

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- memorization
- Vit
- rectified flow
- Python
- image generation
- video editing
- diffusion
- shortcut model
- image editing
- 프로그래머스
- 3d generation
- diffusion models
- DP
- ddim inversion
- flow matching
- 코테
- transformer
- BOJ
- diffusion model
- VirtualTryON
- visiontransformer
- 3d editing
- 네이버 부스트캠프 ai tech 6기
- inversion
- video generation
- Programmers
- 논문리뷰
- flow matching models
- 코딩테스트
- freeinv
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Instruct-NeRF2NeRF : Editing 3D Scene with Instructions (ICCV 2023 oral) 본문
[평범한 학부생이 하는 논문 리뷰] Instruct-NeRF2NeRF : Editing 3D Scene with Instructions (ICCV 2023 oral)
junseok-rh 2024. 6. 19. 23:58https://arxiv.org/abs/2303.12789
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
We propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an image-conditioned diffusion model (InstructPix2Pix) to iteratively edit the input images whi
arxiv.org
1. Introduction
NeRF와 같은 3D reconstruction 기술들 (3D representation 기술)이 상당히 발전한 반면 3D 장면을 editing하는 기술들은 아직 그만큼 발전하지 못했다. 본 논문은 text instruction만을 input으로 3D NeRF 장면을 수정하는 방식인 Instruct-NeRF2NeRF를 제안한다. 이 method는 pre-capture된 3D 장면에 대해 작동하고 수정된 결과가 3D-consistent한 방식으로 반영되는 것을 보장한다.

3D 생성모델도 있지만, 본 논문은 2D diffusion model(InstructPix2Pix)을 사용해서 shape과 appearance prior를 추출하는 것을 선택했다. 이 모델을 각 이미지에 적용하는 것은 viewpoint에 따른 inconsistent edit을 야기한다. 그래서 본 논문에서는 DreamFusion과 같은 3D 생성 solution과 유사한 간단한 접근법을 구상한다. Iterative Dataset Update는 NeRF input 이미지들의 dataset을 수정하고 수정된 이미지를 통합하기 위해 기본 3D representation을 업데이트하는 것을 번갈아가며 수행한다.
2. Related Work
Physical Editing of NeRF
예시로는 ClimateNeRF가 있다. Physically-based edit은 reconstructed scene의 물리적 속성을 바꾸거나 physical 시뮬레이션을 수행한다.
Artistic Stylization of NeRFs
예시로는 EditNeRF, CLIPNeRF, NeRF-Art, Distilled Feature Fields, Neural Feature Fusion Fields와 같은 연구들이 있다.
Generating 3D Content
예시로는 DreamFusion, RealFusion, SparseFusion이 있다.
Instruction as an Editing Interface
예시로는 InstructPix2Pix가 있다.
3. Method
본 논문은 captured image들과 그에 대한 camera pose들, 그리고 camera calibration (source data)에 대응되는 reconstructed NeRF scene과 자연어로 된 editing instruction을 input으로 한다. 주어진 editing instruction에 따라 수정된 NeRF subject와 수정된 버전의 input image들을 output으로 내놓는다.
본 논문에서의 method는 diffusion model(InstructPix2Pix)을 통해 특정 viewpoint에서 image content를 반복적으로 업데이트하고 이를 표준 NeRF 학습을 통해 3D에 통합함으로써 성취한다.
3.1 Background
Neural Radiance Field
https://juniboy97.tistory.com/67
[평범한 학부생이 하는 논문 리뷰] NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis
https://arxiv.org/abs/2003.08934 NeRF: Representing Scenes as Neural Radiance Fields for View SynthesisWe present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumet
juniboy97.tistory.com
InstructPix2Pix
3.2 Instruct-NeRF2NeRF
Reconsturted NeRF 장면과 text instruction이 주어지면, 본 논문에서는 reconstructed model이 edit instruction을 향하도록 finetuning을 해서 수정된 버전의 NeRF를 생성한다.

