
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- flipd
- Vit
- 프로그래머스
- video editing
- flow matching
- segmenation map generation
- VirtualTryON
- image editing
- 네이버 부스트캠프 ai tech 6기
- masactrl
- transformer
- 논문리뷰
- 3d generation
- visiontransformer
- diffusion model
- 3d editing
- segmentation map
- Python
- inversion
- memorization
- 코딩테스트
- video generation
- diffusion
- BOJ
- noise optimization
- 코테
- diffusion models
- DP
- Programmers
- rectified flow
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] TrAME : Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation (arXiv 2407) 본문
[평범한 학부생이 하는 논문 리뷰] TrAME : Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation (arXiv 2407)
junseok-rh 2024. 7. 13. 20:21https://arxiv.org/abs/2407.02034
TrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation
Despite significant strides in the field of 3D scene editing, current methods encounter substantial challenge, particularly in preserving 3D consistency in multi-view editing process. To tackle this challenge, we propose a progressive 3D editing strategy t
arxiv.org
1. Introduction
3D editing의 key challenge 중 하나는 multi-view consistency를 유지하는 것이다.
Optimization-based Method
Score Distillation Sampling (SDS)나 SDS의 다른 버전을 적용한다. 이러한 종류의 방식들은 over-saturation, over-smoothing, 다양성 부족 등의 문제를 가진다. 여기서 다양성 부족은 SDS optimization에서 랜덤하게 샘플링된 timestep t와 diffusion sampling process에서의 timestep t사이의 misalignment에 의해 발생한다. Diffusion model inference시에는 t=T→0인 반면 SDS는 t∼U(1,T)여서 misalignment가 발생한다고 한다. 이는 DreamTime이라는 논문에 자세히 나와있는데 대충 봤을 때 이런 식으로 설명하는 것 같다.
Reconstruction-based Method
2D diffusion model을 이용해서 이미지를 editing하고 그걸로 3D editing하는 방식이다. 이는 2D diffusion model이 multi-view consistency를 보이기가 힘들다는게 문제이다.
본 논문에서는 위 두 가지 갈래의 방법론들 사이의 관계를 이론적으로 보이고 optimization-based 방식들이 reconstruction-based 방식들의 특수한 경우라는 것을 증명한다. 이러한 분석을 기초로, 본 논문에서는 Trajectory-Anchored Multi-View Editing(TrAME)을 제안한다. 이 방법론의 core idea는 Trajectory-Anchored Scheme(TAS)라고 한다.
Contribution
- 이론적인 분석을 통해 optimization-based와 reconstruction-based 사이의 차이를 연결하고 우세한 디자인 선택을 하기 위한 통합된 관점을 제공
- Multi-view consistency를 보장하는 progressive 3D editing 전략을 제안
- Editing 결과의 3D consistency를 강화하는 tuning-free VCAC module 제안
- 기존 SOTA 모델들보다 향상된 multi-view consistency를 보임
2. Related Work
Optimization-based 3D editing
SDS framework에서 랜덤 샘플링된 timestep t를 사용하기 때문에 의도된 diffusion sampling trajectory로부터의 이탈을 이끌고 이는 3D editing의 손상된 결과를 이끈다.
Reconstruction-based 3D editing
이러한 방식들은 종종 inter-view correlations를 무시하기 때문에 다양한 view들에 따른 semantic과 structural consistency를 유지하는 것에서 격차를 보이고 이는 error accumulation을 이끈다.
3. Preliminaries
3.1 Score Distillation Sampling (SDS)
https://juniboy97.tistory.com/72
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
https://arxiv.org/abs/2209.14988 DreamFusion: Text-to-3D using 2D DiffusionRecent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require l
juniboy97.tistory.com
3.2 Denoising Diffusion Consistent Model
DDIM의 sampling 절차는 아래의 수식과 같다.

여기서 σt:=√1−αt−1인 특수한 generative process에 대해 다음 수식이 되는데 이를 Denoising Diffusion Consistent Model (DDCM)이라고 한다.
