
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- transformer
- image generation
- DP
- BOJ
- shortcut model
- 네이버 부스트캠프 ai tech 6기
- 코테
- flow matching
- 논문리뷰
- 코딩테스트
- Programmers
- rectified flow matching models
- diffusion models
- diffusion
- rectified flow
- diffusion model
- Vit
- 3d generation
- memorization
- 3d editing
- ddim inversion
- 프로그래머스
- VirtualTryON
- video generation
- image editing
- video editing
- freeinv
- Python
- inversion
- visiontransformer
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Posterior Distillation Sampling (CVPR 2024) 본문
https://posterior-distillation-sampling.github.io/
Posterior Distillation Sampling
We introduce Posterior Distillation Sampling (PDS), a novel optimization method for parametric image editing based on diffusion models. Existing optimization-based methods, which leverage the powerful 2D prior of diffusion models to handle various parametr
posterior-distillation-sampling.github.io
1. Introduction
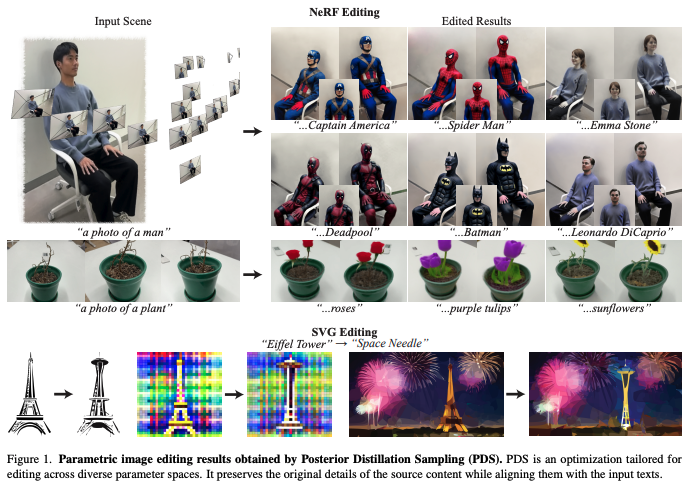
Editing은 target text와 original source content를 동시에 고려해야하기에 generation과 상당히 다르다. 그렇기에 editing은 alignment with the target text prompt와 preservation of source content's identity라는 두 주요한 측면을 고려해야한다. 이러한 부분에서 SDS는 두 번째 고려사항이 부족하다고 한다. 그래서 그 후 연구에서 DDS라는 것이 제안되었지만 DDS의 optimization function은 여전히 identity preservation에 대한 명시적인 term이 부족하다고 한다.
그래서 본 논문에서는 Posterior Distillation Sampling (PDS)를 제안한다. PDS는 source와 optimized target의 stochastic latents를 매칭시키는 것을 목표로 한다. Optimization process가 source와 target의 forward process posterior를 align하는 것과 닮았다는 것을 보였고 이는 target의 생성 프로세스 궤적이 source의 것에서 많이 벗어나지 않는 것을 보장한다.
기존의 방식들은 직접 3D space를 edit하지 않고 2D space에서 editing process를 수행해 우회하는 방식이다. 반면에 본 논문의 method는 3D space에서 NeRF를 직접 업데이트한다. 그래서 view-consistent 방식으로 3D scene을 수정된 버전으로 점진적으로 바꾼다. NeRF editing에서, 본 논문의 방식이 처음으로 large geometric 변화를 생산하거나 지역을 특정화하는 것 없이 임의이 지역에 object를 추가한다고 한다.
2. Related Work
2.1 Score Distillation Sampling
SDS에 대한 설명은 다음 포스팅에서 확인할 수 있다.
https://juniboy97.tistory.com/72
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion
https://arxiv.org/abs/2209.14988 DreamFusion: Text-to-3D using 2D DiffusionRecent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require l
juniboy97.tistory.com
그 외에 VSD, DDS도 있다고 한다.
2.2 Text-Driven NeRF Editing
Instruct-NeRF2NeRF에 대한 설명은 다음 포스팅에서 확인할 수 있다.
https://juniboy97.tistory.com/70
[평범한 학부생이 하는 논문 리뷰] Instruct-NeRF2NeRF : Editing 3D Scene with Instructions
https://arxiv.org/abs/2303.12789 Instruct-NeRF2NeRF: Editing 3D Scenes with InstructionsWe propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an ima
juniboy97.tistory.com
Iteratvie DU 대신에 NeRF editing에 SDS나 DDS를 직접 적용하는 방식들도 있다고 한다.
2.3 Diffusion Inversion
DDIM inversion, DDPM inversion이 있는데 본 논문에서는 이 DDPM inversion을 parameter space에 적용한 방법인듯 하다.
$\rightarrow$ DDPM inversion은 공부해야할 것 같고, DDIM inversion도 다시 수식 보면서 이해해봐야 할 것 같다...
3. Preliminaries
3.1 Score Distillation Sampling (SDS)
앞서 언급한 포스팅을 통해 볼 수 있으니 pass~
3.2 Delta Denoising Score (DDS)
SDS를 editing에 맞도록 SDS 수식을 아래와 같이 변형했다.
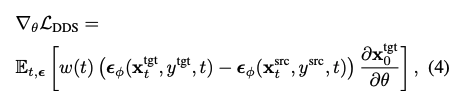
여기서 $\mathbf{x}^{src}_t$와 $\mathbf{x}^{tgt}_t$는 아래와 같이 동일한 noise $\epsilon$을 공유한다.

