
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- visiontransformer
- 3d generation
- 3d editing
- diffusion
- video editing
- 네이버 부스트캠프 ai tech 6기
- flow matching models
- Concept Erasure
- 코테
- Python
- rectified flow models
- video generation
- BOJ
- diffusion models
- Machine Unlearning
- memorization
- rectified flow matching models
- image generation
- diffusion model
- VirtualTryON
- ddim inversion
- inversion
- unlearning
- flow models
- image editing
- 논문리뷰
- flow matching
- Programmers
- 프로그래머스
- rectified flow
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] SonicDiffusion : Audio-Driven Image Generation and Editing with Pretrained Diffusion Model (arXiv 2405) 본문
[평범한 학부생이 하는 논문 리뷰] SonicDiffusion : Audio-Driven Image Generation and Editing with Pretrained Diffusion Model (arXiv 2405)
junseok-rh 2024. 5. 31. 23:49https://arxiv.org/abs/2405.00878
SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. W
arxiv.org
1. Introduction
기존의 text-to-image generation은 textual 설명의 시각적인 상대에 대한 manual하고 조화롭지 않은 본성때문에 한계점을 지닌다. 이러한 한계점을 audio를 condition으로 하는 이미지 생성에 대한 관심을 증폭시켰다. 청각적인 실마리들은 text 설명이 완전히 캡슐화하는데 어려움을 겼는 문맥의 깊이와 분위기를 제공할 수 있다. 풍부한 audio 신호들을 이용함으로써, 본 연구는 시각적인 content의 생동감과 역동성을 반영한 이미지를 생성하는 것을 목표로 한다. 또한 이를 통해 장면에 대한 더 comprehensive한 이해를 제공하는 audio의 잠재력을 보여준다. 이러한 문제들을 해결하기 위해 본 논문은 SonicDiffusion을 제안한다.

