
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Programmers
- inversion
- shortcut model
- image editing
- diffusion models
- DP
- 3d editing
- Python
- transformer
- memorization
- image generation
- diffusion
- video editing
- rectified flow
- diffusion model
- Vit
- freeinv
- BOJ
- ddim inversion
- 프로그래머스
- 네이버 부스트캠프 ai tech 6기
- 코테
- 논문리뷰
- VirtualTryON
- flow matching models
- 3d generation
- one step generation
- visiontransformer
- video generation
- 코딩테스트
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023) 본문
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
junseok-rh 2024. 6. 27. 21:58https://arxiv.org/abs/2209.14988
DreamFusion: Text-to-3D using 2D Diffusion
Recent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoi
arxiv.org
1. Introduction
Diffusion model은 다양한 다른 modality에서 적용되는데 성공했지만, 3D에서는 그만큼의 데이터가 있지 않기에 어려움을 겪는다. 본 논문에서는 2D diffusion model을 이용해 Text-to-3D generation을 한다. 기존에 DreamField라는 논문이 있었는데 이 모델을 통해 생성된 3D object는 realism과 accuracy가 부족한 것을 보였다. 본 논문에서는 Score Distillation Sampling(SDS)을 통한 방식으로 기존 모델의 한계점을 극복한다. SDS와 3D generation task에 맞춰진 NeRF variant를 결합함으로써 text prompt가 주어지면 high-fidelity의 통일성있는 3D object와 scene을 생성한다.
2. Diffusion Models and Score Distillation Sampling
2.1 How can we sample in parameter space, not pixel space?
본 논문에서의 목적은 ramdom angle들로부터 렌더링 됐을 때, 렌더링된 이미지가 좋게 보이는 3D을 만드는 것이 목적이다. 이러한 모델들은 $\mathbf{x} = g(\theta)$로 표현되어지는 differentiable image parameterization(DIP)로 특정화될 수 있다. ($\mathbf{x}$는 이미지, $g$는 differentiable generator(NeRF), $\theta$는 parameter(NeRF input)) 이렇게 함으로써 이미지 $\mathbf{x}$를 학습하는 것이 아니라 parameter $\theta$를 학습시킴으로써 제약을 표현하고(?), 더 컴팩트한 공간에서 최적화하고, 픽셀 공간을 횡단하는 더 강력한 최적화 알고리즘을 활용할 수 있게 한다.
본 논문은 최적화를 통해 tractable한 샘플링을 가능하도록 하기 위해 diffusion model의 구조를 활용한다. 본 논문은 $\theta$를 최적화해서 $\mathbf{x} = g(\theta)$가 frozen diffusion model으로부터의 샘플처럼 보이게 한다. 이 최적화를 수행하기 위해, 미분 가능한 loss가 필요하다. 처음에는 아래와 같은 diffusion model의 loss를 연구했다.
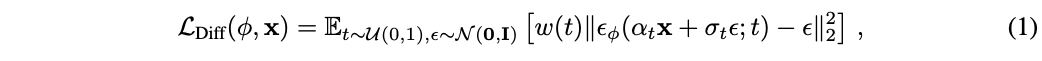
그런데 실제로는 realistic sample을 생성하지 못했다. 이 loss의 gradient를 보면 아래와 같다.
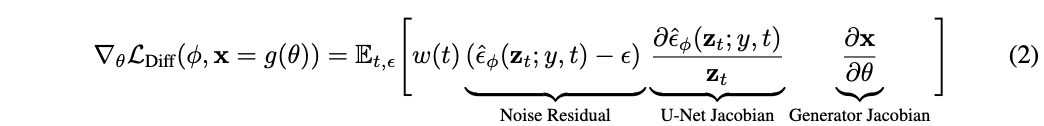
여기서 $\alpha_t \mathbf{I} = \partial \mathbf{z}_t /\partial \mathbf{x}$는$w(t)$로 흡수된다. 위 수식에서 U-Net Jacobian은 계산을 많이 해야하고 marginal density의 scaled Hessian(2차 미분 행력)을 근사하도록 학습되기 때문에 작은 noise level에 대해서는 poorly conditioned된다. 본 논문에서는 실험을 해보니 U-Net Jacobian term을 생략하는 것이 diffusion model에서 DIP를 optimize하기위한 효과적인 gradient를 이끈다는 것을 발견했다.
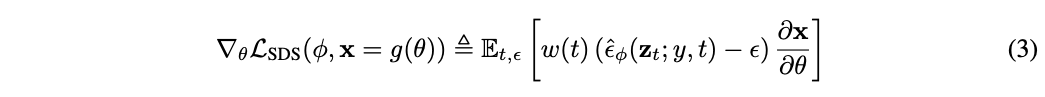
위 수식을 보면 $\frac{\partial \mathbf{x}}{\partial \theta}$만 있기에 $g$만 학습되는 것으로 이해했다. 직관적으로, 이 loss는 $\mathbf{x}$를 timestep $t$에 상응하는 랜덤한 양의 noise로 perturb시킨다.

