentation generator는 pixel-wise cross-entrophy loss $\mathcal{L}_{CE}$와 conditional adversarial loss인 LSGAN loss로 훈현된다. Segmentation generator에 대한 전체 손실 $\mathcal{L}_S$는 아래와 같다:
$\mathcal{L}_S = \mathcal{L}_{cGAN} + λ_{CE}\mathcal{L}_{CE} \quad (8)$
$\mathcal{L}_{CE} = - \frac{1}{HW} \underset{ k∈C,y∈H,x∈W}{\Sigma} S_{k,y,x}{\rm log}(\hat{S}_{ k, y,x})\quad (9)$
$\mathcal{L}_{cGAN} = \mathbb{E}_{(X,S)} [{\rm log}(D(X, S))] + \mathbb{E}_X[1 -{\rm log}(D(X, \hat{S}))], \quad (10)$
- $λ_{CE}$ : cross-entropy loss의 하이퍼파라미터, 실험에서는 $λ_{CE}$를 10으로 설정, 두 loss간의 상대적 중요도를 나타냄
- $S_{yxk}$, $\hat{S}_{yxk}$ : 채널 k의 좌표(x, y)에 해당하는 기준 이미지 $S$와 $\hat{S}$의 segmentation 맵의 픽셀 값, 기호 H, W, C는 $S$의 높이, 폭, 채널 수
- $X$는 생성기의 입력 $(S_a, P, c)$을 나타내고, $D$는 판별기를 나타냄
- 생성기와 판별기의 학습률은 0.0004
- $β_1 = 0.5, β_2 = 0.999$인 Adam optimizer를 채택
- 배치 크기 8로 200,000회 반복하여 훈련
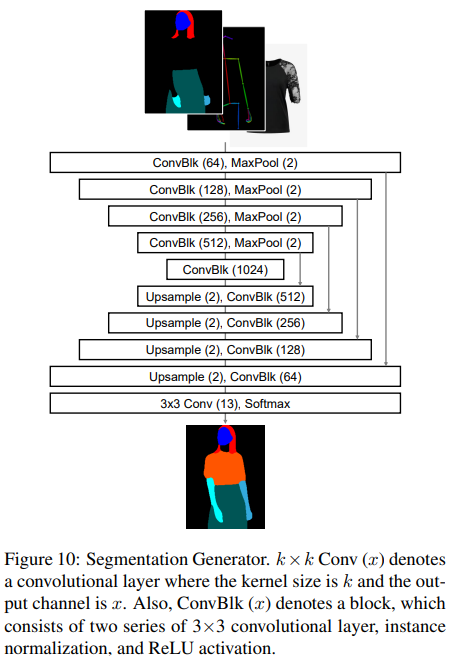
Segmentation generator의 architecture.
Segmentation generator는 컨볼루션 레이어, 다운샘플링 레이어, 업샘플링 레이어로 구성된 U-Net의 구조를 가지고 있다. 조건부 적대적 손실을 위해 두 개의 multi-scale discriminator가 사용된다.
2.3 Clothing Image Deformation
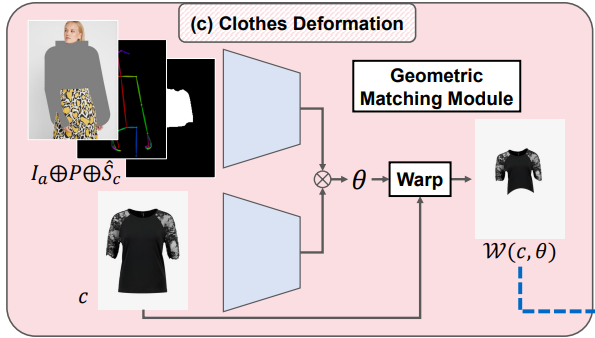
이 단계에서는 $\hat{S}$의 의류 영역인 $\hat{S}_c$에 align하기 위해 대상 의류 아이템 $c$를 변형한다. Clothing-agnostic person representation $(I_a, P)$과 $\hat{S}_c$를 입력으로 하여 CPVTON에서 제안한 geometric matching module을 사용한다.
