
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- video editing
- Python
- Machine Unlearning
- rectified flow matching models
- inversion
- rectified flow
- 논문리뷰
- diffusion models
- 코테
- Programmers
- diffusion
- 프로그래머스
- BOJ
- 3d generation
- memorization
- visiontransformer
- image generation
- flow matching models
- video generation
- rectified flow models
- flow matching
- flow models
- image editing
- 네이버 부스트캠프 ai tech 6기
- ddim inversion
- unlearning
- Concept Erasure
- diffusion model
- 3d editing
- VirtualTryON
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Style Aligned Image Generation via Shared Attention (CVPR 2024) 본문
[평범한 학부생이 하는 논문 리뷰] Style Aligned Image Generation via Shared Attention (CVPR 2024)
junseok-rh 2024. 10. 16. 23:50Project Page : https://style-aligned-gen.github.io/
StyleAlign
Style Aligned Image Generation via Shared Attention CVPR 2024, Oral Amir Hertz* 1 Andrey Voynov* 1 Shlomi Fruchter† 1 Daniel Cohen-Or† 1,2 1 Google Research 2 Tel Aviv University *Indicates Equal Contribution †Indicates Equal Advising [Paper]
style-aligned-gen.github.io
Paper : https://arxiv.org/abs/2312.02133
Style Aligned Image Generation via Shared Attention
Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing metho
arxiv.org
1. Introduction
본 논문에서 해결하려는 문제
기존의 SOTA T2I model들은 다음 이미지와 같이 동일한 스타일의 descriptor에 대한 해석이 상당히 다양한 이미지를 생성한다.

최근의 다른 method
최근의 method는 동일한 스타일을 공유하는 이미지 set에 대해 T2I 모델을 finetuning함으로써 이를 완화하려했다. 하지만 이는 computationally expensive하고 content와 style의 disentanglement을 가능하게 하는 이미지와 텍스트의 그럴듯한 subset을 찾기 위해 human input을 종종 필요로 한다.
본 논문의 method
본 논문은 생성된 이미지의 set을 통해 consistency style interpretation을 가능하게 하는 StyleAligned라는 method를 제안한다.

StyleAligned는 optimization을 필요로 하지 않고, 어떤 attention-based T2I diffusion model에도 적용될 수 있다. 본 논문에서는 diffusion process에 최소한의 attention sharing operation을 추가함으로써 style-consistent set을 만들어낼 수 있다는 것을 보인다. 또한 diffusion inversion을 사용해서, optimization이나 finetuning없이 reference style image를 통해 style-consistent image를 생성할 수 있다.
2. Method
본 논문의 목표는 text prompts $y_1, \cdots, y_n$에 aligne되고 각각 일관적인 style interpretation을 공유하는 images $\mathcal{I}_0, \cdots, \mathcal{I}_n$를 생성하는 것이다.

가장 naive한 방식은 바로 shared style discription을 사용하는 것이다. 하지만 이럴 경우 각 이미지들은 generation process동안 다른 이미지들의 정확한 appearance를 인식하지 않는다.
본 논문의 접근 방식의 key insight는 다양한 생성된 이미지들 사이에 communication을 가능하도록 하는 self-attention mechanism에 대한 활용이다. 이는 생성된 이미지에 따른 attention layer들을 공유함으로써 가능하다.
$Q_i, K_i, V_i$는 이미지 $\mathcal{I}_i$의 deep features $\phi_i$로부터 projection된 쿼리, 키, 벨류라고 하면, $\phi_i$에 대한 attention update는 다음과 같다.
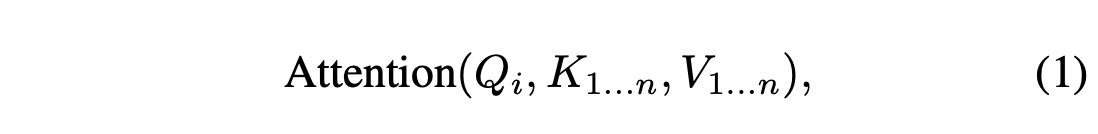
여기서 $K_{1 \dots n} = \begin{bmatrix} K_1 \\ K_2 \\ \vdots \\ K_n \end{bmatrix}$, $Q_{1 \dots n} = \begin{bmatrix} Q_1 \\ Q_2 \\ \vdots \\ Q_n \end{bmatrix}$이다.

