
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Programmers
- 3d generation
- ddim inversion
- flow matching
- inversion
- image editing
- 코테
- flow models
- rectified flow
- 프로그래머스
- Python
- video generation
- memorization
- BOJ
- diffusion
- 네이버 부스트캠프 ai tech 6기
- diffusion models
- 논문리뷰
- Machine Unlearning
- rectified flow models
- Concept Erasure
- 3d editing
- rectified flow matching models
- video editing
- flow matching models
- image generation
- VirtualTryON
- unlearning
- visiontransformer
- diffusion model
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet) 본문
[평범한 학부생이 하는 논문 리뷰] Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet)
junseok-rh 2024. 3. 27. 00:31이번 논문은 최종 프로젝트에서 메인으로 쓰일 ControlNet이다.
프로젝트에 관한 포스팅은 여기에서 확인할 수 있다.
Why ControlNet?
본 논문에서 ControlNet을 왜 제시했을까? 일단 먼저 기존의 text-to-image generation diffusion모델을 생각해보자. Stable Diffusion을 통해 우리는 고퀄리티의 이미지를 텍스트를 통해 생성할 수 있었다. 하지만 본 논문에서는 이러한 text-to-image generation에는 두 가지 한계점이 존재한다고 말하고 있다.
- Text만으로는 이미지의 spatial composition을 제공하는 것에는 한계가 있다.
- 특정 condition에 대한 데이터셋이 작기 때문에 직접 finetuning하거나 continued training하면 overfitting이나 catastrophic forgentting을 야기한다.
그래서 본 논문은 trainable copy와 zero convolution을 이용한 ControlNet을 제시한다. 이 두 개의 방식을 통해 ControlNet은 large text-to-image Model(Stable diffusion)에 conditional control을 학습시킨다. 이 과정에서 이 거대한 모델의 능력을 보존하고 harmful noise를 추가하지 않는다고 한다.
이제 ControlNet에 대해 자세히 알아보자.
Method
ControlNet
이번 섹션에서는 ControlNet이 어떻게 구성되어있는지 어떤 방식으로 계산되는지를 알아 볼 것이다. 아래의 이미지를 먼저 살펴보자.

기존의 신경망은 왼쪽 이미지처럼 $x$가 들어와서 신경망 블록을 지나면 $y$라는 output이 나온다. 수식으로 나타내면 $y = \mathcal{F}(x;\theta)$이다. 하지만 ControlNet은 오른쪽 이미지처럼 기존 신경망 블록은 lock시킨다. 그리고 이 블록의 weight를 복사한 trainable copy를 따로 둔다. 또한 복사된 블록 앞뒤에 zero convolution을 둔다. 이를 수식으로 나타내면 $y = \mathcal{F}(x;\theta) + \mathcal{Z}(\mathcal{F}(x + \mathcal{Z}(c;\theta_{z1});\theta_c);\theta_{z2})$가 된다. 여기서 $\theta_c$는 앞에서 말한 trainable copy이다. 이 trainable copy는 condition $c$를 input으로 받는다. 이러한 방식으로 거대한 데이터로 학습된 weight는 lock을 시켜서 보존하고, trainable copy만 학습시킴으로써 다양한 condition에 robust한 모델 을 만들게 한다고 한다. 또한 여기서 $\mathcal{Z}$는 zero convolution으로 $1 \times 1$ 크기의 weight와 bias가 0인 convolutional layer이다. 이렇게 앞뒤로 zero convolution을 붙임으로써 학습 시작때는 controlnet의 output이 0이 나오게 된다. 이렇게 되면 gradient로 random noise를 제거하게 함으로써 backbone을 harmful noise로부터 보호 한다고 한다.
$$\mathcal{Z}(I;\{ W,B \})_{p,i}= B_i + \underset{j}{\overset{i}{\Sigma}}I_{p,i}W_{i,j}$$
로 zero convolution의 수식을 나타낸다고 하면 $W, B, I$에 대해 위 수식을 각각 미분한다고 하면 아래와 같아진다.

여기서 $W, B$의 gradient가 0이 아니게 된다. 이렇게 되면 아래의 수식처럼 $W$가 update가 된다.
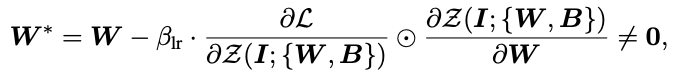
이렇게 $W$가 update되면 0이 아니게 되고 그렇게 되면 $W$의 합으로 표현되는 $I$에 대한 gradient도 0이 아니게 되고 결국 신경망이 학습되게 된다.
ControlNet for Text-to-Image Diffusion

본 논문에서는 ControlNet의 예시로 Stable Diffusion에 적용한 것을 보였다. 전체적인 구조는 위의 이미지와 같다. 여기서 주의할 점은 Stable Diffusion은 이미지를 autoencoder를 통해 encoding을 해서 나온 latent image로 diffusion을 진행한다. 그렇기에 ControlNet도 동일하게 condition을 encoding을 시켜야한다. 그래서 ControlNet에서 condition $c_i$를 encoder $\mathcal{E}(\cdot)$을 이용해 latent image $c_f$로 encoding을 시키는 과정을 거쳐야한다. 이 때, encoder $\mathcal{E}$는 ControlNet과 jointly하게 학습된다고 한다.
($\mathcal{E}$은 4개의 $4 \times 4$커널과 $2 \times 2$ stride를 가진 convolutional layer를 가진 구조)
Training
Stable Diffusion을 이용한 ControlNet의 Loss 함수는 다음과 같다.

$c_f$를 제외하고는 stable diffusion과 동일한 Loss 함수를 지닌다고 볼 수 있다.
ControlNet 학습 시, 특이한 점이 하나 있는데 바로 학습 동안에 prompt의 50%는 빈 문자열을 만든다는 것이었다. 이렇게 함으로써 모델이 conditioning image의 의미를 인지하는 능력을 향상시킨다고 한다.
또한, ControlNet은 서서히 condition을 control하는 것이 아닌 갑작스럽게 conditioning image를 따르게 된다고 한다. 이를 저자들은 "sudden convergence phenomenon"이라고 부른다.
Inference
기존의 Stable Diffusion은 Classifier-Free Guidance(CFG)를 사용했다. CFG를 수식으로 나타내면 $\epsilon_{prd} = \epsilon_{uc} + \beta_{cfg}(\epsilon_c - \epsilon_{uc})$이다. 이 때, 이를 ControlNet에 사용하게 되면 conditioning image를 더하게 되면 $\epsilon_{uc}$와 $\epsilon_c$ 둘 다에 혹은 $\epsilon_c$에만 더해진다. Prompt가 없는 경우 $\epsilon_{uc}$와 $\epsilon_c$에 동시에 더하는 것은 CFG를 아예 없애게 되고, $\epsilon_c$에만 사용하는 것은 CFG를 너무 강하게 만든다. 논문에서 제시한 해결핵은 CFG Resolution Weighting으로 $\epsilon_c$에 conditioning image를 더하고 $w_i$라는 weight를 곱해주는 방식이다. 이 때, $w_i$는 $64/h_i$이고, $h_i$는 i번째 block의 크기를 나타낸다.
(이 부분은 classifier free diffusion guidance를 읽고 다시 이해해봐야할 것 같다!)
Experiments
Zero Convolution에 대한 ablation study

이전 모델들과의 비교

Sudden Convergence Phenomenon

Limitation
Input 이미지가 애매하면 임의로 생성한다.