기존의 연구들은 샘플 퀄리티에 대한 단점을 지녔고 audio의 의미적인 capture에서의 한계를 겪고 있다. 본 논문의 method는 modality 변환의 연결자 역할을 하는 audio-image cross-attention layer를 사용함으로써 audio 신호들을 시각적 representation으로 처리하고 변환하는 능력으로 다른 것들과 구별된다. 이 방식은 높은 퀄리티의 이미지 생성 능력을 유지할 뿐만 아니라 최소한의 학습 requirements로 audio-driven creativity와 contextual richness의 새로운 차원을 도입한다. 게다가 이 방식은 feature injection을 통해 audio input의 특징을 반영한 수정을 수행하면서 실제 이미지를 수정하는 것으로 쉽게 확장될 수 있다.
본 논문의 방식은 엄밀한 실험을 통해 정량적, 정성적으로 기존 연구들보다 좋은 결과를 보이는 것을 보여준다. 또한 결과는 본 논문의 모델이 landscape 생성에서 복잡한 high-frequency 디테일들을 capture하고, 소리에 의해 영향 받은 사람 얼굴 특징들을 rendering하고, 묘사된 객체의 material 특징들을 반영하는 시각적 요소와 상응하는 특정 소리를 mapping하는 능력들을 보여준다.
본 논문의 contribution은 다음과 같이 요약할 수 있다.
- Pretrain된 Stable Diffusion 모델의 능력을 확장하는 새로운 diffusion model을 도입한다. 이는 sound-guided image generation이 가능하다.
