
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- flow models
- rectified flow matching models
- 네이버 부스트캠프 ai tech 6기
- BOJ
- image generation
- rectified flow
- memorization
- rectified flow models
- diffusion model
- image editing
- Machine Unlearning
- Python
- video editing
- Programmers
- 3d editing
- inversion
- VirtualTryON
- Concept Erasure
- 논문리뷰
- 코테
- unlearning
- diffusion
- visiontransformer
- diffusion models
- flow matching
- video generation
- 프로그래머스
- 3d generation
- flow matching models
- ddim inversion
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] InstaFlow : One Step is Enough for High-Quality Diffusion-based Text-to-Image Generation (ICLR 2024) 본문
[평범한 학부생이 하는 논문 리뷰] InstaFlow : One Step is Enough for High-Quality Diffusion-based Text-to-Image Generation (ICLR 2024)
junseok-rh 2025. 2. 11. 00:39Paper : https://arxiv.org/abs/2309.06380
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Diffusion models have revolutionized text-to-image generation with its exceptional quality and creativity. However, its multi-step sampling process is known to be slow, often requiring tens of inference steps to obtain satisfactory results. Previous attemp
arxiv.org
Abstract

기존 diffusion model의 문제점
multi-step sampling process → 시간이 오래 걸림
본 논문의 해결법
Rectified Flow의 core인 reflow가 noise와 image사이의 assignment를 향상시키는데 중요한 역할 → 이를 이용해서 SD를 ultra-fast one-step model로 바꾸는 novel text-conditioned pipeline InstaFlow 제안한다.
1. Introduction
고퀄리티의 image를 생성하는 모델들이 많이 나왔다. (DALL-E, Imagen, Stable Diffusion, StyleGAN-T, GigaGAN)
하지만, 이러한 모델들은 excessive inference time과 computational consumption이라는 단점을 지닌다.
Knowledge distillation으로 해결하는 approach도 있지만 여전히 diffusion model에서 성능 좋은 one-step model은 나오지 않고 있다. 또한 GAN같은 경우는 one-step이지만 careful tuning을 필요로 한다.
본 논문에서 SD로부터 새로운 one-step generative model을 제시한다. 본 논문에서 SD의 단순한 distillation은 complete failure를 야기하는 것을 관찰했다. 이는 noise-data의 sub-optimal coupling으로부터 발생한다. 이는 distillation process를 상당히 방해한다. 이 문제를 해결하기 위해서, 본 논문에서는 Rectified Flow를 이용한다. 이는 적거나 한번의 Euler step으로 빠른 simulation을 통해 수정할 수 있는 straight flow models을 학습하는 generative model이자 optimal transport의 최근 approach이다. Rectified Flow는 data distribution을 potentially curved flow model로 matching하는 것에서 시작한다. 그리고 reflow procedure를 통해 flow의 trajectory를 straighten한다. 이를 통해 noise distribution과 image distribution 사이의 transport cost를 줄인다. 이 coupling에서의 향상은 distillation process를 상당히 용이하게 한다. 본 논문은 large text-to-image models을 1-flow로 두고 reflow를 통해 이를 straighten하는 것에 집중한다.
InstaFlow는 pure supervised learning을 통해 GAN과 동등하게 perform하는 첫 distilled one-step SD model이다.

