
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python
- DP
- visiontransformer
- flipd
- video editing
- 논문리뷰
- inversion
- 코테
- image editing
- diffusion
- segmentation map
- 프로그래머스
- diffusion models
- video generation
- 코딩테스트
- VirtualTryON
- transformer
- diffusion model
- noise optimization
- BOJ
- 네이버 부스트캠프 ai tech 6기
- Vit
- masactrl
- Programmers
- memorization
- flow matching
- 3d generation
- 3d editing
- rectified flow
- segmenation map generation
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Magic Clothing : Controllable Garment-Driven Image Synthesis 본문
[평범한 학부생이 하는 논문 리뷰] Magic Clothing : Controllable Garment-Driven Image Synthesis
junseok-rh 2024. 5. 1. 16:29https://arxiv.org/abs/2404.09512
Magic Clothing: Controllable Garment-Driven Image Synthesis
We propose Magic Clothing, a latent diffusion model (LDM)-based network architecture for an unexplored garment-driven image synthesis task. Aiming at generating customized characters wearing the target garments with diverse text prompts, the image controll
arxiv.org
1. Introduction
본 논문의 주 contribution을 요약하면 다음과 같다.
- Magic Clothing은 garment-driven image synthesis task를 연구한 첫 LDM-based 작업이다.
- 본 논문에서 제안한 garment extractor는 self-attention fusion을 통해 garment feature를 denoising process에 통합한다. 그리고 joint classifier-free guidance는 garment features와 text prompt의 제어에 균형을 맞추기 위해 적용된다.
- 본 논문의 garment extractor는 plug-in module로 다양한 finetuned LDM에 적용할 수 있다. (ControlNet, IP-Adapter)
- Target image와 source garment의 일관성을 평가하기 위해 MP-LPIPS라는 robust metric을 제안한다.
2. Method
2.1 Preliminary
본 논문의 접근 방식은 VQ-VAE, CLIP VIT-L/14, denoising UNet으로 구성된 LDM framework를 베이스로 한다.
- VQ-VAE : image를 image latent로 압축하는 E, 다시 복원하는 D
- CLIP VIT-L/14 : original text prompt를 token embedding Ty로 변환하는 T
- denoising Unet : noise latent zt, timestep t, token embedding Ty가 주어지면 noise ϵ을 예측하는 ϵθ
최적화 프로세스는 아래의 loss function을 최소화함으로써 수행된다.

2.2 Network Architecture
훈련동안, VAE encoder E를 이용해 character image IC∈R3×H×W와 garment image IG∈R3×H×W를 image latents zC,zG∈R4×H8×W8로 변환한다. 반면 BLIP을 이용해 IC를 text prompt y를 얻고 token embedding Ty로 변환하기 위해 caption한다. 세세한 garment feature들을 추출하기 위해 denoising UNet과 용일한 UNet 구조를 가지는 garment extractor EG를 도입한다. Self-attention fusion을 통해 original denoising process로 부드럽게 추출된 garment feature들을 통합한다. Garment feature 통합 후에 ϵθ안 self-attention 계산은 다음과 같이 수정된다.
여기서 αi,βi는 각각 original denoising UNet ϵθ와 garment extractor E안에 i번째 self-attention block의 normalized attention hidden state를 나타낸다.
Original LDM의 text-to-image synthesis 능력을 유지하고 학습 비용을 줄이기 위해, ϵθ의 weights는 frozen한다. Training objective는 다음 수식처럼 요약할 수 있다.
여기서 zCt는 timestep t에서 character image latent zC에 noise를 더해 얻어지고, β는 garment extractor EG의 self-attention block로부터의 전체적인 garment features이다.
Inference 동안, garment image와 character에 대한 text prompt가 주어지면 Magic Clothing은 target image를 입은 character의 이미지를 생성할 수 있다. 한편, garment feature들은 원래의 LDM inference process에 최소한의 계산 비용을 추가하기 위해 모든 denoising step에 걸쳐 공유된다.
2.3 Joint Classifier-free Guidance
본 논문의 garment-driven image synthesis task에 대해 두가지 conditional control이 고려된다 (garment feature, text prompt). 이를 independent controls라고 생각하면 independent classifier-free guidance를 사용할 수 있다.
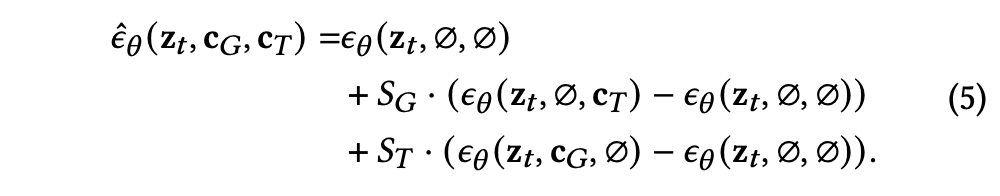
하지만 위 방식을 이용하면, 두 conditional control들이 겹치는 의미를 가진다는 사실을 무시하기 때문에 undesired results를 야기한다.
그래서 본 논문은 joint classifier-free guidance를 사용해서 두 conditional control들의 밸런스를 맞춘다. 본 논문의 joint classifier-free guidance score estimate는 다음과 같다.