- 본 논문의 접근 방식은 audio-image cross-attention layer를 제안하고 이는 최소한의 학습 파라미터 셋을 필요로 하도록 전략적으로 디자인됐다.
- 본 논문의 모델은 생성뿐만 아니라, auditory input에 매칭되는 이미지 수정도 가능하다.
2. Method
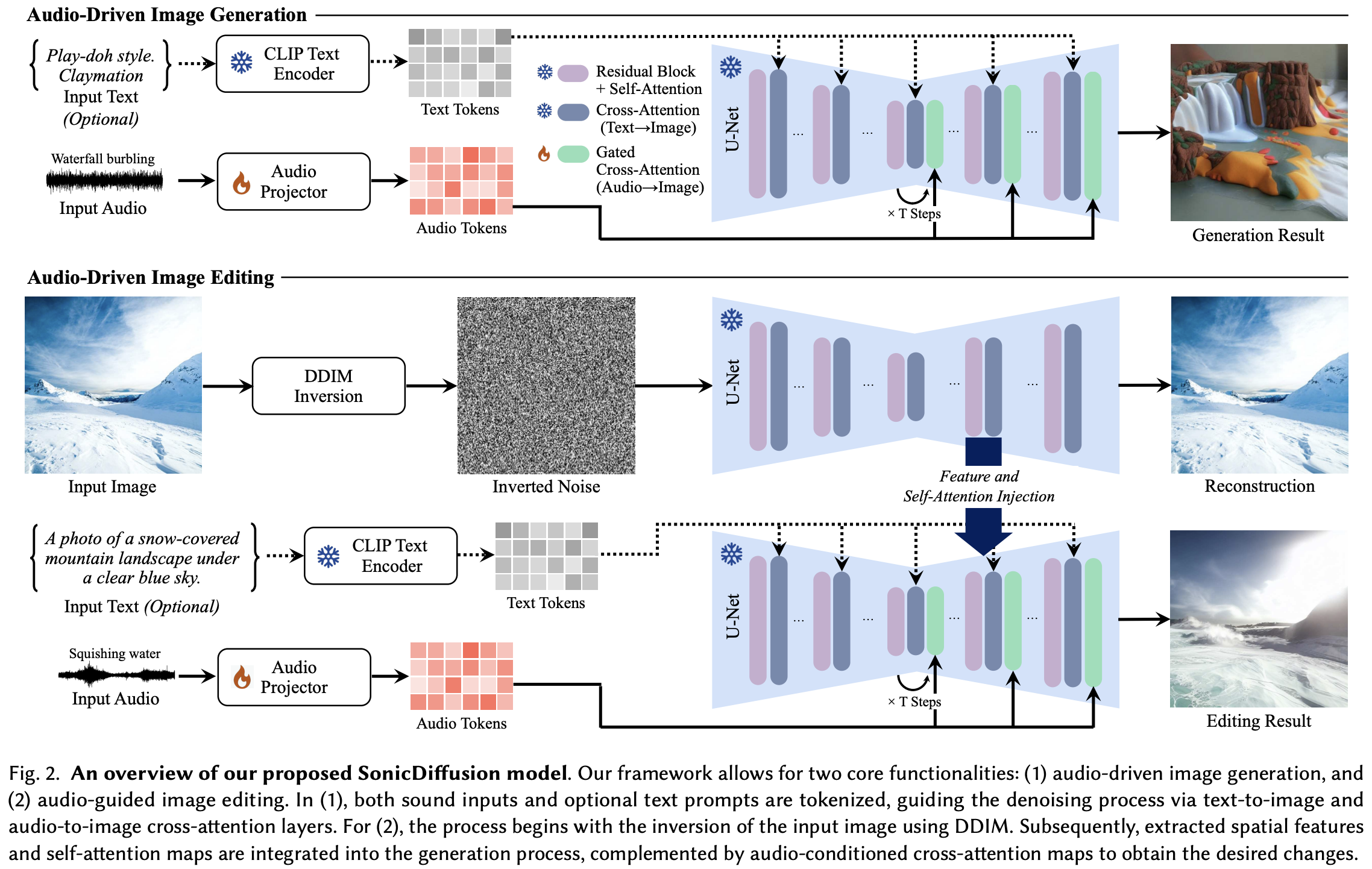
본 연구에서는 auditory input을 사용해서 이미지 생성과 수정의 프로세스를 조종하는 접근 방식인 SonicDiffusion을 도입한다. 이 접근 방식에서 두 가지 중요한 구성 요소를 가진다. 첫 번째는 Audio Projector로, 이는 audio clip을 통해 추출된 feature들을 series of inner space token들로 변환한다. 그 후 이 토큰들은 audio-image cross-attention layer를 통해 이미지 생성 모델로 통합된다. 이렇게 하면 audio와 visual 모달리티를 융합하는 parameter-efficient 방식으로 사용할 수 있다.
2.1 Preliminaries
https://juniboy97.tistory.com/47
[평범한 학부생이 하는 논문 리뷰] High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
부스트캠프 내에서 내가 진행하고 있는 diffusion 스터디에서는 아직 SDE diffusion 논문을 읽고 있고, DDIM까지 읽고 나서 Stable Diffusion을 읽으려 했지만, 최종 프로젝트 때문에 미리 읽게 되었다. 다행
juniboy97.tistory.com
2.2 Training Pipeline