(연구실 인턴 끝나고 제대로 읽어봐야겠다..ㅎㅎ)
4. Methodology
4.1 Analysis on Optimization-based Editing
SDS loss function의 gradient는 rendered view를 pseudo-ground-truth ˆz(t)0에 매칭시키도록 최적화하기 위해 얻어지는 gradient와 동등하다.
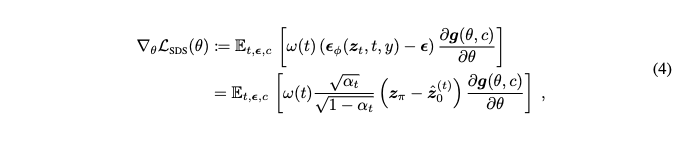
여기서 zϕ는 rendered image의 latent이다.
SDS loss는 딜레마를 가진다. Rendered imaged의 out-of-domain 이슈를 해결하기 위해서는 앞 stage에서는 큰 noise를 사용해야한다. 하지만 큰 noise는 original image의 정보를 붕귀시키고 optimization process를 불안정하게 만든다. 그러므로 anneling timestep 스케줄을 적용하는 것이 합당하다. Timestep t가 annealing schedule을 따른다는 가정을 가지고 시작한다. Pseudo-ground-truth를 rendered image의 latent zϕ, timestep t, condition y, 추가된 노이즈 ϵ의 함수로 다음과 같이 쓸 수 있다.
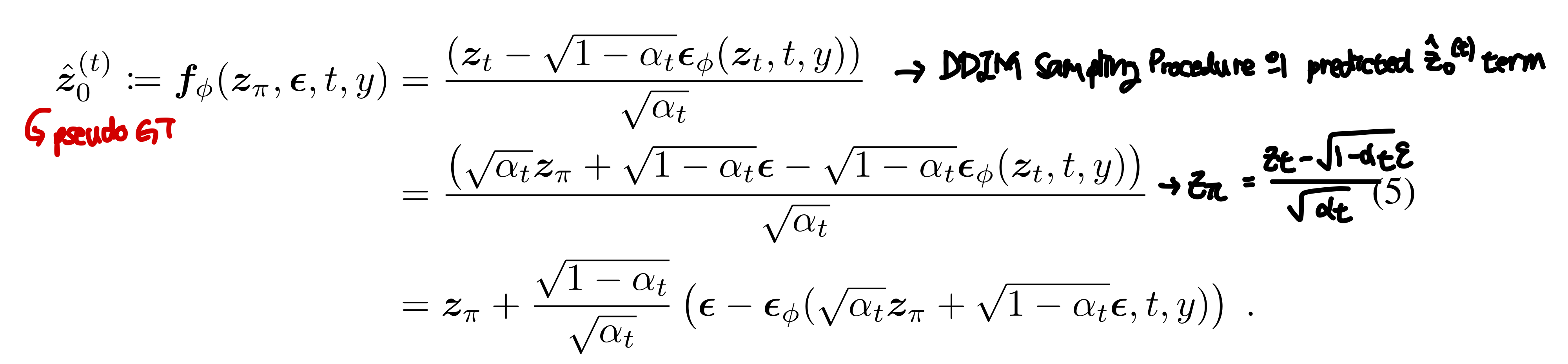
또 수식 3에서 DDCM이 zt의 dynamics을 보이는 것을 주목해보면 ˆz(t)0의 dynamics를 모델링하기 위해 다음과 같이 쓸 수 있다.
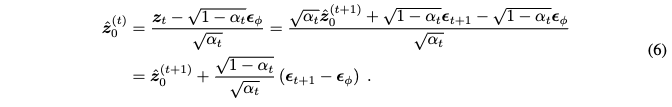
이를 통해 수식 6의 dynamics와 수식 5의 SDS의 optimization이 상당히 닮은 것을 볼 수 있다. Annealing timestep 스케줄을 따르는 SDS를 가정하면, SDS optimization은 iterative reconstruction 절차와 동등하다. 1) DDCM을 가지고 사전에 rendered image들로부터 만들어진 noisy latent를 사용하여 다음 스텝 pseudo-ground-truth를 샘플링한다. 2) Pseudo-ground-truth와 매칭시키기 위해 reconstruction loss를 최적화한다. 이를 통해 더 일반적이 iterative reconstruction 관점으로부터 3D editing 방식들의 디자인을 고려하도록 한다.