위 수식을 따라가면 결국 수식 3번은 diffusion model로부터 학습된 score function을 사용한 weighted probability density distillation loss의 gradient가 된다.

본 논문에서의 sampling을 density대신에 score function을 사용하지만 distillation과 관련이 있기에 Score Distillation Sampling(SDS)라고 부른다. 샘플러라고 부르는 이유는 variational family $q(z_t|\cdots)$의 noise가 $t \rightarrow 0$에 따라 사라지고 variational distribution $g(\theta)$의 mean parameter가 우리가 원하는 샘플이 되기 때문이라고 한다. Loss는 다음과 같이 간단하게 구현된다.

Diffusion model이 업데이트 방향을 예측하기 때문에, diffusion model을 통해 backprogate할 필요는 없다.

위 이미지를 보면 SDS가 합당한 퀄리티로 constrained image를 생성하는 것을 볼 수 있다. SDS는 ancestral sampling과 비교할만하게 detail을 생성하는 반면, parameter 공간에서 계산되기 때문에 새로운 transfer learning application이 가능하다.
3. The DreamFusion Algorithm
수정 없이 pretrain된 Imagen의 64*64 base model을 사용하고 NeRF model은 random weight로 초기화해서 사용한다. 이렇게 초기화된 NeRF에서 랜덤한 camera pose와 angle을 통해 렌더링된 이미지를 사용해서 loss를 계산한다. 전체적인 파이프라인은 아래 이미지와 같다.

3.1 Neural Rendering of a 3D Model
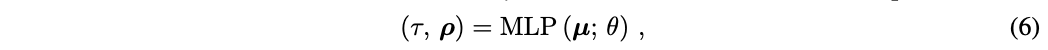
위 수식처럼 3D point의 위치 $\mu$와 그 외 파라미터를 통해 density $\tau$와 albedo color $\rho$(표면에서 반사된 빛?색?을 나타낸다고 함, surface color)를 예측한다. 위 과정처럼 그림자?를 표현해서 더 사실적인 3D를 생성하기 위해 shading이 필요한데, 이를 계산하기 위해 surface normal vector를 이용한다. Surface normal vector는 density $\tau$의 $\mu$에 대한 negative gradient $\mathbf{n} = -\nabla_{\mu}\tau / \Vert \nabla_{\mu} \tau \Vert$로 계산된다. 빛 위치 $l$와 색 $l_\rho$, 주변 빛 색 $l_a$이 주어지면 normal $\mathbf{n}$와 albedo $\rho$를 통해 각 지점의 색 $\mathbf{c}$를 다음과 같이 구할 수 있다.

(3D 관련 추가 디테일한 내용은 skip...)
3.2 Text-to-3D Synthesis
Pretrain된 text-to-image diffusion model, NeRF의 형태에서 differentiable image parameterization, loss function이 주어지면, 3D data 없이 text-to-3D 합성에 필요한 component가 다 주어졌다. 이를 가지고 다음 단계를 반복하면서 최적화가 된다.
1. Camera와 light을 랜덤하게 샘플
각 iteration마다 elevation angle(위아래 각) $\phi_{cam} \in [-10^{\circ} , 90^{\circ}]$, azimuth angle(좌우 각) $\theta_{cam} \in [0^{\circ}, 360^{\circ}]$, distance $[1,1.5]$의 구면좌표계에서 랜덤하게 샘플한다. 또한 focal length도 샘플링 한다. 빛 위치 $l$은 camera 위치 주변에 center된 분포로 부터 샘플링한다. 넓은 카메라 위치 범위는 일관성있는 3D 장면을 합성하는데 중요하고, camera 거리는 학습된 장면의 해상도를 높이는데 도움이 된다고 한다.
2. 그 camera로부터 NeRF의 이미지를 렌더링하고 빛으로 shade
64*64 해상도로 렌더링 시킨다.
3. NeRF parameter들을 통해 SDS loss의 gradient를 계산
카메라의 위치에 따라 다른 text를 이용해서 이미지를 생성한다. 여기서 특징적인 점은 image 생성때 보다 훨씬 높은 CFG weight $w=100$을 준다. 이는 작은 weight를 주면 loss에 의해 over-smoothing한 결과를 보이는 것 때문이라고 한다.
4. Optimizer를 사용해 NeRF 파라미터를 업데이트
Distributed Shampoo optimizer를 이용했다고 하는데 처음 들어보는 optimizer이다...
4. Experiments