Geometric Matching Module의 loss function.
훈련 단계에서 모델은 $\hat{S} c$ 대신 $S$에서 추출한 $S_c$를 사용한다. 모듈은 워핑된 옷과 $I$에서 추출한 옷 $I_c$ 사이의 $L_1$ 손실로 훈련된다. 또한 변형으로 인한 뒤틀린 옷 이미지의 뚜렷한 왜곡을 줄이기 위해 second-order difference constraint를 적용한다. 전체 loss function는 아래와 같다.
$\mathcal{L}_{warp} = ||I_c - \mathcal{W}(c, θ)||{1,1} + λ_{const}\mathcal{L}_{const}\quad (11)$
$\mathcal{L}_{const} = \underset{p∈P}{\Sigma} |(| ||pp_0||_2 - ||pp_1||_2| + | |pp_2||_2 - ||pp_3||_2|)\\ \quad \quad \ \ \ +(|S(p, p_0) - S(p, p_1)| + |S(p, p_2) - S(p, p_3)|),\quad (12)$
- $\mathcal{W}$는 $θ$를 사용하여 $c$를 변형하는 함수
- $I_c$는 참조 이미지 $I$에서 추출한 의류 아이템
- $\mathcal{L}_{const}$는 second-order difference constraint이며, $λ_{const}$는 $\mathcal{L}_{const}$의 하이퍼파라미터, 실험에서는 $λ_{const}$를 0.04로 설정
- $p$는 전체 control point 집합 $\mathbf{P}$에서 샘플링된 TPS control point를 나타내며, $p_0, p_1, p_2, p_3$은 각각 $p$의 상하좌우 지점을 의미
- 함수 $S(p, p_i)$는 $p$와 $p_i$ 사이의 기울기를 나타낸다.
- 학습률은 0.0002, $β_1 = 0.5, β_2 = 0.999$의 Adam optimizer를 채택, 배치 크기 8로 50,000회 반복하여 훈련
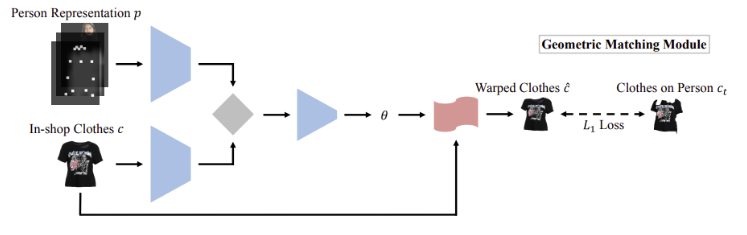

- CPVTON
먼저 $(I_a, P)$에서 추출된 특징과 $c$ 사이의 correlation 행렬을 계산한다. Correlation 행렬을 입력으로 사용하여 regression 네트워크는 TPS transformation 매개 변수 $θ ∈ \mathbb{R}^{ 2×5×5}$ 를 예측한 다음 $θ$에 의해 $c$는 워핑된다.
CPVTON 논문을 읽어보진 않았지만 이 논문에서는 이런 식으로 Geometric matching module이 작동된다고 설명하고 있다. VITON 과 다르게 따로 feature extractor를 쓰지 않았고, 직접적으로 L1 loss를 주기 때문에 좀 더 warping 된 옷의 형체과 사람의 몸과 잘 맞춰지도록 했다라고도 설명되어 있다.

Geometric Matching Module의 architecture.
Geometric matching module은 두 개의 feature extractor와 regression network로 구성다. 추출된 두 개의 특징으로부터 correlation matrix를 계산하고, regression network는 correlation matrix를 통해 TPS 파라미터 $θ$를 예측한다. Feature extractor는 일련의 컨볼루션 레이어로 구성되며, regression network는 일련의 컨볼루션 레이어와 fully connected 레이어로 구성된다.