본 논문의 method는 학습 데이터 이미지들이 반복적으로 diffusion model을 이용해 업데이트되고 그 후 이러한 업데이트된 이미지들로 NeRF를 학습시킴으로써 globally consistent 3D representation로 통합되는 alternating update scheme으로 작동된다.
Editing a rendered image
본 논문에서는 InstructPix2Pix를 이용한다. 이는 input으로 input conditioning image $c_I$, text instruction $c_T$, noisy input $z_t$를 받는다. $v$ viewpoint에서의 dataset image를 업데이트하기 위해, $c_I$를 위해 그 viewpoint에서 originally captured image거나 edit 이전에 NeRF로부터 렌더링 된 이미지 $I^v_0$를 사용한다. SDEdit에서와 같이, $z_t$를 위해 optimization step $i$에서 렌더링된 이미지의 노이즈가 추가된 버전($\mathcal{N}(0,1)$와 $z_0 = \mathcal{E}(I^v_i)$의 linear combination)을 input으로 한다. 이미지 $I_i^v$를 교체하는 과정은 $I_{i+1}^v \leftarrow U_\theta(I^v_{i},t ; I_0^v, c_T)$로 나타낼 수 있다. 여기서 noise level $t$는 $[t_{min}, t_{max}]$에서 랜덤하게 선택된다. $U_\theta$는 DDIM sampling process로 timestep $t$와 $0$사이에서 취해진 고정된 수의 중간 스텝 $s$를 가진다.
Diffusion UNet을 통과하는 noised 이미지$z_t$는 부분적으로만 noised돼 global 3D model의 렌더링은 $z_0$에 대한 diffusion model의 최종 estimate에만 영향을 끼치는 반면 diffusion model은 instruction $c_T$에 따라 원본 이미지 $I_0^v$를 수정하는 것이 목표이다. 중요한 점은 본 논문의 method는 NeRF로부터의 렌더링, 이미지 수정, NeRF 업데이트의 과정을 반복하는 동안 diffusion model은 un-edited 이미지에 condtion된다. 그러므로 반복 합성에 흔히 연관되는 특징 drift를 보호하면서 안전성을 유지한다.
Iterative Dataset Update
본 논문의 method의 핵심 component는 NeRF를 통해 image가 렌더링되고, diffusion model을 통해 업데이트되고, 그 후에 NeRF reconstruction을 지도하도록 사용되는 alternating process이다. 이를 논문에서는 Iterative Dataset Update(IterativeDU)라고 칭힌다.
Optimization이 시작할 때, image dataset은 여러 가지 viewpoint $v$로부터 캡쳐된 이미지 $I^v_0$로 구성된다. 이 이미지들은 따로 저장되고 모든 stage에서 diffusion model에 condition된다. 각 iteration에서, $d$번의 image update를 수행하고 그 후에 $n$번의 NeRF update가 따른다. Image update는 학습 시작에 정해진 $v$의 random ordering에서 순차적으로 수행된다. NeRF update는 전체 training dataset에서 random ray의 집합을 항상 샘플링하므로 supervision signal은 오래된 정보와 최근 업데이트된 데이터셋 이미지들의 mixture를 포함한다.
Editing process는 데이터셋 이미지들과 그들의 수정된 버전의 교체를 야기한다. 초기 iteration에서는 이러한 이미지들은 inconsistent한 edit을 보여준다. 시간이 지나면서 이미지들이 NeRF를 업데이트하기 위해 사용되고 점진적으로 re-render되고 업데이트되면서, 수정된 장면의 전체적으로 일관성있는 묘사로 수렴하기 시작한다.

이 프로세스는 SNeRF에서 제안된 방식과 유사하지만 NeRF update동안 수정된 이미지를 유지하는 본 논문의 IterativeDU와 다른 점을 지닌다. 이는 효율적으로 training dataset에 대해 반영구적인 업데이트를 수행하도록 한다. 또한 이 프로세스는 DreamFusion의 score distillation sampling(SDS) loss의 variant로 해석될 수 있다. (SNeRF와 DreamFusion 두 논문 읽어보지 않아서 그렇구나~하고 넘어갔다... 기회가 된다면 읽어봐야지) IterativeDU의 사용은 각 iteration에서 학습 ray viewpoint들의 다양성을 최대화하는 것이다. 이는 학습 안정성과 효율성을 크게 향상시키는 것을 확인한 선택이라고 한다.
3.3 Implementation Details