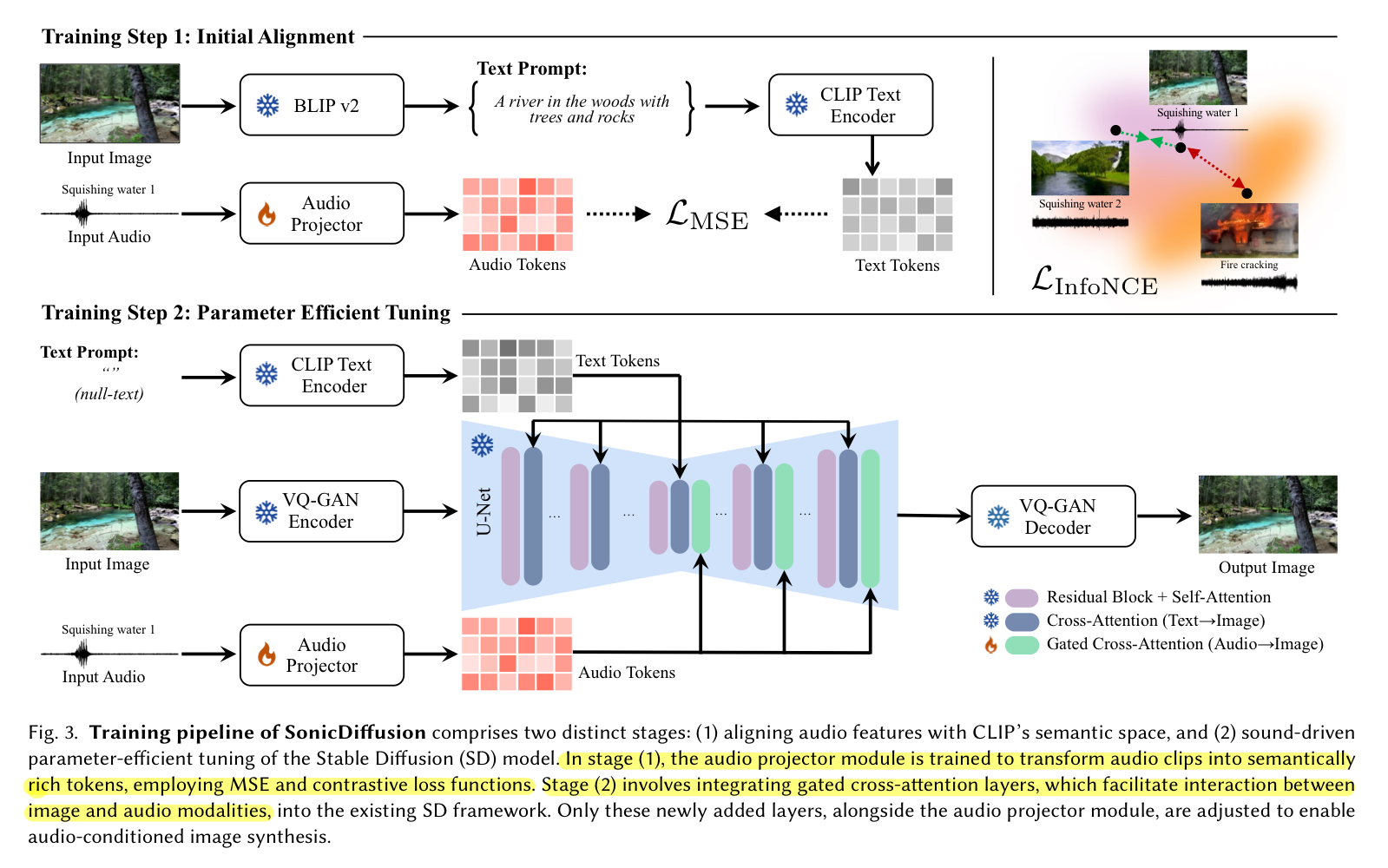
전체적인 training pipeline은 위 이미지와 같다. SonicDiffusion은 two-stage training process를 사용하는데, 각 단계는 audio-driven image synthesis을 달성하기 위해 특정한 목적을 달성한다. 첫 번째 stage에서는 audio projector 모듈을 학습한다. 두 번째 stage에서는 SD 모델에 cross-attention layer을 통합하는데 집중한다.
2.3 Audio Projector
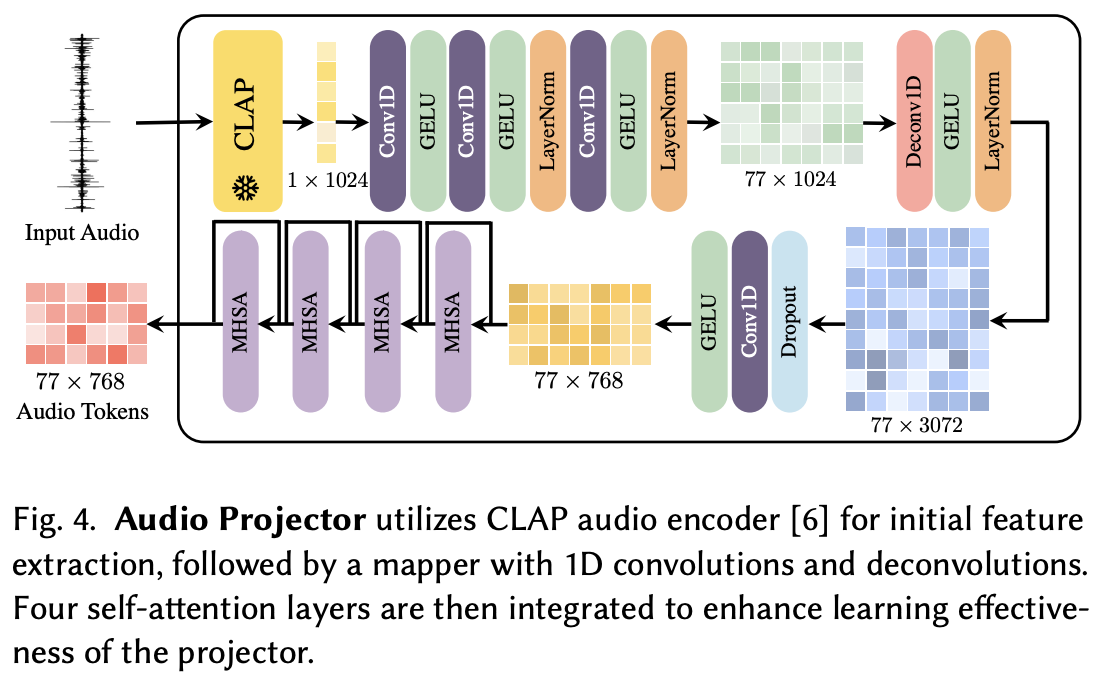
Audio와 image 도메인 사이의 space alignment를 성취하기위해, 본 논문은 Audio Projector module을 도입한다. 이 모듈은 위 이미지처럼 구성된다. CLAP을 통해 audio input으로 1차원의 embedding으로 생성한다. 이 embedding은 1D convolutional과 deconvolutional layer로 구성된 초기 mapper를 통해 $C$ channels의 $K$ tokens로 변환된다. 이 tokens는 4개의 self-attention block들에 의해 refine돼 final representation을 생성한다. 그리고 이는 text token의 차원과 맞아 SD 모델의 gated cross-attention layer에 호환된다.
AudioProjector를 학습시키기 위해 MSE와 contrastive loss를 결합해 사용한다. Contrastive Loss로는 InfoNCE loss를 사용한다.

