
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문리뷰
- rectified flow
- transformer
- inversion
- 네이버 부스트캠프 ai tech 6기
- VirtualTryON
- visiontransformer
- 3d editing
- 프로그래머스
- flow matching
- 3d generation
- noise optimization
- segmenation map generation
- diffusion
- image editing
- Vit
- video generation
- BOJ
- 코딩테스트
- flipd
- video editing
- segmentation map
- diffusion model
- DP
- Programmers
- diffusion models
- memorization
- masactrl
- 코테
- Python
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation (CVPR 2023) 본문
[평범한 학부생이 하는 논문 리뷰] Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation (CVPR 2023)
junseok-rh 2024. 7. 19. 11:23Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
"a photo of a pink toy horse on the beach" "a photo of a bronze horse in a museum" "a photo of a robot horse" "a photo of robots dancing" "a cartoon of a couple dancing" "a photo of a wooden sculpture of a couple dancing" "a photorealistic image of bear cu
pnp-diffusion.github.io
1. Introduction

본 논문의 목표는 input image가 전체적인 구조, layout을 가이드하고 input text가 장면의 semantic & appearance를 가이드하는 text-guided I2I translation 모델이다. 이러한 목표를 달성하기 위해 본 논문에서는 diffusion model을 학습시키지 않고 diffusion model의 feature와 cross-attention에 집중한다.
2. Method
본 논문의 key finding은 생성된 structure에 대한 fine-grained control은 생성 프로세스 동안 모델 내부의 공간전 feature들을 조작함으로써 성취할 수 있다는 것이다. 특히 본 논문에서 i) 중간 디코더 layer에서 추출된 공간적인 feature들은 localized semantic 정보를 인코딩하고 appearance 정보에 덜 영향 받는다는 것과 ii) 공간적 feature들 사이의 affinity를 표현하는 self-attention은 미세한 layout과 shape 디테일들을 유지하도록 한다는 것을 관찰했다.
전체적인 본 논문의 framework는 다음과 같다.

Spatial features.

위 이미지는 생성 과정에서 decoder의 각 layer의 feature $\mathbf{f}^l_t$를 뽑아서 PCA를 적용해 가장 높은 3개의 component를 시각화한 것이다. Layer 4에서의 결과를 보면 모든 객체에 대해 유사한 부분에서는 유사한 색을 가지는 것을 볼 수 있다. 이는 다음 이미지에서 처럼 timestep이 지남에 따라 변하지 않는다.

Feature injection
Base image $I^G$에서 DDIM inversion을 통해 초기 noise $x^G_T$를 얻고 plug-and-play의 input으로 이와 동일한 noise $x^*_T$를 사용한다. Base 이미지를 denoising하는 과정에서 각 $t$에 대해 feature $\{ \mathbf{f}^l_t \}$를 추출한다. 그러고 이를 editing 이미지 생성 과정에 주입한다.

다음 이미지는 어떤 layer의 feature를 주입하는 지에 대한 결과를 보여준다.

위 결과를 보면 layer 4의 feature만 주입하는 것이 좋다. 너무 깊은 layer에 feature들을 주입하게 되면 appearance 정보가 들어가게 된다.
Self-attention

위 이미지는 각 layer에 대한 attention map $\mathbf{A}^l_t$을 시각화한 것이다. 비슷한 구역은 비슷한 색을 지니고 layer가 깊어질수록 high-frequency를 구분짓는다. 다음과 같이 작동한다.

이미지 5를 보면 attention layer는 4-11 layer에 주입할 때 성능이 가장 좋다. 이미지 5(c)를 보면 attention만 주입할 경우의 결과가 나와있는데 semantic asscociation이 없는 것을 볼 수 있다.
Plug-and-Play Diffusion Feature는 다음 알고리즘처럼 작동한다.

Negative-Prompting
Classifier-free guidance 수식은 다음과 같다.
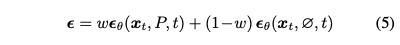
여기서 unconditional대신에 negative pompt를 넣은 $\epsilon(x_t,P_n,t)$과 unconditional을 합한 다음 수식을 기존 classifier-free guidance에 대입해 사용한다.

$$ \epsilon = w\epsilon(x_t,P,t) + (1-w)\tilde{\epsilon}$$
Negative-prompting은 textureless primitive guidance 이미지를 다루기 좋다고 한다.
3. Results
3.1 Comparison to Prior/Concurrent Work

본 논문의 방법론이 guidance layout에 대한 높은 보존과 target prompt에 대한 높은 fidelity를 보여준다.

Extended Comparison to P2P

P2P는 여러 prompts edit이 적용될 때 guidance structure로부터 크게 벗어난 이미지를 생성한다.
Additional Baselines

3.2 Ablation


4. Limitations
본 논문의 방식은 diffusion feature space에서 원래의 content와 translated content사이의 의미적인 association에 의존한다. 또 DDIM inversion을 사용하기 때문에 textureless minimal 이미지들에 대해 low-frequency appearance 정보를 인코딩하는 latent를 초래할 수 있고, 이는 결과에 appearance 정보를 유출할 수 있다.

A. Ablations

A.1. Negative-prompting

A.2. Injected features