4. Results
4.1 Qualitative Evaluation
Editing 3D Scene


3D consistency를 보이기 위해 다양한 view를 보인다. 이미지 1을 보면 global뿐만 아니라 local한 editing도 잘 되는 것을 볼 수 있다. 또한 DreamFusion처럼 완전 새로운 object를 넣는 것은 어렵지만, 본 논문의 method는 contextual elements를 넣는 것이 가능하다. 게다가 사람을 어느 정도 다룰 수 있다. 또한 이러한 editing이 large-scale scene에도 적용이 가능하다.
Ablation Study

Per-frame Edit
본 논문의 가장 naive한 baseline은 original NeRF에 의해 렌더링된 새로운 path의 모든 frame에 대해 독립적으로 InstructPix2Pix를 적용한다는 것이다. $c_I$로 렌더링된 이미지를 쓰고 $c_T$로 동일한 text instruction을 쓴다. $z_t$에 대해 완전한 노이즈를 사용한다.(이게 다른 듯?) Conditioning image가 3D consistent하다는 사실에도 불구하고, 결과 edited 이미지는 다른 view에 따라 상당한 variance(inconsistent)를 지닌다.
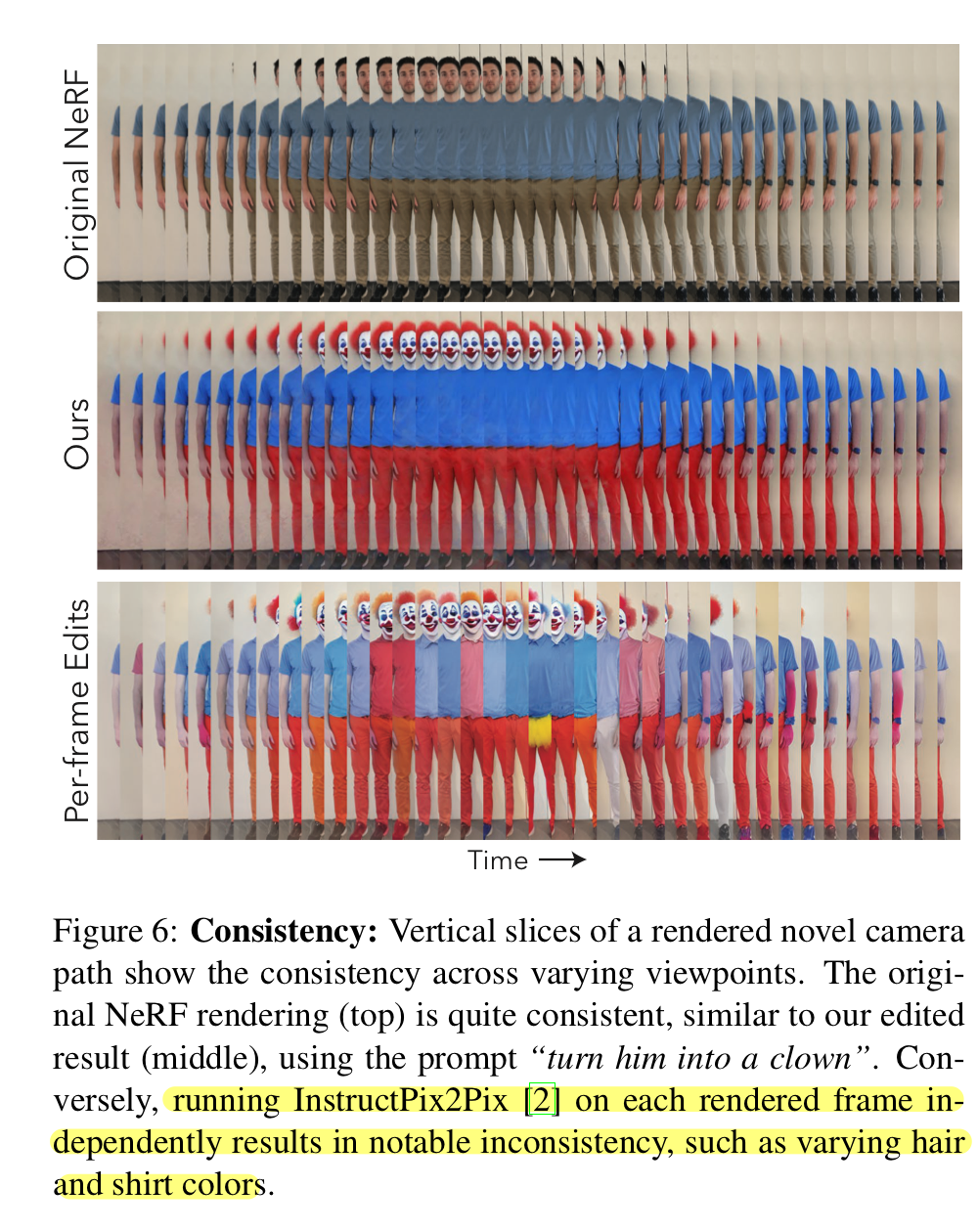
One time Dataset Update
여기서는 모든 학습 이미지들이 한번만 editing된다. 그러고 NeRF가 수렴할 때까지 학습된다. 이 baseline은 per-frame editing 결과의 3D consistency에 크게 의존한다. 대다수의 경우에 초기에 editing된 2D 이미지가 크게 inconsistent해서 blurry하고 artifact-filled 3D scene을 만든다.
DreamFusion(text-conditioned diffusion)
빠르게 발산했다고한다.(그래서 결과도 첨부 안했다고 함) 이러한 결과가 발생한 이유는 모든 이미지는 장면의 textual discription을 필요로하고 모든 view에 대해 장면과 매칭되는 정확한 textual discription을 찾는 것이 어렵다. 이는 image conditioning의 중요성을 강조하는 실험이 됐다.
SDS + InstructPix2Pix
Text-conditioned 실험과 다르게 발산하지는 않지만 더 많은 artifacts를 지닌 3D scene을 보인다. Standard SDS는 전체 이미지들의 작은 collection에서 ray를 샘플링하는데 이는 모든 viewpoint들에 대해 ray를 샘플링하는 것보다 optimization을 더 신뢰할 수 없게 만든다.
Ours + StableDiffusion
InstructPix2Pix대신 Stable Diffusion을 사용하면 DreamFusion의 경우와 같이 image conditioning이 부족해 유사한 issue들을 보인다. 발산하지는 않지만 blurry하고, 3D density가 일관적이지 않다.
Comparisons with NeRF-Art