이는 source의 identity를 보존하는 명시적인 term이 부족하다. 그래서 여전히 source로부터 상당히 벗어난 결과를 보이기 쉽다.
3.3 Stochastic Latent in Generative Process
DDPM inversion은 모든 timestep $t$에 대해서 $\tilde{z}_t$를 계산해두고 이와 함께 새로운 target prompt로 새로운 generative process를 실행해 editing된 이미지를 생성한다. 이는 2D-pixel space에 제한되기 때문에 본 논문에서는 parameter space로 확장하려는 듯 하다.
4. Posterior Distillation Sampling
본 논문에서는 parametric image editing을 위해 디자인된 새로운 optimization fuction인 PDS를 도입한다. 목적은 $x^{src}_0$의 identity를 보존하면서 $y^{tgt}$에 align되는 $x^{tgt}_0$를 합성하는 것이다. 이를 이루기 위해서, optimization에서 stochastic latent $\tilde{z}_t$를 사용한다.
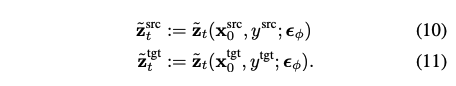
Stochastic latents를 사용한 새로운 loss는 다음과 같다.
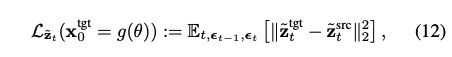
여기서 $\mathbf{x}_{t-1}$와 $\mathbf{x}_t$를 계산할 때 $\tilde{\mathbf{z}}^{src}_t, \tilde{\mathbf{z}}^{tgt}_t$는 동일한 noise $\epsilon_{t-1},\epsilon_t$를 공유한다.
Optimization을 통해 target과 source의 stochastic latents를 매칭시킨다. PDS는 다음과 같아진다.
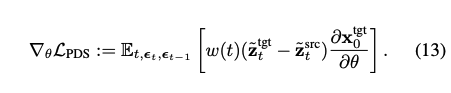
이 수식을 정리하면 아래와 같은 식이 나온다.
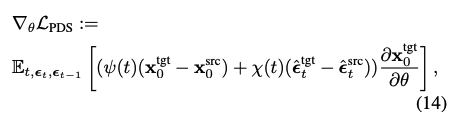
여기서 $\hat{\epsilon}^{src}_t := \epsilon_\phi (\mathbf{x}^{src}_t, y^{src},t), \hat{\epsilon}^{tgt}_t := \epsilon_\phi (\mathbf{x}^{tgt}_t, y^{tgt},t)$이다.
수식 전개

$\mathbf{z}^{tgt}_t$와 $\mathbf{z}^{src}_t$를 매칭시키는 것은 다른 prompt $y^{tgt}, y^{src}$에 의해 조종됨에도 $\mathbf{x}^{tgt}_0$와 $\mathbf{x}^{src}_0$의 posterior가 발산하지 않는다는 것을 보장한다. PDS는 $y^{tgt}$와 align되는 $\mathbf{x}^{tgt}_0$의 샘플링을 가능하게 하면서 $\mathbf{x}^{src}_0$의 identity를 유지한다. 이는 target sampling process에 $\mathbf{x}^{src}_0$의 posterior의 distillation을 통해 얻어진다.
4.1 Comparison with SDS and DDS
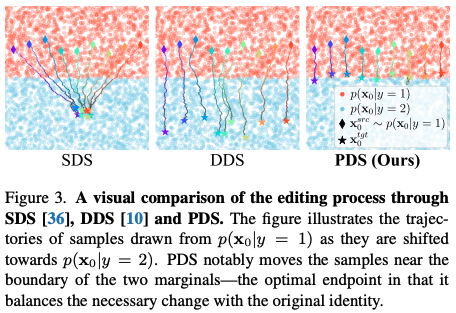
위 실험을 통해 PDS와 SDS, DDS를 비교했다. 결과를 해석하면 PDS는 두 class의 경계에서 멈췄는데 이는 필수적인 변화와 original identity 사이의 balance를 성취한 것을 알 수 있다.
4.2 Comparison with Iterative DU
Iterative DU는 2D space에서 editing하고 그 이미지들을 NeRF에 넣어서 최종적으로 3D가 editing되는 방식이라면 본 논문에서는 3D space에서 직접 editing된다는 차이점이 있다. 본 논문에서는 iterative DU와 본 논문의 방식을 비교한 결과를 보여준다.