2.4 Try-On Synthesis via ALIAS Normalization

이번 단계에서는 이전 단계의 output들을 기반으로 최종 합성 이미지 $\hat{I}$를 생성하는 것을 목표로 한다. 전체적으로 clothing-agnostic person representation $(I_a, P)$과 뒤틀린 옷 이미지 $\mathcal{W}(c, θ)$를 $\hat{S}$에 따라 융합한다. $(I_a, P, \mathcal{W}(c, θ))$를 제너레이터의 각 레이어에 주입한다. $\hat{S}$을 위해, ALIAS(ALIgnment-Aware Segment) 정규화라는 새로운 조건부 정규화 방법을 제안한다. ALIAS 정규화를 사용하면 의미 정보를 보존하고 $\hat{S}$와 해당 영역의 마스크를 활용하여 misaligned된 영역에서 misleading 정보를 제거할 수 있다.
Alignment-Aware Segment Normalization.
$h^i ∈ \mathbb{R}^{ N×C^i×H^i×W^i}$를 $N$개의 샘플 배치에 대한 네트워크의 $i$번째 레이어의 activation으로 나타낸다 (여기서 $H^i, W^i$ 및 $C^i$는 각각 $h^i$의 높이, 너비 및 채널 수를 나타냄).
ALIAS 정규화에서의 두 가지 input
- 합성 segmentation 맵 $\hat{S}$
- 대상 의류 이미지의 warped mask $\mathcal{W}(M_c, θ)$를 $\hat{S}_ c$에서 제외한 misaligned binary mask $M_{misalign}$ ($M_c$ : 대상 의류 마스크)
$M_{align} = \hat{S}_ c ∩ \mathcal{W}(M_c, θ)\quad (3)$
$M_{misalign} = \hat{S}_c - M_{align}. \quad (4)$

먼저 식 (3)과 식 (4)에서 $M_{align}$과 $M_{misalign}$을 얻는다. 이를 이용해 $\hat{S}_{div}$를 $M_{align}$과 $M_{misaling}$, $S_a$를 cancat한 것으로 정의한다. ALIAS normalization는 $M_{misalign}$ 영역과 $h^i$의 다른 영역을 개별적으로 표준화한 다음 $\hat{S}_{div}$에서 추론된 아핀 변환 파라미터($\gamma,\beta$)를 사용하여 표준화된 activation을 modulate한다.
Site($n ∈ N, k ∈ C^i , y ∈ H^i, x ∈ W^i$)에서의 activation 값은
$$γ^i_{k,y,x}(\hat{S}_{div})\frac{ h^i_{ n,k,y,x} - µ^{i,m}_{ n,k}}{ σ^{i,m}_{ n,k}} + β^i_{k,y,x}(\hat{S}_{div}),\quad (5)$$
로 계산된다.
- $h ^i_{ n, k,y,x}$ : 정규화 전 site에서의 activation
- $γ ^i_{ k,y,x}$ , $β^i_{k,y,x}$ : $\hat{S}_{div}$를 정규화 레이어의 modulation 파라미터로 변환하는 함수
- $µ^{ i,m}_{ n,k}$ , $σ^{ i,m}_{ n,k}$ : 샘플 $n$ 및 채널 $k$에서 활성화의 평균 및 표준 편차
$µ^{i,m}_ {n,k}$ 및 $σ^{i,m}_{ n,k}$는 다음과 같이 계산된다.
$$µ^{i,m}_{ n,k} = \frac{1}{ |Ω^{ i,m}_n |} \underset{ (y,x)∈Ω ^{i,m}_n }{\Sigma}h^ i_{ n,k,y,x}\quad (6)$$
$$σ^{i,m}_{ n,k} = \sqrt{\frac{1}{ |Ω ^{i,m}_{ n} |} \underset{(y,x)∈Ω ^{i,m}_{n}}{\Sigma} (h ^i_{ n,k,y, x} - µ ^{i,m}_{ n,k} )^2},\quad (7)$$
- $Ω ^{i,m}_ n$ : $M_{misalign}$ 또는 다른 영역인 영역 $m$의 픽셀 집합을 나타냄.