2. Method
2.1 Efficient Inference is Needed for Large-scale Text-to-Image Generation
기존 SD는 반복적인 특성때문에 시간이 오래걸림
해결방안
- post-hoc samplers → solver나 DDIM ⇒ inference step이 10보다 작아지면 성능 하락
- progressive distillation → 만족스러운 퀄리티의 one-step model로 바꾸는데 여진히 문제 존재
2.2 Rectified Flow and Relow
Rectified Flow : generative modeling과 domain transfer를 위한 unified ODE-based framework로 empirical observation으로부터 두 분포 $\pi_0,\pi_1$사이의 transport mapping $T$를 학습하는 방식 제공
RF는 다음과 같은 ODE나 flow model을 통해 $\pi_0$에서 $\pi_1$로 transfer를 학습
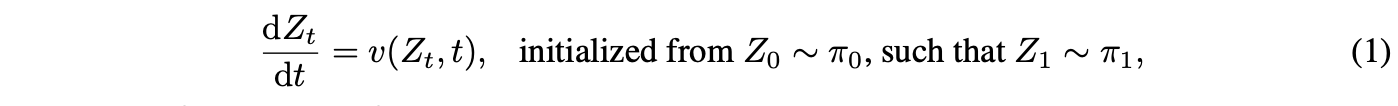
여기서 $v : \mathbb{R}^d \times [0,1] \rightarrow \mathbb{R}^d$는 velocity field이고 다음 simple mean square objective를 최소화함으로써 학습됨

$X_t = \phi(X_0,X_1,t)$ : $X_0,X_1$사이의 any time-differentiable interpolation($\frac{d}{dt}X_t = \partial_t\phi(X_0,X_1,t)$)
$\gamma$ : any coupling of $(\pi_0,\pi_1)$ (e.g. independent coupling $\gamma = \pi_0 \times \pi_1$ → sampled from unpaired observed data from $\pi_0, \pi_1$)
interpolation process $X_t$에 대한 다른 선택은 다른 알고리즘을 야기함
DDIM과 probability flow ODE에서는 $X_t = \alpha_tX_0 + \beta_tX_1$
그러나 rectified flow 저자들은 아래와 같은 선택을 제안

이는 fast inference에서 중요한 역할을 하는 straight trajectory를 도움
Straight Flows Yield Fast Generation
(1)의 ODE는 numerical solver를 통해 approximate될 필요가 있음 → 가장 흔한 접근법은 Euler Method
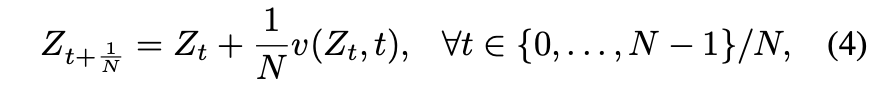
step size $\epsilon = 1/N$으로 simulate하고 $N$ step으로 simulation을 끝냄
$N$의 선택은 cost-accuracy trade-off를 지님
Fast simulation을 위해서는 작은 $N$으로 정확히 빠르게 simulate될 수 있는 ODE 학습이 바람직 함
→ Trajectory가 straight line인 ODE를 야기
다음과 같을 때, ODE는 동일한 speed로 straight하고 함
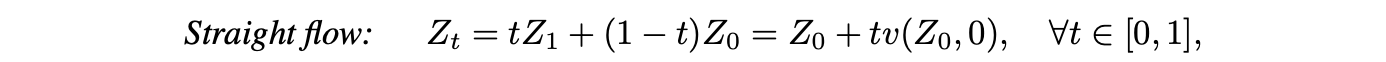
이 경우에 single step인 Euler method로 perfect simulation이 가능
Straightening ODE trajectory는 inference cost를 줄이는데 필수적임
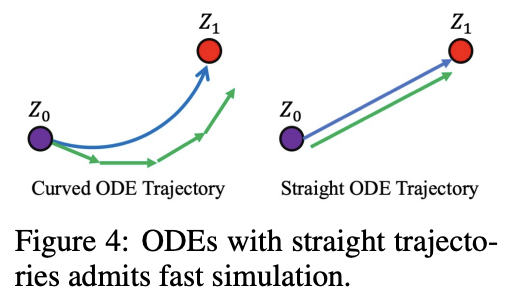
Reflow : marginal distribution을 수정하지 않고 rectified flow의 trajectory를 straighten하는 iterative procedure
이를 통해서 inference에 fast simulation이 가능함
T2I generation에서 velocity field $v$는 그에 대응되는 image를 생성하기 위해서 target prompt $\mathcal{T}$에 추가적으로 의존해야함
Text-conditioned reflow objective :
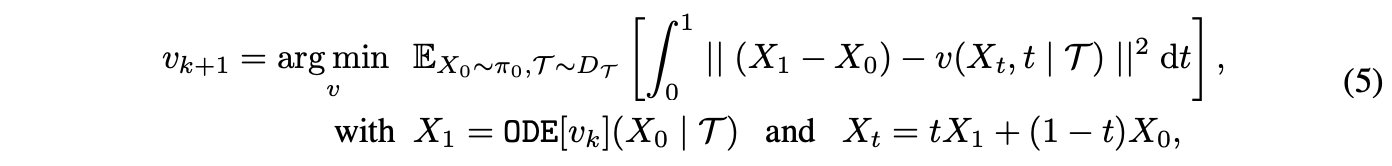
$D_\mathcal{T}$ : dataset of text prompts
$\mathrm{ODE}[v_k] = X_0 + \int^1_0v_k(X_t,t|\mathcal{T})$
$v_{k+1}$ : (2)와 동일한 rectified flow objective를 사용해서 학습되지만, 이전의 $\mathrm{ODE}[v_k]$를 통해 만들어진 $(X_0,X_1)$페어의 linear interpolation (3)을 이용함.