4.2 Trajectory-Anchored Scheme for Progressive 3D Gaussian Editing
위 섹션을 통해 optimization-based 접근법이 reconstruction-based 방식의 특수한 case인 것을 보였다. Generality를 잃지 않고, 본 논문에서는 더 광범위한 reconstruction-based 관점으로부터 3D editing 방식의 디자인을 고려한다. 향상된 3D Gaussian editing 방식에 대한 key question은 다음 두가지이다. (1) 어떤 적절한 reconstruction pseudo-ground truth를 사용할 것인가, (2) 3D editing을 위해 progressive한 방식으로 3D Gaussian들의 reconstruction 프로세스를 어떻게 스케줄링할 것인가.
본 논문에서는 trajectory-anchored progressive 3D Gaussian editing scheme을 제안한다. 이 방식은 image editing 프로세스와 rendering 프로세스를 더 타이트하게 연결함으로써 3D rendering이 progressive 2D multi-view edit에서 inconsistencies를 완화할 수 있도록 한다. 특히 modified DDCM editing trajectory에 의해 생성된 이미지를 사용하는데, 이는 3D Gaussian editing에 대한 적합한 pseudo ground truth가 된다고 한다. 이러한 pseudo-ground truth들은 아래의 이미지처럼 source image에서 target image로 부드러운 변화를 가능하게 해서 progressive 2D editing과 3D updating scheme에 대해 이상적으로 만들어준다고 한다.

2D view에 대한 점진적인 editing은 3D Gaussian에 즉시 적용될 수 있다. 반대로, 2D editing때문에 발생한 minor view inconsistencies는 3D constrained rendering을 통해 즉시 완화될 수 있다. Loss 함수는 다음과 같다.
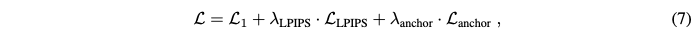
(Anchor loss는 GaussianEditor 논문에서 제안된 것 같은데 공부해봐야겠다!)
4.3 View-Consistent Attention Control
다양한 view들에 대해 consistency를 보장하는 것은 3D Gaussian들의 효율적인 optimization에 대해 중요하다. 본 논문에서 이를 위해 3D view prior로써 original view로부터 구조적인 정보를 활용해 target view의 공간적인 layout에 대해 구조적인 제약을 도입하는 dual-branch editing scheme을 제안한다. 거기에 더해, view에 따라 의미적인 consistency들을 강화하는 KV propagation과 KV reference 메커니즘을 사용한다.
본 논문에서는 3D consistent editing을 달성하기 위해 source branch와 target branch를 활용한다. Source branch는 수정되지 않은 original view를 취하는데 이는 target branch에 대한 reference 역할을 한다. 이를 통해 editing된 view를 생성하는데 구조적, 의미적 guidance를 제공한다. 이전 연구에서 이미지의 구조적인 layout은 diffusion의 이른 stage에 형성되고 self-attention query들에 밀접하게 연관된다는 것을 보였다. 그래서 본 논문에서는 이른 diffusion stage동안 source branch에서 target branch로 self-attention query들을 주입한다. Query injection은 수식 9와 같이 수행된다.