- $|Ω ^{i,m}_ n |$ : $Ω ^{i,m}_ n$ 의 픽셀 수
Instance Normalization과 유사하게 activation은 채널별로 표준화된다. 그러나 ALIAS normalization은 채널 $k$의 activation을 misaligned된 영역의 activation과 다른 영역의 activation으로 나눈다.
이 전략의 근거는 misaligned 영역에서 misleading 정보를 제거하기 위한 것이다. 구체적으로, 뒤틀린 의류 이미지의 misaligned 영역은 의류 텍스처와 무관한 배경과 일치하고 이러한 영역에 대해 별도로 표준화를 수행하면 최종 결과물에서 artifacts를 유발하는 배경 정보를 제거할 수 있다. Modulation에서는 segmentation 맵에서 추론된 아핀 파라미터가 표준화된 activation을 modulate합니다. 각 ALIAS 정규화 레이어에 semantic 정보를 주입하기 때문에 최종 결과에서 human parsing 맵의 레이아웃이 유지된다. 수식을 보면 AdaIN에서 style transfer를 하는 방식과 유사한데 misalign된 부분은 옷이 아닌데 옷으로 잘못 align됐고 그 부분을 배경 style로 transfer하면 더 자연스러운 이미지를 생성할 수 있다고 이해하면 쉬울 것 같다.
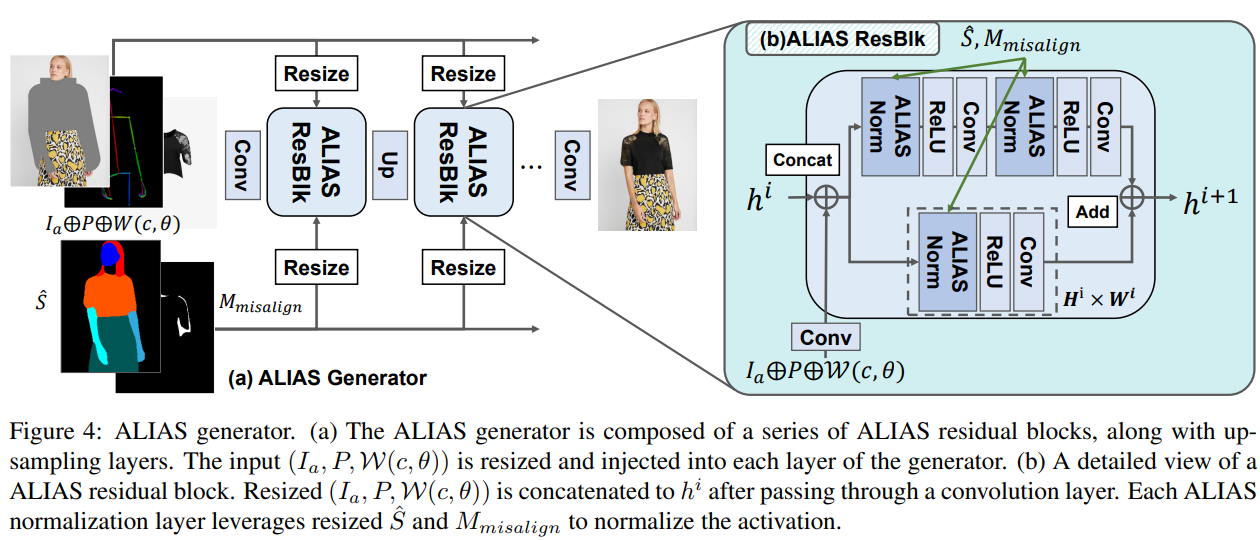
ALIAS generator.