Reflow의 key property는 particle trajectory는 straightening하고 transport mapping의 transport cost는 줄이면서 terminal distribution(target distribution인듯)은 보존하는 것
- $\mathrm{ODE}[v_{k+1}]$과 $\mathrm{ODE}[v_k]$의 분포는 동일함 → $v_k$ 정확한 image distribution $\pi_1$을 생성하면 $v_{k+1}$도 생성함
- $\mathrm{ODE}[v_{k+1}]$의 trajectory가 $\mathrm{ODE}[v_k]$의 trajectory보다 straight → 더 적은 Euler step을 필요로 함. $v_k$가 reflow의 fixed point면($v_{k+1} = v_k$), $\mathrm{ODE}[v_k]$는 정확히 straight
- $(X_0, \mathrm{ODE}[v_{k+1}])$은 $(X_0, \mathrm{ODE}[v_{k}])$보다 더 좋은 coupling을 형성해 lower convex transport cost를 생성. 모든 convex function $c : \mathbb{R}^d \rightarrow \mathbb{R}$에 대해서 $\mathbb{E}[c(\mathrm{ODE}[v_{k+1}]-X_0)] \leq \mathbb{E}[c(\mathrm{ODE}[v_{k}]-X_0)]$ → 새로운 coupling이 student network가 학습하기에 더 쉬움
$v_1$을 SD($v_{SD}$)와 같은 pretrained probability flow ODE model의 velocity field로 셋팅
k-Rectified Flow를 $v_k$라 함
Text-Conditioned Distillation
이론적으로는 reflow를 무한히 하는게 좋지만 high computational cost와 accumulation of optimization and statistical error로 실용적이지 않음
Rectified flow 논문에서 1번혹은 2번이면 거의 straight해진다고 밝힘
이러한 거의 straight한 ODE를 가지고, one-step model의 performance를 높이는 방식은 distillation임.
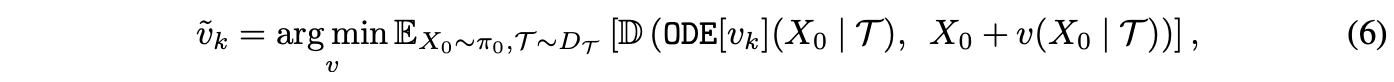
여기서 두 이미지 사이의 미분가능한 similarity loss $\mathbb{D}(\cdot, \cdot)$→ LPIPS loss를 최소화 함으로써 single Euler step $x + v(x|\mathcal{T})$를 $X_0$에서 $\mathrm{ODE}[v_k]$로의 mapping을 압축하도록 학습함
Distillation and Reflow are Orthogonal Techniques
Distillation과 Reflow의 차이를 아는게 중요!