여기서 $a_0, a_1$은 같은 class로부터의 audio clip이고 $\{ a_i \}^{N+1}_{i=2}$는 다른 class로부터의 audio clip이다. 이 contrastive loss는 다른 class로부터 각자 멀리하도록 한다. 이는 잘 정의된 semantic space를 야기한다. 이 space를 부유하게 하기 위해, audio-image pair를 사용해서 audio token $c_{audio}$와 image로 BLIPv2를 이용해 추출한 text token $c_{text}$ 사이의 MSE loss를 계산한다.

이 두 loss를 통해 AudioProjector를 학습시키는 loss를 아래와 같이 나타낸다. 이 때 $\alpha_1 = 1.0$과 $\alpha_2 = 0.25$이다.

$K = 77, C = 768$이고 MSE와 Contrastive Loss를 사용할 때 $K$개의 각 토큰에 대해 loss를 계산하고 이를 weighted sum을 한다.
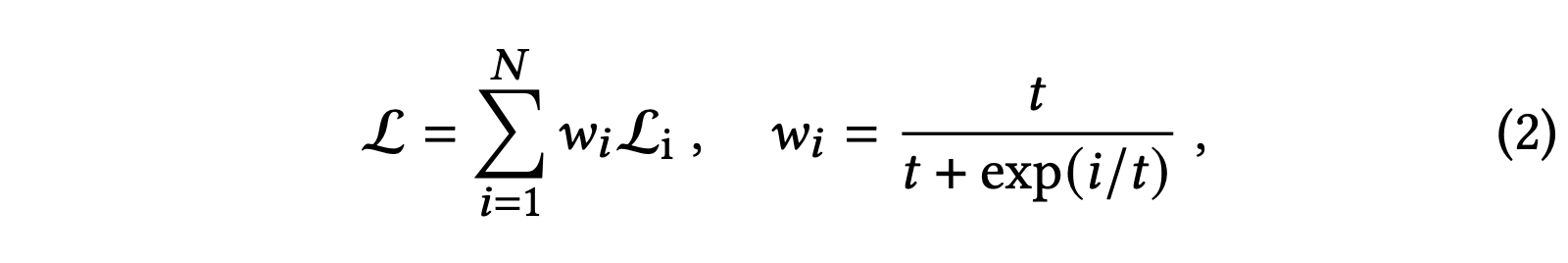
또 $C$를 768로 두는 것은 Stable Diffusion의 pretrain된 text-image cross-attention layer의 weight로 audio-image cross-attention layer를 초기화할 수 있게한다.
2.4 Gated Cross-Attention for Audio Conditioning
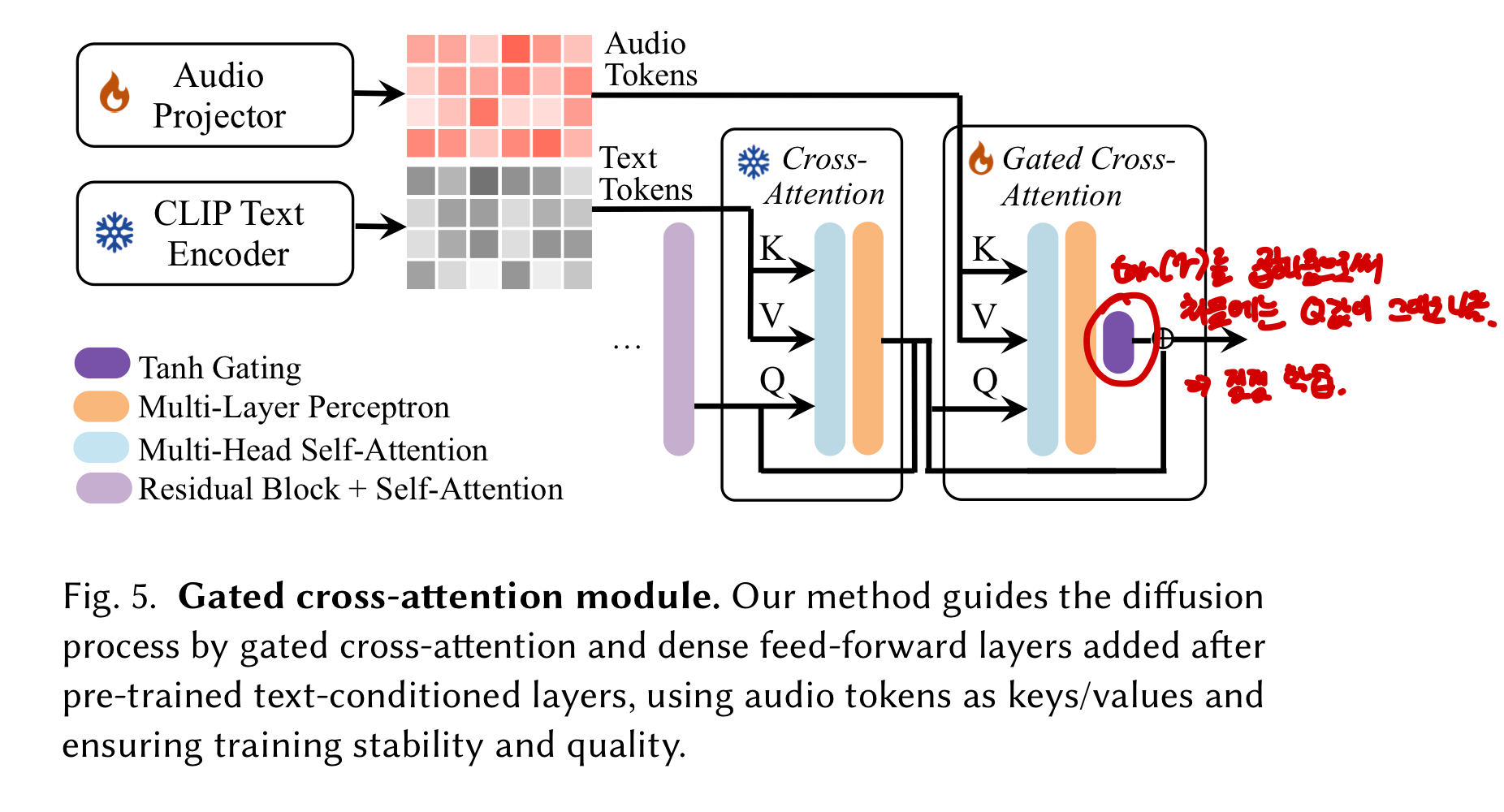
Image와 audio token사이의 관계를 효율적으로 모델링하기 위해, 위의 이미지에서와 같이 새로운 gated cross-attention layer를 도입한다. 이러한 수정은 image feature들이 audio token들에 상호작용하는 것을 가능하게 함으로써 audio-conditioned image 생성을 용이하게 하는 것을 목표로 한다.
본 논문은 UNet의 encoder의 구성은 유지하는 반면 decoder에 새롭게 도입된 gated cross-attention layer를 넣음으로써 증가시킨다. 이 구성에서 audio projector와 gated cross-attention만 학습된다. 첫 번째 stage를 통해 pretrain된 audio projector는 DDPM loss를 통해 더 refine되고 이를 통해 audio와 image pair 사이의 alignment를 강화한다. Decoder는 다음과 같이 처리된다.
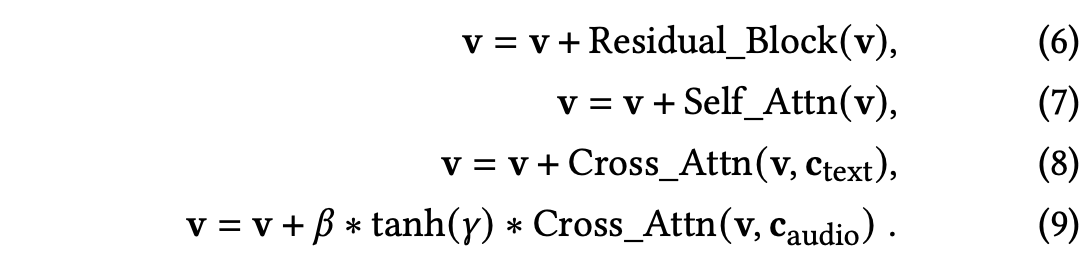
새로운 레이어에 게이팅 메커니즘을 통합한 것이 이 접근 방식의 핵심이다. 이 메커니즘은 모델의 원래 denoising 효율을 유지하는 데 매우 중요하다. Trainable parameter $\gamma = 0$로 초기화하고 $\beta = 1$로 셋팅한다. 학습 동안, $\gamma$는 점진적으로 최적화된다. 이 단계에서는 아래의 conditioned DDPM loss가 적용된다.