제너레이터는 업샘플링 레이어와 함께 일련의 residual 블록(ResBlk)을 사용한다. 각 ALIAS ResBlk은 3개의 컨볼루션 레이어와 3개의 ALIAS 정규화 레이어로 구성된다. ResBlk가 작동하는 해상도가 다르기 때문에 각 레이어에 주입하기 전에 normalization 레이어인 $\hat{S}$ 및 $M_{misalign}$의 입력 크기를 조정한다. 마찬가지로 제너레이터의 입력인 $(I_a, P, \mathcal{W}(c, θ))$도 다른 해상도에 맞게 크기를 조정한다. 각 ResBlk 전에 크기가 조정된 입력 $(I_a, P, \mathcal{W}(c, θ))$은 컨볼루션 레이어를 통과한 후 이전 레이어의 activation에 연결되고, 각 ResBlk는 연결된 입력을 활용하여 activation을 refine한다. 이러한 방식으로 네트워크는 픽셀 수준에서 단일 refinement보다 의류 디테일을 더 잘 보존하는 feature 수준에서 multi-scale refinement를 수행한다. 조건부 적대적 손실, featur matching loss, perceptual loss로 ALIAS generator를 훈련한다.
ALIAS generator의 loss function.
ALIAS generator의 손실 함수는 conditional adversarial loss $\mathcal{L}_{cGAN}$, feature matching loss $\mathcal{L}_{FM}$, perceptual loss $\mathcal{L}_{percept}$를 포함한다. Generator의 전체 손실 $\mathcal{L}_I$는 아래와 같다.
$$\mathcal{L}_I = \mathcal{L}_{cGAN} + λ_{FM}\mathcal{L}_{FM} + λ_{percept}\mathcal{L}_{percept}\quad (13)$$
$$\mathcal{L}_{cGAN} = \mathbb{E}_I [{\rm log}(D_I (S_{div}, I))] + \mathbb{E}_{(I,c)} [1 - {\rm log}(D_I (S_{div}, \hat{I}))]\quad (14)$$
$$\mathcal{L}_{FM} = \mathbb{E}_{(I, c)} \underset{i=1}{\overset{T}{\Sigma}}\frac{1}{ K_i} [||D^{(i)}_ I (S_{div}, I) - D^{(i)}_ I (S_{div}, \hat{I})||_{1,1}]\quad (15)$$
$$\mathcal{L}_{percept} = \mathbb{E}_{(I,c)} \underset{i=1}{\overset{V}{\Sigma}}\frac{1}{R_i} [||F^{(i)} (I) - F^{(i)} ( \hat{I})||_{1,1}],\quad (16)$$
- $λ_{FM}$ 및 $λ_{percept}$는 하이퍼 파라미터, 실험에서는 $λ_{FM}$과 $λ_{percept}$를 모두 10으로 설정
- $T$는 $D_I$ 의 레이어 수이고, $D^{(i)}_ I$ 및 $K_i$는 각각 $D_I$ 의 $i$ 번째 레이어에 있는 activation 및 요소 수
- $V$는 VGG 네트워크 $F$에서 사용되는 레이어 수
- $F^{(i)}$ 및 $R_i$는 각각 $F$의 $i$ 번째 레이어에 있는 activation 및 요소 수
- 표준 adversarial loss를 Hinge loss로 대체
- 생성기와 판별기의 학습률은 각각 0.0001과 0.0004, $β_1 = 0, β_2 = 0.9$인 Adam optimizer를 채택, 배치 크기를 4로 설정하고 200,000회 반복 훈련

ALIAS Genenrator의 architecture.
ALIAS generator의 아키텍처는 nearest-neighbor 업샘플링 레이어를 가진 일련의 ALIAS ResBlk로 구성된다. 인스턴스 정규화와 함께 두 개의 multi-scale discriminator를 사용다. Spectral 정규화는 모든 컨볼루션 레이어에 적용된다. 처음 5개의 ALIAS ResBlk에서만 Misaligned 마스크 $M_{misalign}$에 기반한 activation을 별도로 표준화한다.
3. Experiments
3.1 Experiments Setup
Dataset.
- 1024×768의 Virtual Try-on 데이터셋을 수집하였다.(기존 데이터셋은 해상도가 낮음)
- 사람과 의류 이미지의 쌍을 사용하여 paired setting을 평가하고, unpaired setting을 위해 의류 이미지를 섞어 평가한다.