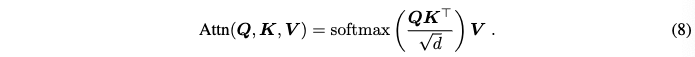
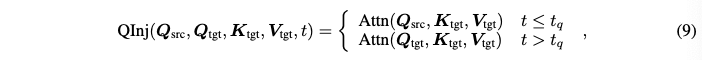
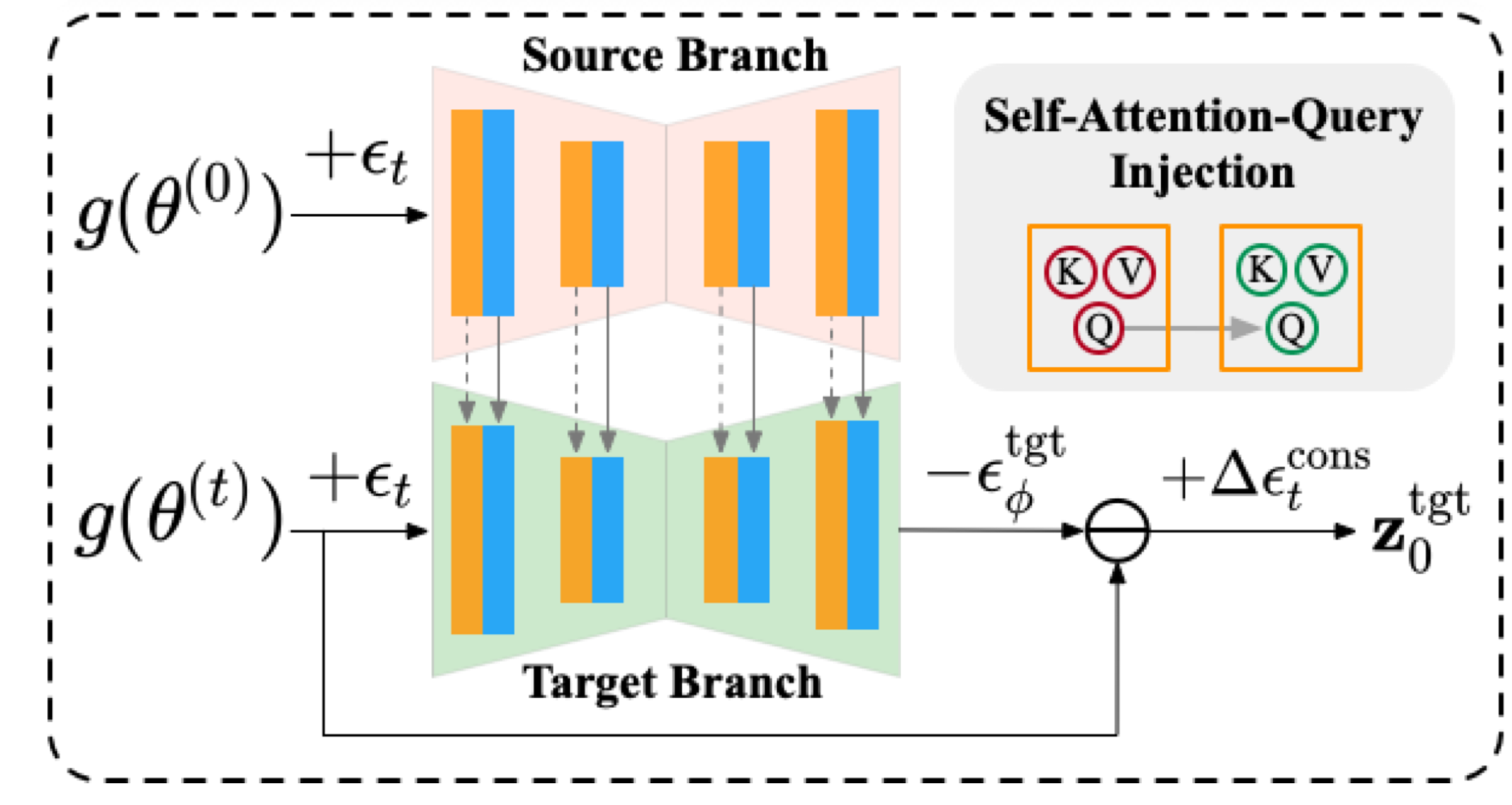
Semantic multi-view consistency 또한 중요하기 때문에 본 논문에서는 KV propagation과 KV reference 메커니즘을 구현한다. 연속적인 카메라 motion으로부터 N개의 view로 이루어진 sequence {In}Nn=1가 주어지면, sequence를 동일하게 나눠진 context segments {Ci}Li=1로 나눈다. 각 context Ci는 N/L 프레임의 길이이고 keyframe Ii1를 포함한다. 동일한 context내 view들은 최소한의 움직임과 view shift를 보이고 그들의 semantic들은 상대적으로 consistent하다. 동일한 context내의 view들에 대해 효율적인 KV propagation 방식을 사용한다. 이를 통해 i번째 keyframe의 self-attention key와 value {Ki1,Vi1}가 동일한 context에서 나머지 프레임들에 직접적으로 전파된다. i번째 context에서 j번째 프레임의 self-attention의 output을 다음과 같이 쓸 수 있다.
