
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 3d generation
- 네이버 부스트캠프 ai tech 6기
- 코딩테스트
- score distillation
- controlnext
- Vit
- video generation
- diffusion model
- visiontransformer
- 프로그래머스
- segmentation map
- video editing
- transformer
- dreammotion
- BOJ
- diffusion
- 3d editing
- emerdiff
- Programmers
- VirtualTryON
- Python
- diffusion models
- 논문리뷰
- magdiff
- 코테
- DP
- image editing
- controllable video generation
- segmenation map generation
- masactrl
Archives
- Today
- Total
목록GaN (1)
평범한 필기장
 [평범한 학부생이 하는 논문 리뷰] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
[평범한 학부생이 하는 논문 리뷰] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
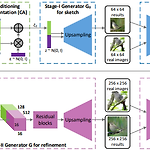
기존 Text to Image의 문제점 기존에 conditional GAN을 이용해서 Text to Image문제를 해결하려했지만 여러 문제점을 지녔다. text description의 의미를 rough하게 반영은 하지만 이미지의 detail이 떨어지고 생생한 object를 생성하지 못했다. 즉, 고화질의 사실적인 이미지를 생성하지 못했다. GAN에 upsampling layer를 더 쌓아서 해결하려했지만, instability를 보였고, nonsensical한 결과를 생성했다. 그래서 이러한 문제점들을 해결하려 했고, 그 결과로 StackGAN이라는 모델을 만들었다! Contribution StackGAN을 알아보기 전에 이 모델이 가지는 기여점에 대해 먼저 설명하겠다. Text로부터 photo-rea..
AI/GAN
2023. 4. 30. 22:54