Distillation : $X_0$로부터 $\mathrm{ODE}[v_k]$로의 mapping을 근사하려 함
Reflow : 더 낮은 convex transport cost 때문에 더 regular하고 smooth한 새로운 mapping $\mathrm{ODE}[v_{k+1}]$을 생성
Reflow는 distillation 전에 optional한 step이고 둘은 orthogonal함
Distillation을 하기 전에 mapping $\mathrm{ODE}[v_k]$를 충분히 regular하고 smooth하게 하기 위해서 reflow를 하는 것이 필수적임
Classifier-Free Guidance Velocity Field for Text-Conditioned Rectified Flow
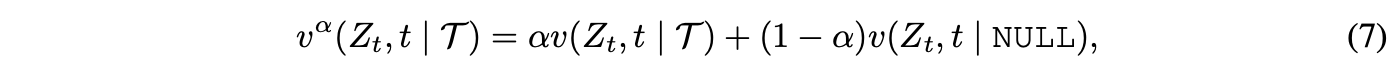
3. Preliminary Results : Reflow is the Key to Improve Distillation
SD 1.4를 가지고 Rectified Flow와 reflow procedure의 효과를 실험함
실험 목표는 다음과 같음
- 간단한 distillation이 pre-trained large-scale T2I probability flow ODE로부터의 one-step model을 학습시키는데 효과적인지 실험
- text-conditioned reflow가 distillation의 performance를 강화할 수 있는지 실험
결론
- Reflow가 distillation의 process를 학습시키는 것을 상당히 쉽게 만듦
- Reflow후의 distillation은 성공적으로 one-step model을 생성함
3.1 General Experiments Settings

3.2 Direct Distillation Fails, While Reflow + Distillation Succeeds
Experiment Protocol
Direct Distillation
- Reflow 적용하지 않고 (6)으로 SD1.4의 velocity field $v_1 = v_{sd}$를 직접 distill함
- 100,000 step 학습
- Distillation을 위한 training set을 $(X_0,\mathrm{ODE}[v_{sd}]) \ \ 32 \times 100,000 = 3,200,000$ pair를 생성
Reflow + Distillation
- Pre-trained SD로부터 initialized된 weight로 2-Rectified Flow $v_2$를 50,000 step 학습
- 얻은 $v_2$를 가지고 50,000 step을 이어서 distillation
- Distillation을 위한 $(X_0, \mathrm{ODE}[v_{sd}])$를 25-step Euler solver로 $32 \times 50,000 = 1,600,000$ pair 생성
- guidance scale $\alpha$는 1.5로 셋팅
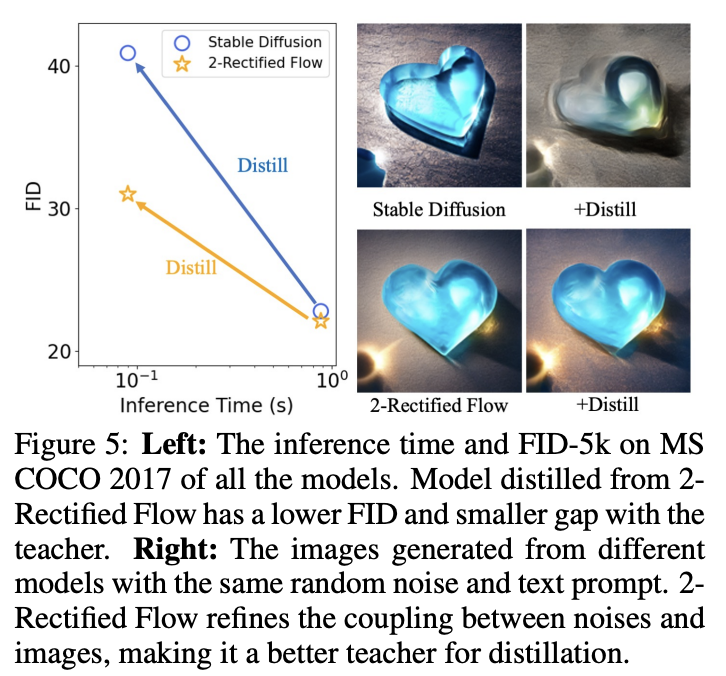
Observation and Analysis
Figure 5를 보면 SD와 SD + distill 사이의 FID 차이도 크고 생성된 이미지의 차이도 큼
SD로부터 direct distillation은 one-step student model에게는 어려운 learning problem임.