- Paired setting : 사람 이미지를 원래의 의류 아이템으로 재구성하는 것
- Unpaired setting : 사람 이미지의 의류 아이템을 다른 아이템으로 변경하는 것
Training and Inference.
$(I_a, c)$에서 $I$를 재구성하는 것을 목표로 각 단계의 학습은 개별적으로 진행된다.
- Geometric matching module과 ALIAS generator를 훈련하는 동안에는 $\hat{S}$ 대신 $S$를 사용.
- Segmentation generator와 geometric matching module은 256×192로 훈련.
- Inference 단계에서는 segmentation generator가 256×192로 예측한 후 segmentation 맵을 1024×768로 업스케일링하여 다음 단계로 전달.
- Geometric matching modul은 256×192에서 TPS 파라미터 $θ$를 예측하고, 파라미터 $θ$에 의해 변형된 1024×768 의류 이미지가 ALIAS generator에서 사용. (이 접근 방식이 1024×768로 훈련된 모듈보다 더 낮은 메모리 비용으로 더 나은 성능을 발휘)
3.2 Qualitative Analysis


Comparison with Baselines.
왼쪽 이미지는 VITON-HD가 baseline들과 비교했을 때 1024×768 이미지가 더 지각적으로 설득력 있게 생성된다는 것을 보여준다. 로고와 옷의 질감 등 디테일을 명확하게 보존하고, reference 이미지에서 인물이 어떤 옷을 입고 있든 상관없이 자연스럽게 체형을 합성한다. 오른쪽 이미지에서 볼 수 있듯이 ACGPN이 생성한 합성 segmentation 맵에는 원본 옷의 모양이 그대로 남아 있는 반면 VITON-HD의 segmentation generator는 원본 의류 아이템과 상관없이 segmentation 맵을 성공적으로 예측한다.

Effectiveness of the ALIAS Normalization.
원래의 인스턴스 정규화에서와 같이 채널별 표준화로 대체된 VITON-HD(with out ALIAS norm)와 논문의 모델을 비교하여 ALIAS 정규화의 효과를 비교한다. 위의 이미지는 ALIAS normalization이 잘못된 정보를 제거하여 misaligned된 영역을 대상 의류 텍스처로 채우는 기능을 가지고 있음을 보여준다. 반면, ALIAS normalization을 사용하지 않으면 뒤틀린 의류 이미지의 배경 정보가 제거되지 않기 때문에 misaligned된 영역에 artifacts가 생성된다.
3.3 Quantitative Analysis
Paired setting에서는 structural similarity(SSIM)와 the learned perceptual image patch similarity(LPIPS)를 사용하고, unpaired setting에서는 FID score를 채택한다. 각 모델의 입력에는 segmentation 맵을 재구성하는 데 이점을 제공하는 서로 다른 양의 정보가 포함되어 있으므로 pairing setting에서는 합성 segmentation 맵 대신 테스트 세트의 segmentation 맵을 사용한다.
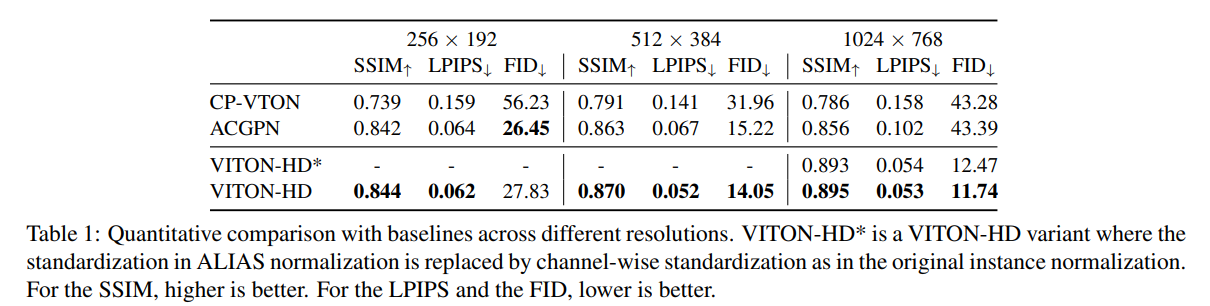
Comparison across Different Resolutions.