Tuning동안에는 null-text가 사용되지만, inferece에서는 생성 프로세스를 강화하기 위해 선택적인 text prompt를 통합할 수 있다.
Stable Diffusion과 다르게, 본 논문은 stage 2에서 audio projector를 trainable하게 유지함으로써 robustness를 강화한다. 처음에는 audio projector가 class 분리와 audio feature와 image caption의 feature를 align하는 것에 집중한다. Stage 2에서는 image와 audio feature를 mapping하는 능력을 향상한다. Stage 2에서는 stage 1에서 학습한 지식을 보존하기 위해 더 작은 learning rate를 사용한다.
본 논문에서 CFG를 가능하게 하기 위해, 다음과 같은 수식으로 정의한다.

2.5 Audio-Guided Image Editing
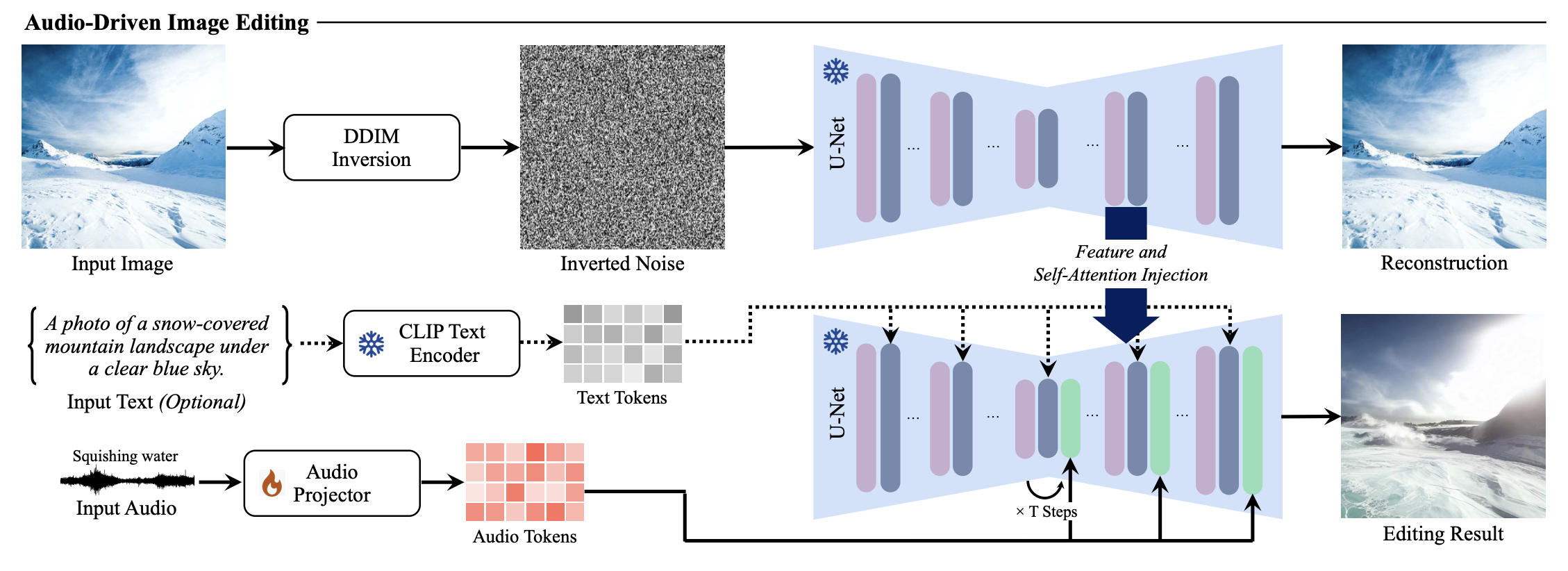
본 논문의 method는 기존의 SD-based image editing method들에 결합돼서 audio-guided image editing을 가능하게 한다. Source image를 reconstruction을 해서 얻은 residual과 self attention feature를 이미지 생성 과정에서의 UNet에 주입한다. 이를 통해 text-conditioned edit을 용이하게 하면서 source image의 구조의 보존을 보장한다. (이 논문에서 제안한 방식을 이용하는데 논문을 읽어보고 이 논문에 대한 포스팅도 진행해봐야할 듯...)
Inversion step $t$에서 얻어진 residual layer $f^4_t$와 attention maps $A^l_t$으로부터의 feature를 다음과 같이 대응되는 editing phase에 주입한다.