2-Rectified Flow는 noise 분포와 image 분포사이의 coupling을 refine하고 distillation할 때 student model을 위한 learning process를 쉽게 만듦
이는 다음 두가지 측면으로 추론됨
- 2-Rectified Flow+Distill과 2-Rectified Flow사이의 gap은 SD와 SD+Distill사이의 gap보다 작음
- 2-Rectified Flow+Distill로부터 생성된 이미지는 original generation과 많은 닮은 점들을 공유
이는 student가 모방하기 더 쉽다는 것을 보임
이는 2-Rectified Flow가 original SD보다 one-step student model을 distill하는데 더 좋은 teacher라는 것을 보임
Comparison on MS COCO
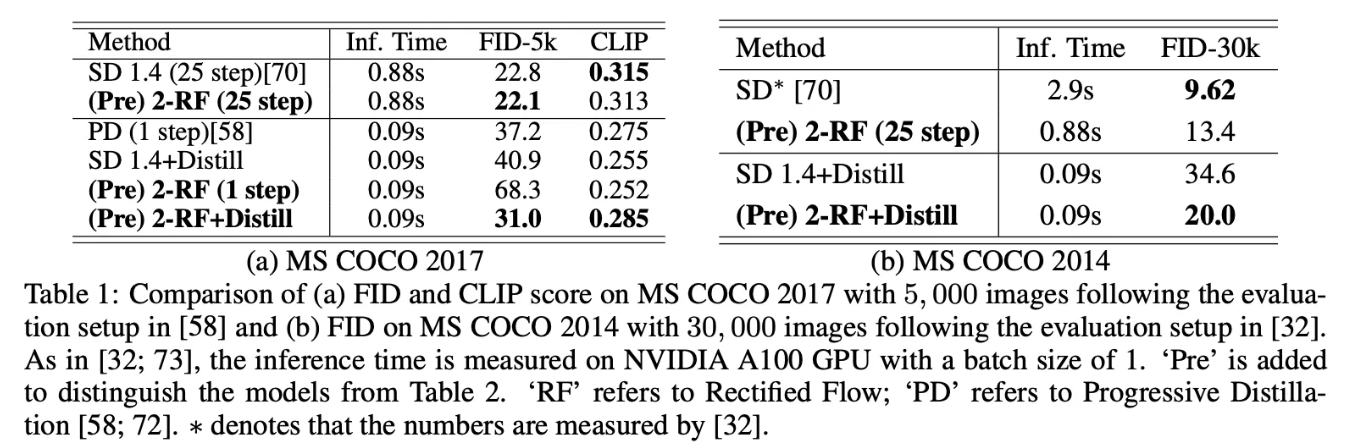
- (Pre) 2-Rectified Flow+Distill이 31.0의 FID score를 보임 → 기존의 one-step model인 Progressive Distillation로 distill된 SD를 능가 (one-step모델 중 best)
- SD가 (Pre)2-RF보다 성능이 좋음에도 불구하고 (Pre)2-RF+Distill이 SD1.4+Distill보다 성능이 좋음 → Reflow의 효과를 볼 수 있음
Straightening Effects of Reflow