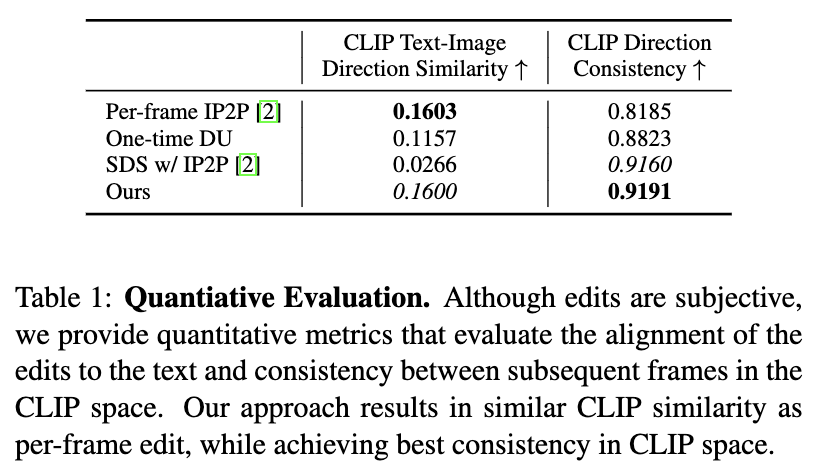
4.2 Quantitative Evaluation
(1) 수행된 3D editing과 text instruction사이의 alignment
(2) view에 따라 수행된 edit의 temporal consistency
4.3 Limitations
실패 사례를 다음과 같은 결과로 보여준다.

(1) InstructPix2Pix가 이미지 editing을 못해서 InstructNerf2Nerf가 3D에서 실패함
(2) InstructPix2Pix는 성공했지만 InstructNerf2Nerf가 통합하는 것을 실패해서 inconsistency를 보임
위 사례들 뿐만 아니라 본 논문의 method는 거대한 공간적인 조작을 수행하지 못하는 InstructPix2Pix의 한계점을 상속받는다. 그리고 추가된 객체에 대한 double faces와 같은 artifact를 보인다. 완전 새로운 객체를 추가하는데 어려움을 겪는다.