Self-attention feature의 주입을 통해, 모델은 중요한 layout과 shape 디테일들은 보존하면서 공간 feature들 사이의 관계를 capture한다. Conditioning signal로 audio token을 통합함으로써, 효율적으로 audio-guided image editing을 용이하게 한다.
2.6 Implementation Details

3. Experimental Setup
Dataset
Landscape + Into the Wild, Greatest Hits, RAVDESS
Evaluation Metrics
- 생성된 이미지와 input audio사이의 의미적 연관성 : Audio-Image Similarity(AIS), Image-Image Similarity(IIS), Audio-Image Content(AIC)
- 샘플의 photorealism : FID Score
AIS : audio input과 생성된 이미지 사이의 의미적 유사성을 측정. Wav2CLIP model을 통해 계산.
IIS : input audio와 연관된 ground truth 이미지와 생성된 이미지 사이의 의미적 유사성 계산. target image의 의미적 content를 얼마나 잘 capture하는지 평가.
AIC : 생성된 이미지의 content와 그와 대응되는 ground truth audio label의 연관성을 평가. image classifier로 분류된 class label과 실제 audio label사이의 alignment 평가.
Competing Approaches
GAN-based SGSIM, Sound2Scene, StableDiffusion based GlueGen, CoDi, AudioToken, TempoTokens, DALLE-2 based ImageBind와 비교한다. 또한 image editing 결과는 text-based PnP model과 비교한다. 이는 텍스트만 사용한 것보다 audio-driven semantic information을 주입하는 것의 이미지 조작에서의 이점을 보여준다.
4. Results
Audio-Driven Image Generation



위 결과들을 보면 SonicDiffusion이 모든 데이터셋에서 가장 좋은 FID score를 보였고, 또한 AIC와 IIS에서 좋은 성능을 보여 audio-driven image generation에서 좋은 효과를 보였다. 또한 이미지 6을보면 SonicDiffusion의 결과가 시각적 응집력이 좋을 뿐만 아니라 input audio와 잘 align되는 것을 볼 수 있다. 또 text와 audio가 동시에 input으로 들어올 경우의 결과도 좋아 보이는 것으로 다양한 모달리티에 대한 해석과 합성을 잘한다는 것을 확인할 수 있다.
Audio-Driven Image Editing