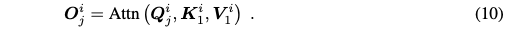
KV propagation을 다른 context에 대한 keyframe들에 적용하는 것은 상당한 왜곡을 축적할 수 있다. 이러한 문제를 완화하기 위해, contexts에 따라 keyframes에 KV reference를 적용한다. 이는 다른 context들의 keyframe들에 걸쳐 self-attention key들과 value들을 부풀리고 그들을 joint하게 처리하는 것을 포함한다. 다른 프레임으로부터의 self-attention key와 value들은 editing된 개체의 의미적 정보에 대한 상호 reference로 작동한다. l개의 다른 keyframe들로부터의 self-attention key {Ki}li=1와 value {Vi}li=1에 대해, 본 논문에서는 각각 concat해서 cross-context KV 페어를 만든다. 계산은 다음과 같이 된다.
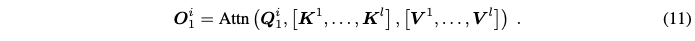
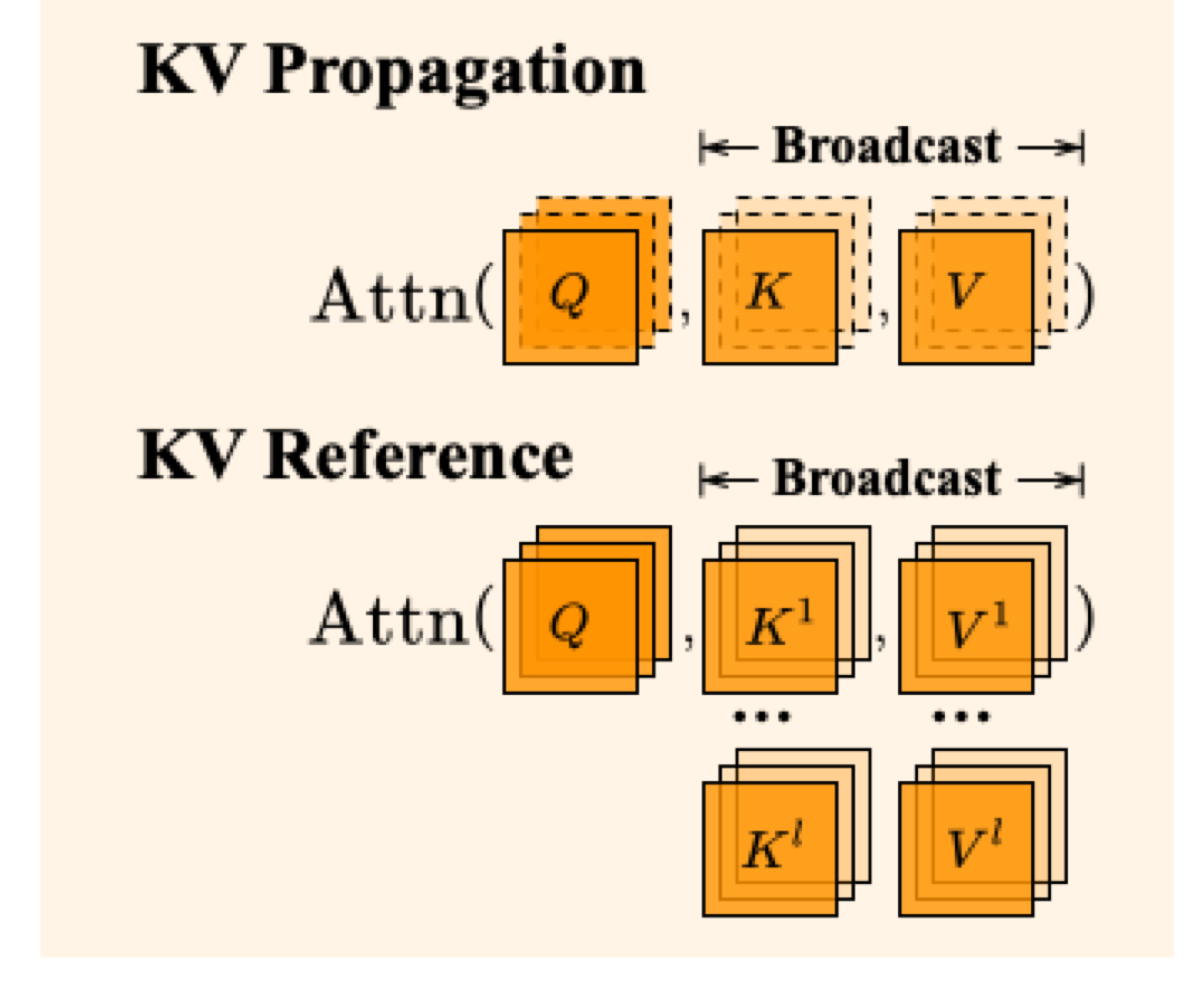
위 이미지가 KV propagation과 KV reference를 보여준다. 위 그림에서 Broadcast가 어떻게 broadcast를 하는건지 이해가 잘 가지 않는다...
Original 이미지의 editing되지 않는 지역에서 fidelity를 유지하기 위해, cross-attention control과 local blending 전략을 적용한다. Cross-attention control은 target branch에서 non-edited token들에 대응되는 attention map을 source branch에서 token들에 대응되는 attention map으로 교체하는 것이다.