위 표에 표시된 것처럼 다양한 해상도에서 baselines와 정량적으로 비교했다. 논문의 모델은 모든 해상도에 대해 SSIM 및 LPIPS가 baselines보다 우수하게 나왔다. FID 점수의 경우, 논문의 모델은 해상도에 관계없이 CP-VTON을 크게 능가한다. 256×192 해상도에서는 ACGPN의 FID 점수가 저희 모델보다 약간 낮다. 그러나 1024×768 해상도에서는 우리 모델이 ACGPN보다 큰 차이로 더 낮은 FID 점수를 획득했다. 이 결과는 baseline은 1024×768 이미지를 처리할 수 없는 반면, 우리 모델은 고해상도에서도 안정적으로 훈련된다는 것을 나타낸다. 이는 baseline 모델에 사용된 U-Net 아키텍처의 제한된 기능 때문일 수 있다.

Comparison According to the Degree of Misalignment.
Misaligned 영역을 의류 텍스처로 채우는 기능을 검증하기 위해 misalignment 정도에 따라 paired setting에서 실험을 수행했다. Misaligned 영역의 픽셀 수에 따라 테스트 데이터셋을 소형, 중형, 대형의 세 가지 유형으로 나눴다. 공정한 비교를 위해 각 모델은 정렬이 잘못된 영역을 일치시키기 위해 동일한 segmentation 맵과 동일한 뒤틀린 옷을 입력으로 사용한다. 참조 이미지와 재구성된 이미지 사이의 semantic 거리를 측정하기 위해 LPIPS를 평가한다. 위의 이미지에서 볼 수 있듯이 misalignment 영역이 넓을수록 모델의 성능이 저하되며, 이는 misalignment가 모델이 실제와 같은 가상 착장 이미지를 생성하는 데 방해가 된다는 것을 의미한다. Baselines와 비교했을 때, 우리 모델은 일관되게 더 나은 성능을 보였으며, misalignment 정도가 커질수록 모델 성능의 감소폭이 줄어드는 것을 확인할 수 있다.
4. Conclusion
Photo-realistic 1024×768 virtual try-on 이미지를 합성하는 VITON-HD를 제안했다. 제안한 ALIAS normalization은 misaligned된 영역을 적절히 처리하고, 다중 스케일 정제를 통해 옷의 디테일을 보존하는 ALIAS 생성기 전체에 시맨틱 정보를 전파할 수 있다. 정성적, 정량적 실험을 통해 VITON-HD가 기존의 virtual try-on 방식을 큰 차이로 능가함을 입증했다.
4.1 Failure Cases and Limitations

위 이미지는 segmentation 맵이 부정확하게 예측되거나 옷깃 안쪽 영역이 다른 의류 영역과 구분되지 않아 발생한 모델의 실패 사례를 보여준다.
이 모델의 한계는 다음과 같다. VITON-HD는 아래쪽 의류 항목을 보존하도록 학습되어 대상 의류의 표현(예: 집어넣었는지 여부)이 제한된다. 다음으로, 데이터 세트는 대부분 날씬한 여성과 상의 이미지로 구성되어 있기 때문에 추론 과정에서 VITON-HD는 제한된 범위의 체형과 의상만 처리할 수 있다. 마지막으로, VITON-HD를 포함한 기존의 virtual try-on 방식은 실제 착용 이미지에 대한 강력한 성능을 제공하지 못한다.
Virtual Try-on 분야의 두번 째 논문이였는데 아직 모르는 것들이 많아 논문 리뷰가 많이 부족한 것 같다. 그래도 관심 분야다 보니 꾸준히 팔로우할 것 같다. 이 논문을 읽고 나니 앞으로 최신 모델들에 대한 기대감이 커졌다.
아직 많이 부족한 학부생이다 보니 많은 피드백을 주시면 감사하겠습니다!!