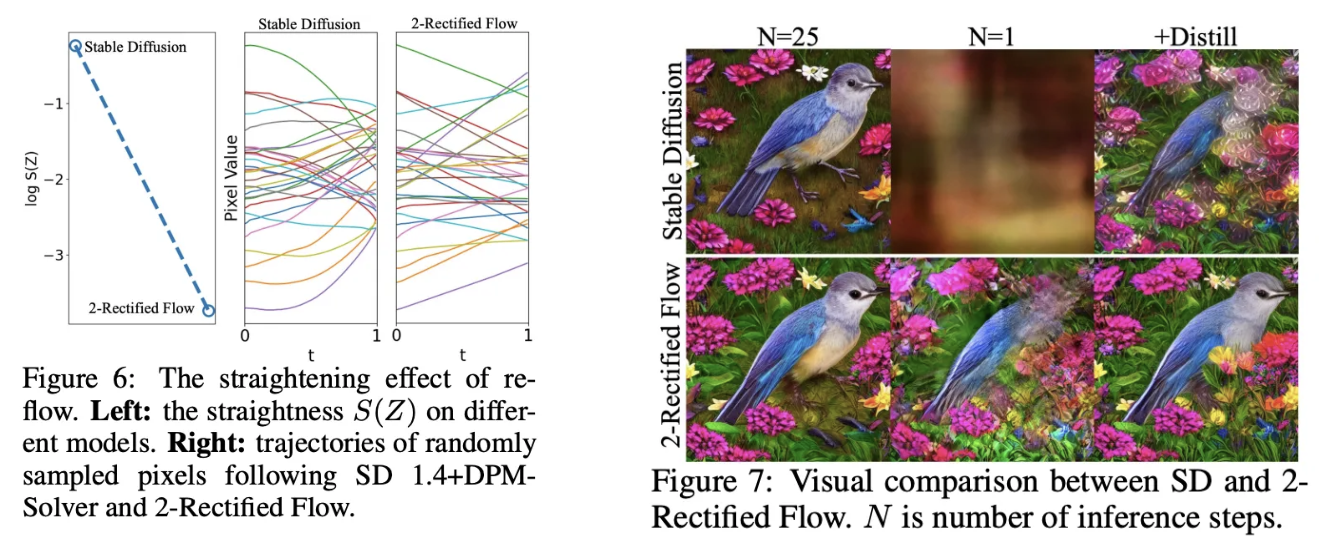
Figure 6을 보면, reflow가 $S(Z)$를 감소시킴 → reflow의 straightening effect 보여줌
SD의 픽셀들은 curved trajectory로 움직이지만 2-Rectified Flow에서는 더 straighter trajectory를 따름
Figure 7을 보면, SD는 curved trajectory여서 one-step에서는 noise를 생성하지만 2-Rectified Flow와 distillation의 결과는 그렇지 않음
4. InstaFlow : Scaling Up for Better One-Step Generation
SD1.4를 사용한 preliminary results는 one-step diffusion-based model을 distilling하는데 있어서 reflow procedure를 통합하는 것의 이점을 강조함
이를 통해 scaling up하면 더 좋아질 것 → training duration을 batch size를 키워서 늘림 → InstaFlow
InstaFlow는 0.09초로 섬세한 디테일을 가진 고퀄 이미지를 생성할 수 있는 첫번째 one-step SD model
InstaFlow-0.9B
- SD 1.5
- 25-step DPMSolver
- Guidance scale for SD는 5.0 → over-saturate발생
- Reflow랑 distillation을 위해서 1,600,000 pair의 데이터를 각각 생성