그러나 full attention sharing을 하면, 생성된 이미지 set의 퀄리티가 떨어진다고 한다. 위 이미지에서 아래 이미지들을 보면 full attention sharing은 이미지들에 대해 content leakage를 초래하는 것을 볼 수 있다. 게다가, full attention sharing은 동일한 prompts에 대해서 덜 다양한 결과를 생성한다.
이를 해결하기 위해서 본 논문은 생성된 이미지 set에서 오로지 한 장의 이미지에게만 attention을 share한다. 즉, target image feature $\phi_t$는 그것들 스스로와 방정식 1을 사용해서 단 하나의 reference image의 feature에 attend한다. 단 하나의 이미지에 attention을 공유하는 것은 유사한 스타일을 공유하는 다양한 sets를 야기한다. 하지만 다른 이미지의 style은 잘 align되지 않는 것을 볼 수 있다.
이 문제를 해결하기 위해 본 논문에서는 다음과 같은 AdaIN을 사용해서 target image의 쿼리와 키를 reference image의 쿼리와 키를 이용해 normalize한다.
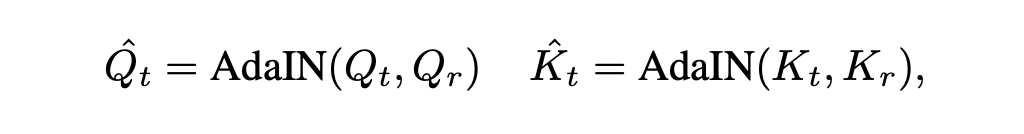
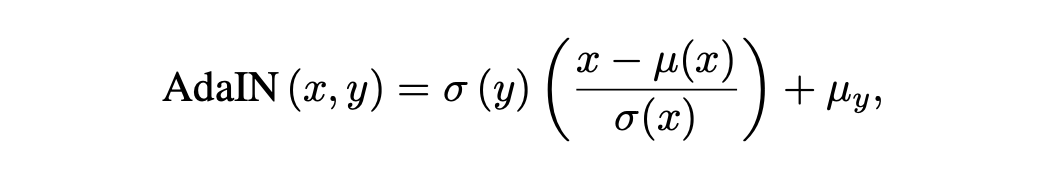
결국 shared attention은 다음과 같다.

여기서 $K_{rt} = \begin{bmatrix} K_r \\ \hat{K}_t \end{bmatrix}, V_{rt} = \begin{bmatrix} V_r \\ V_t \end{bmatrix}$이다.
전체 계산 방식은 다음과 같다.

3. Evaluation and Experiments
본 논문에서는 image와 text사이의 유사도는 CLIP을 사용했고, style consistency에 대해서는 DINO를 사용했다.
3.1 Ablation Study


위 정량적인 결과에서도 볼 수 있듯이, 본 논문의 기법은 text alignment에 대한 적은 희생으로 높은 style consistency를 보인다. Ablation test에 대한 정성적인 결과는 오른쪽 이미지에서 확인할 수 있다.
3.2 Comparisons

위 결과는 본 논문의 method와 T2I personalization methods인 StyleDrop과 Dreamboot-LoRA를 정성적으로 비교한 결과이다. 위 결과를 보면 본 논문의 method가 style 특성에 대해 더 consistent한 것을 볼 수 있다. 또 personalization-based methods는 reference image의 content가 다른 이미지에도 나타나는 경향을 보인다. 이러한 이유로 이러한 method들은 더 낮은 text similarity와 더 높은 set consistency score를 보인다.
또, encoder-based personalization method인 ELITE와 IP-Adapter, BLIP-Diffusion과도 비교했을 때, 다른 baseline 모델들과 비교해서 안좋은 결과를 보인다. 이는 input image의 content와 style을 disentangle하는데 어려움을 겪기 때문이라고 저자들은 말한다.
3.3 Additional Results
Style Alignment Control

StyleAligned from an Input Image
Input image를 통해 BLIP으로 caption을 생성하고, DDIM inversion을 통해 노이즈를 만든다. 이 caption과 노이즈를 통해 style-aligned image를 생성할 수 있다.


Shared Self-Attention Visualization


위 결과를 통해 self-attention tokens sharing은 global style transfer를 수행하는게 아니라 semantically meaningful way로 style을 매칭시킨다는 것을 보여준다. 또한 의미적으로 연관된 지역을 강조하는 것 또한 볼 수 있다.
StyleAligned with Other Methods
Training이나 optimization을 필요로 하지 않기 때문에, 다른 diffusion-based model과 쉽게 결합할 수 있다.

4. Conclusions
본 논문은 style-aligned image generation이라는 문제를 다룬 StyleAligned라는 모델을 제안한다. Diffusion process동안 AdaIN과 attention sharing을 통해 생성된 이미지들 사이의 style consistency과 visual coherence를 성공적으로 보였다.