CLIP을 이용해 평가를 했는데 DreamField나 CLIP-Mesh는 CLIP을 통해 학습되었지만 DreamFusion은 아닌 것을 감안하면 결과가 좋은 것을 볼 수 있다.
Ablation
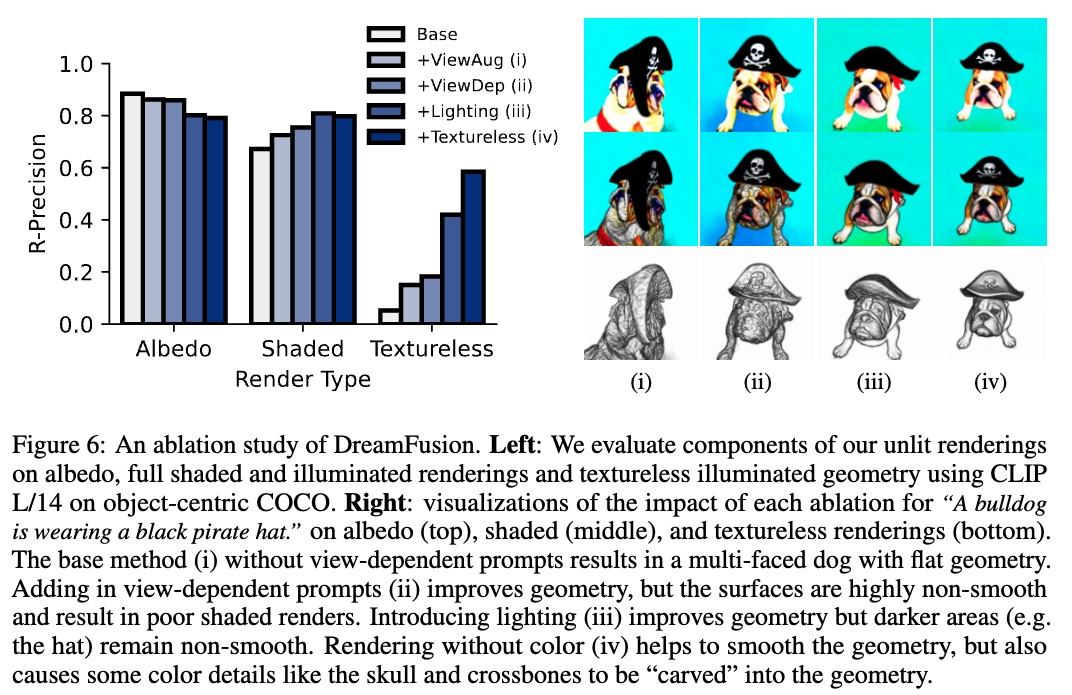
5. Discussion
Limitation
SDS loss는 이미지 샘플링시 완벽한 loss가 아니고 종종 ancestral sampling에 비해 oversaturated하거나 oversmoothed한 결과를 보인다. 그리고 ancestral sampling에 비해 다양성이 부족하다고 한다.
64*64인 Imagen을 이용하기 때문에 디테일이 부족하다.
이번 논문은 뭔가 확 머리 속에 들어오지 않은 듯한 느낌이다. 논문의 50%만 이해한 느낌... 인턴 시작하고 집중을 못하고 있는건가? 암튼 3D 생성에 꾸준히 관심을 가지고 공부할 것 같은데 공부해야할게 엄청 많을 것 같다. 아직 3D 논문을 완전히 이해하기엔 내가 많이 부족한 것 같다.