- Distillation에서 2-Rectified Flow에 대한 guidance scale $\alpha$는 1.5로 셋팅

InstaFlow-1.7B
- Stacked U-Net을 사용
- InstaFlow-0.9B에서 얻은 2-Rectified Flow를 사용해서 distillation 진행
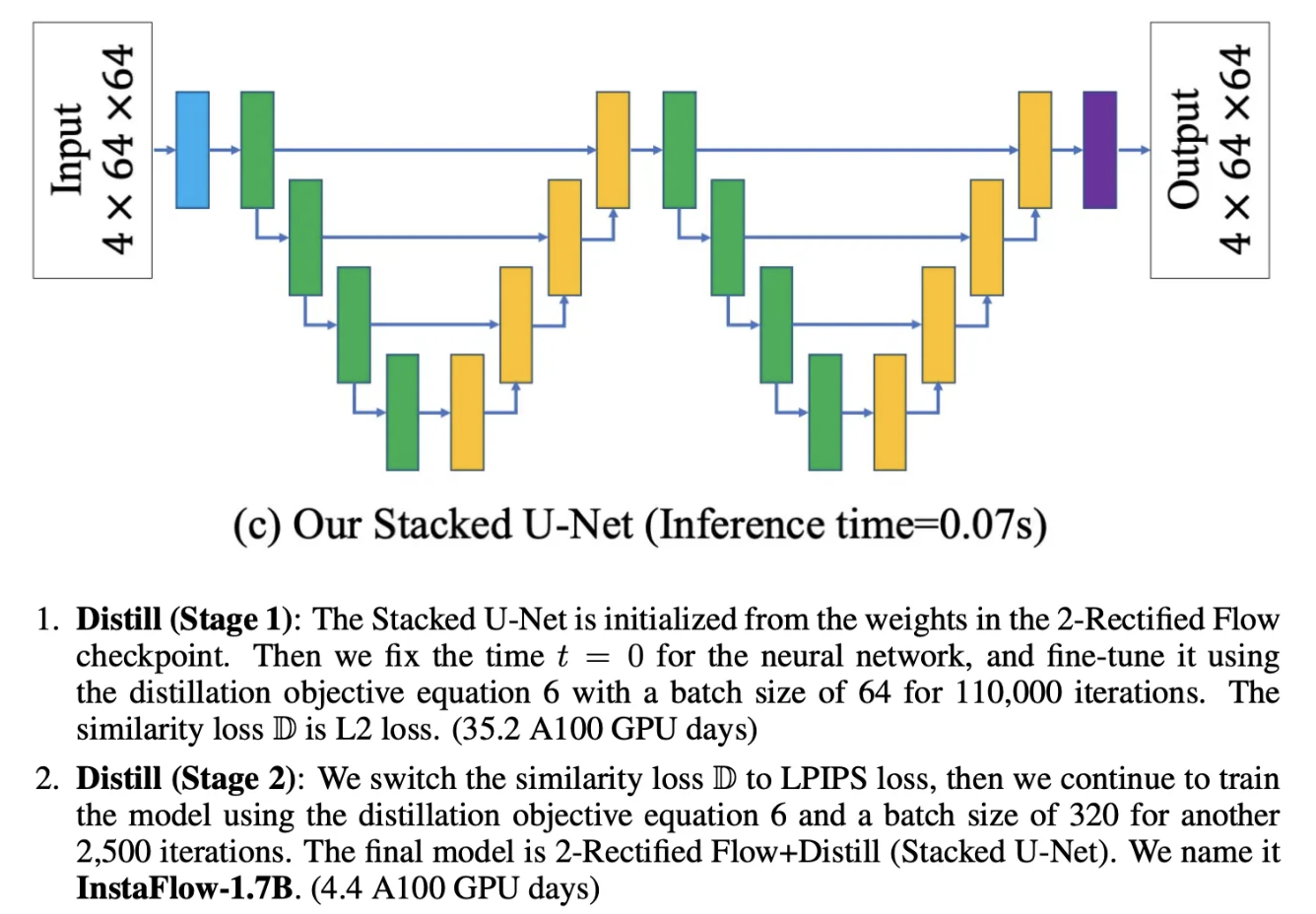
Discussion 1 (Experiment Observation)
- 2-Rectified Flow model은 fully convergence하지 않음 → 학습을 더 하면 좋아질 가능성 보임
- Reflow와 비교해서 distillation은 더 빠른 convergence를 보임
- LPIPS loss는 distilled one-step model의 visual quality를 강화하는 즉각적인 효과를 보임
Discussion 2 (One-step Stacked U-Net and Two-step PD)
One-step Stacked U-Net과 2-step PD가 비슷한 inference time을 가지지만 두 key difference를 보임
- 2-step PD 추가적으로 $t=0.5$에서 distillation loss를 최소화하는데, 이는 $t=0$에서의 one-step generation에서는 불필요함
- 연속적인 U-Net을 하나의 모델로 고려함으로써, 거대한 neural network에서 불필요한 component를 제거