위 결과를 보면 ip2p와 DDPM inversion에서의 결과는 시점에 대해 inconsistent한 것을 볼 수 있고 이로인해 3D space로 넘기는 과정에서 결과가 안 좋은 것을 볼 수 있다. Inv2P와 본 논문의 방식은 둘 다 stochastic latent를 이용하지만, Inv2P는 2D space에서 진행되지만 본 논문의 방식은 3D space에서 진행되는 것에서 두 방식의 비교를 주목할만 하다.

5. NeRF Editing with PDS
Rendering parameter $\theta$와 특정 viewpoint $v$가 주어졌을 때, rendering process는 $I_v = g(v;\theta)$로 표현된다. Stable Diffusion의 encoder를 통해서 target latent $\mathbf{x}^{tgt}_{0,v} := \mathcal{E}(g(v;\theta))$를 얻는다. NeRF reconstruction에 사용된 original source image $\{I^{src}_v \}$가 주어지면, source latent는 $\mathbf{x}^{src}_{0,v} := \mathcal{E}(I^{src}_v)$로 계산된다.
Viewpoint의 pre-fixed set $\{ v \}$가 주어지면, 랜덤하게 선택된 $v$에 대해 $\mathbf{x}^{src}_{0,v}, \mathbf{x}^{tgt}_{0,v}$이 계산된다. $(\mathbf{x}^{src}_{0,v}, y^{src}), (\mathbf{x}^{tgt}_{0,v}, y^{tgt})$ 페어가 PDS optimization에 들어가고 target prompt에 의해 지시된 방향으로 $\theta$가 optimize된다. Optimization이후에, update된 NeRF paramenter $\tilde{\theta}$는 target prompt와 align된 editing된 3D scene을 렌더링한다.($\tilde{I}_v := g(v;\tilde{\theta})$)
Final output을 향상시키기 위해, refinement stage를 도입한다. Refinement stage의 iteration동안, editing된 렌더링 $\tilde{I}_v$을 선택하고 SDEdit을 이용해서 더 현실같은 이미지로 refine한다. Editing된 NeRF scene은 이렇게 반복적으로 업데이트된 이미지로 reconstruction loss를 통해 refine된다.
6. Experimental Results
6.1 NeRF Editing
위 Figure 2가 본 실험의 결과이다. 1, 2번째 행을 보면 본 논문의 method가 유일하게 input text로부터 3D scenes에서 거대한 geometric 변화를 했다. 또한 3, 4번째 행을 보면 본 논문의 method가 background detail들을 유지하면서 object들을 성공적으로 추가했다. 마지막을 보면 본 논문의 method와 IN2N 둘 다 결과가 좋은데, 본 논문의 method가 input scene의 original identity를 가장 잘 보존했다.
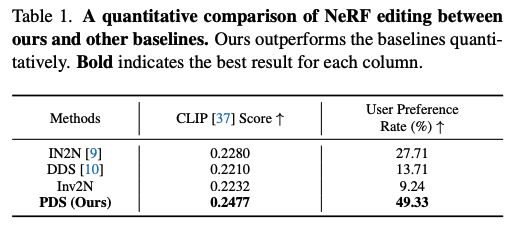
User study를 통한 퀄리티 평가와 edited 2D rendering과 target text prompt사이의 유사성을 측정하는 CLIP score에 대한 정량적인 평가도 진행했고 결과는 위와 같다.
6.2 SVG Editing

위 결과를 보면 본 논문의 method가 가장 구조적인 semantics를 잘 보존하는 것을 확인할 수 있다.
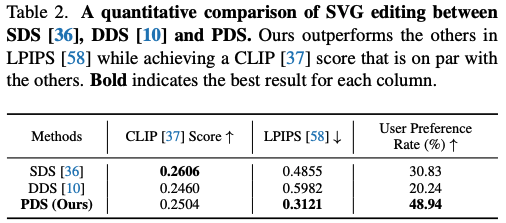
위 정량적인 결과를 보면 input에 대한 fidelity를 측정하는 LPIPS에서 큰 차이로 가장 좋은 결과를 보였다. 이는 target text prompt에서 묘사된 특징들을 맞추기 위해 최소한의 변화를 도입하는 것을 증명한다. 또 user study도 진행했는데 다른 결과들과 동일하게 여기서도 결과가 가장 좋았다.
6.3 Effect of the Refinement Stage

전체적인 editing 결과는 refinement stage 이전에 나타나고 refienment stage는 말그대로 fidelity를 강화한다.