다음 이미지에서 위 수식의 두 파라미터의 효과를 볼 수 있다.

2.4 Plug-in Mode
본 논문에서 pretrained LDM의 weights를 frozen하고 garment extractor EG만을 학습시키기 때문에, EG를 plug-in module로 다루고 다양한 finetuned LDM에 결합할 수 있다. 또한 본 논문에서는 ControlNet과 IP-Adapter과 같은 여러 확장들과 finetuned LDMs가 Magic Clothing와 동시에 결합될 수 있다는 것을 확인했다. 이를 통해 본 논문은 이미지 합성에 대해 종합적인 conditional control들을 성취한다.
3. Experiments
3.1 Experimental Setup
3.1.1 Dataset
본 논문에서는 garment와 character image pair뿐만 아니라 character 설명을 포함하는 text prompt 또한 필요로 하기 때문에, VITON-HD 데이터 셋을 사용하고 이 데이터셋 내에 있는 character image를 BLIP을 사용해서 captioning함으로써 text prompt를 생성했다.
3.1.3 Evaluation Metrics
CLIP-I, S-LPIPS, MP-LPIPS, CLIP-T, CLIP aesthetic score를 사용했다. 여기서 본 논문에서 제안한 새로운 metric이 바로 MP-LPIPS라는 metric이다. 이 metric이 제안된 배경은 CLIP-I는 본 논문에서의 task에 대해서는 배경과 인물의 포즈에 너무 민감하다는 문제가 있고 이를 해소할려고 S-LPIPS를 쓰는데 이 또한 여전히 포즈와 paired image에 의존한다는 문제점을 지니기에 이러한 문제를 해소하기 위해 제안됐다. 이 metric은 garment IG의 픽셀과 그에 매치되는 character IC의 픽셀 사이의 LPIPS 거리를 측정한다. 자세하게 보면, 각 garment에 대해 N개의 포인트 PG를 uniform하게 뽑고 timestep t와 layer l에 대해 그것들의 diffusion feature Ft,l(PG)를 계산한다. 다음과 같은 consine 유사도를 계산함으로써 target character에 대해 매칭되는 점 PC를 찾는다.

최종적으로 MP-LPIPS는 다음과 같이 정의된다.

본 논문에서는 N개의 점으로 된 페어 PG,PC에 중심으로 패치 PG,PC∈RN×H×W의 평균 LPIPS 거리를 측정한다. 아래의 이미지에서 볼 수 있듯이, MP-LPIPS는 character에 대한 garment 일관성을 manual annotation의 필요 없이 효과적으로 계산한다. 게다가 배경과 포즈와 같은 요소에 대해 robust하다.

3.2 Experimental Results
3.2.1 Qualitative Results

3.2.2 Quantitative Results

3.2.3 Plug-in Results

3.3 Ablation Study
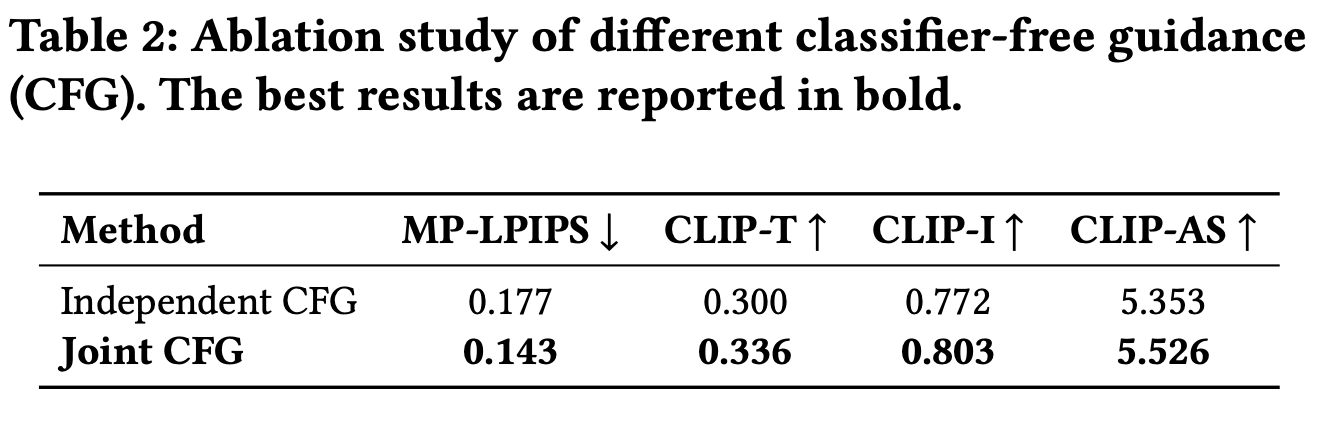
3.4 Limitation
본 논문에서 말하는 Magic Clothing의 한계점은 생성된 이미지들의 퀄리티는 base diffusion model에 매우 의존한다는 것이다. 다른 한계점으로는 training sample의 한계 때문에 down jacket과 coat와 같은 복잡한 garments에 대한 완벽한 생성에는 실패했다고 한다.