Comparison with SOTA on MS COCO
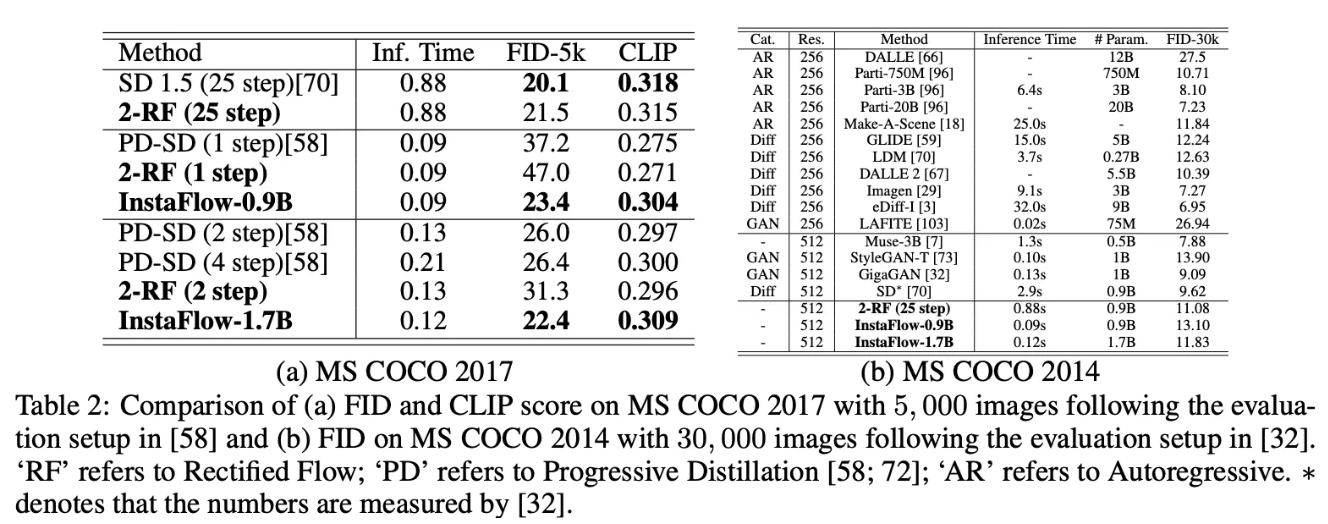
- InstaFlow-0.9B의 FID score는 이전의 SOTA인 Progressive Distillation SD보다 상당히 낮음(distillation cost는 비슷함)
- Reflow가 noise와 image사이의 coupling을 향상시키는 것을 돕는 것을 보임 → 2-Rectified Flow가 distill하기에 더 쉬운 teacher model임
- StyleGAN-T보다도 좋은 성능 보임
Few-step Generation with 2-Rectified Flow
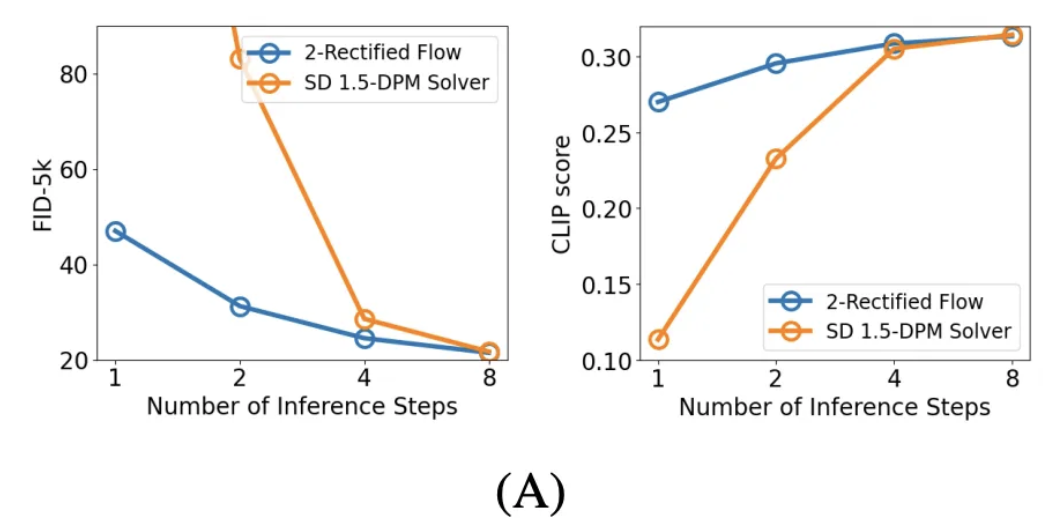
2-Rectified Flow와 SD 1.5-DPM Solver를 비교함 → 2-Rectified Flow가 적은 step에서 더 효과적임
Guidance Scale $\alpha$

SD에서의 guidance scale과 같은 경향을 보여줌
Fast Preview with One-Step InstaFlow

5. Limitation and Conclusions
Text prompt에서 복잡한 구성에서는 어려움을 겪음

InstaFlow는 continuous time diffusion model과 one-step generative model사이의 gap을 상당히 줄임
Additional Qualitative Results