첫 번째 이미지의 결과로 생성 결과가 주어진 audio의 의미를 담아서 이미지를 수정하는 능력을 보여준다. 두 번째 이미지는 다른 모델들과의 비교 결과인데, 이는 조작 퀄리티와 style transfer 정확성이 다른 모델들보다 우월하다는 것을 보여준다.
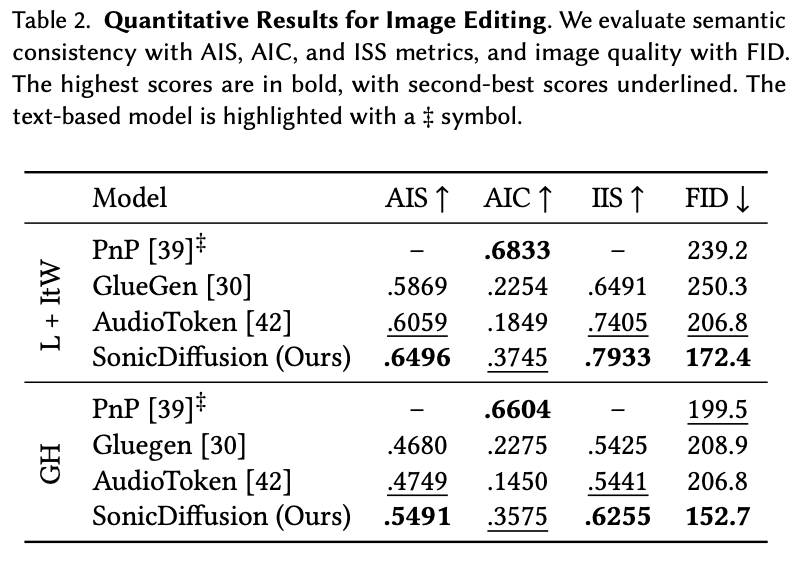

표 2는 AIS와 ISS에서 가장 좋은 결과를 보여줬고 IIS에서는 두번째 좋은 결과를 보였다. 이는 audio에 대해 image를 정확하게 조작하는 것을 보여준다. 또한 FID score도 가장 좋아 퀄리티도 좋다는 것을 보인다. 오른쪽 이미지는 두 소리 사이의 interpolation과 소리의 크기에 대한 결과를 보여준다.
5. Ablations
Audion Projector 학습에서 Loss 함수의 영향
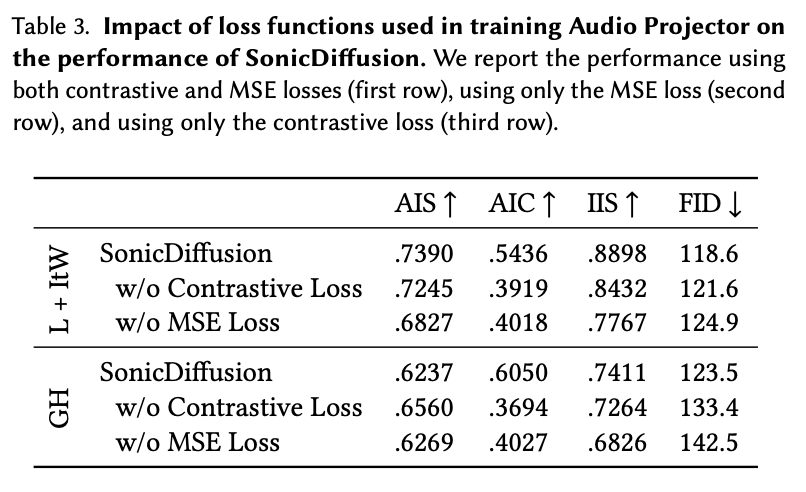
위 결과를 통해 Contrastive Loss가 없으면 다른 audio conditioning사이를 구분하는 것을 못하는 것을 알 수 있다. MSE Loss가 없으면 수렴시간이 길어지고 정확성이 떨어진다. 특히 MSE Loss가 pre-trained CLIP space에 대한 audio space alignment를 하는데 매우 중요하다고 한다.
Training 전략에 대한 영향

Diffusion Loss에 mapping을 학습하도록 의존하는 것(stage 1 학습 없는 경우)은 다른 audio input에 대한 구분을 짓는 능력을 읽어 상당한 성능 감소를 보였다. Stage 2에서 Audio Projector를 freeze하는 경우 이미지 퀄리티가 더 낮았다. Audio를 single token으로 나타내는 것은 성능 감소를 보였다.
Impact of Where to Insert Gated Cross-Attention Layers

6~11에 넣으면 성능이 안좋아지는 것을 볼 수 있다. 모든 layer에 넣은 경우보다 더 좋다고 말할 수 있을까...???흠...
Inference Time Choices

$\beta$는 생성 과정에서 text에 대해서 audio의 상대적 중요성을 조정할 수 있게한다. 이에 대한 실험 결과는 다음과 같다.

UNet에서 각 layer마다 다른 $\beta$를 넣는 연구를 더 진행해보면 좋을 것 같다고 한다!
6. Limitations and Failure Cases

모델이 audio의 본질을 이해 못하는 경우가 가끔 발생하고 Stable Diffusion에서 생성된 artifacts에 의한 문제점이 존재한다. Image editing에서는 DDIM inversion에 의한 문제점이 존재한다.