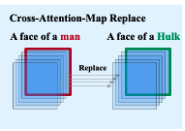
Semantic tracing(GaussianEditor 논문에 나온 방식)을 통해 얻어진 semantic mask M을 사용해 다음과 같이 noisy target latent를 source latent와 혼합한다.
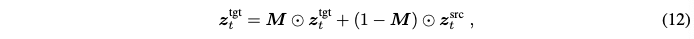
여기서 ⊙은 원소별 곱이다. 결국 3D consistent view edit들은 rectified하고 progressive한 방식으로 3D Gaussian들에 통합된다.
5. Experiments

5.3 Quantitative Results
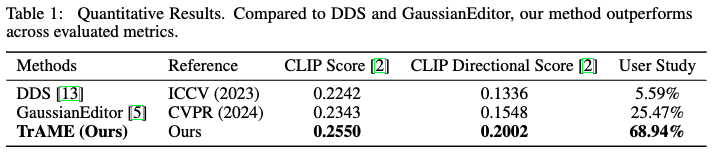
5.4 Qualitative Results


5.5 Ablation Studies

VCAC가 cross-view structural and semantic consistency를 강화하는 것을 보여준다. 또 다양한 view에 따라 일정한 외형을 유지하는 것을 보여준다.

TAS가 더 자연스럽고 일관된 외형을 생성하는 것을 보여준다.
최근에 나온 논문이라 바로 봤는데, 아직 appendix가 없어서 아쉽..ㅜㅜ appendix 나오면 다시 봐서 내용을 추가할 필요가 있을 것 같다. 특히 TAS 부분은 appendix에 정확한 알고리즘이 있다고해서 꼭 봐야할 것 같다. 또 DDCM이나 아직 공부하지 못한 부분들을 많이 응용하는 것 같아서 시간될 때 종종 찾아서 읽어야할 것 같다



