
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- unlearning
- inversion
- rectified flow
- visiontransformer
- ddim inversion
- memorization
- diffusion models
- Programmers
- 3d editing
- rectified flow matching models
- flow models
- flow matching
- 코테
- rectified flow models
- video editing
- image generation
- video generation
- diffusion model
- diffusion
- BOJ
- image editing
- 프로그래머스
- 논문리뷰
- Machine Unlearning
- 네이버 부스트캠프 ai tech 6기
- Concept Erasure
- Python
- VirtualTryON
- flow matching models
- 3d generation
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Denoising Diffusion Implicit Models (DDIM) 본문
[평범한 학부생이 하는 논문 리뷰] Denoising Diffusion Implicit Models (DDIM)
junseok-rh 2024. 4. 3. 02:05이번에 리뷰할 논문은 DDIM 이다. 붓캠 기간동안 진행한 diffusion 스터디의 마지막 논문이였는데, 이 논문을 읽는 기간이 최종 프로젝트때문에 한창 정신이 없을 기간이어서 제대로 집중해서 읽지 못했었다. 그래서 최종 프로젝트를 제출하고 다시 읽고 리뷰를 남겨야지라고 미루다가 이제야 리뷰를 하게 됐다.
https://arxiv.org/pdf/2010.02502.pdf
0. Abstract
DDPM은 높은 수준의 이미지 생성할 수 있다. 그렇지만 이미지를 생성하려면 많은 스텝을 거쳐야한다. 그래서 DDPM과 동일한 training 절차를 거치지만 더 효율적인 DDIM을 제안한다. 본 논문은 DDPM을 non-Markovian diffusion 프로세스를 통해 일반화한다. 이러한 non-Markovian 프로세스는 deterministic한 generative 프로세스에 대응된다. 이를 통해 높은 퀄리티의 이미지를 더 효율적으로 생성할 수 있다.
1. Introduction
DDPM과 NCSN을 통해 adversarial training없이 GAN과 비교할만한 수준의 이미지 생성이 가능했다. GAN은 학습이 어렵고 불안정적이고 분포를 다 커버하지 못한다는 단점이 있었지만 이 두 모델은 그러한 단점을 가지지 않는다. 이 두 모델은 Markov chain 혹은 reverse process를 통해 white noise로 부터 이미지를 생성한다.
이러한 모델들의 치명적인 단점은 많은 iteration을 통해 이미지를 생성한다는 것이었다. DDPM에서 보면 generative process는 diffusion process의 reverse를 근사화해서 얻어지는데, 이때 수천 번의 스텝을 거쳐야 이미지를 생성할 수 있다. GAN과 비교하면 엄청난 속도 차이를 가진다.
이러한 속도 차이를 줄이기 위해 본 논문에서 DDIM을 제안한다. DDIM은 DDPM과 동일한 training objective를 통해 학습되는 implicit probability models라는 점에서 DDPM과 연관이 있다.
(Implicit Probability Model은 데이터의 분포를 직접 구하지 않고 간접적으로 학습해서 데이터를 생성하는? 모델이라고 간단히 이해하면 될듯 하다..)
2. Background
DDPM 논문 리뷰 포스팅은 아래에서 확인할 수 있다.
https://juniboy97.tistory.com/46
[평범한 학부생이 하는 논문 리뷰] Denoising Diffusion Probabilistic Models (DDPM)
이번에 리뷰할 논문은 그 유명한! DDPM! Diffusion의 기초 논문들은 확실하게 이해하고 넘어가는 것이 좋다는 멘토님의 조언에 따라 이번 ddpm도 시간은 오래 걸리겠지만 최대한 꼼꼼하게 읽어서 자
juniboy97.tistory.com
3. Variational Inference for Non-Markovian Forward Process
생성 모델은 inference process의 reverse를 근사하는 것이기 때문에, 반복 횟수를 줄이기 위해 inference process를 다시 생각할 필요가 있다. 본 논문에서 말하는 key observation은 $L_{\gamma}$의 형태의 DDPM objective는 marginal인 $q(x_t|x_0)$에만 의존하고 joint인 $q(x_{1:T}|x_0)$에는 직접적으로 의존하지 않는다는 것이다. 동일한 marginals에 대해 많은 inference distribution (joints)가 존재하기 때문에, 본 논문에서는 non-Markovian인 대안적인 inference process를 탐구했다. 그리고 이는 새로운 generative process를 이끈다고 한다. (아래의 오른쪽 이미지)

이 non-Markovian inference process는 DDPM과 동일한 surrogate objective function을 이끈다. 증명은 뒤에 나온다.
3.1 Non-Markovian Forward Process
DDPM과 DDIM은 아래과 같은 동일한 marginal을 가진다.
$$q_{\sigma}(x_T|x_0) = \mathcal{N}(\sqrt{\alpha_T}x_0,(1-\alpha_T)\mathbf{I})$$
DDIM에서 joint distribution은 아래와 같이 정의된다.

반면에 DDPM에서 joint distribution은 아래와 같이 정의된다.
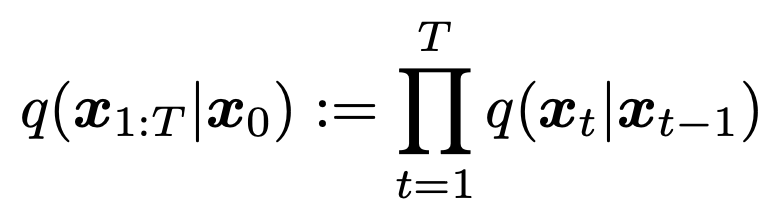
아래의 식처럼 mean function이 나오는 이유로는 모든 t에 대해 $q_{\sigma}(x_t|x_0) = \mathcal{N}(\sqrt{\alpha_T}x_0,(1-\alpha_t)\mathbf{I})$를 보장하기 위해서 저렇게 둔다고 한다. (논문 Appendix B에 Lemma 1에 나와있음)

DDPM에서는 $x_t$는 그 직전 timestep인 $x_{t-1}$에만 의존하는 Markovian이었지만 DDIM에서는 $x_t$는 $x_{t-1}$와 $x_0$에 의존해 non-Markovian이기에 6번 식처럼 정의가 된다. $\sigma$의 크기는 forward process가 얼마나 stochastic한지를 컨트롤한다. $\sigma \rightarrow 0$일 때, $x_0$와 $x_t$가 관찰됐을 때, $x_{t-1}$가 고정된다는 극단적인 case에 도달한다.
3.2 Generative Process and Unifed Variational Inference Objective
Noisy observation $x_t$가 주어지면, 이를 통해 $x_0$의 prediction을 구하고 이를 가지고 정의한 reverse conditional distribution $q_{\sigma}(x_{t-1}|x_t,x_0)$를 통해 sample $x_{t-1}$을 구한다.
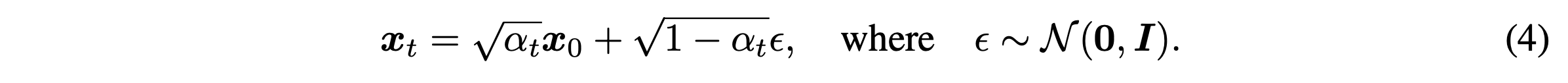
$x_0 \sim q(x_0)$과 $\epsilon_t \sim \mathcal{N}(0,I)$에 대해 식 (4)를 통해 $x_t$를 구할 수 있다. Model $\epsilon_{\theta}^{(t)}(x_t)$은 $x_t$를 통해 $\epsilon_t$를 예측한다. 이를 이용해 식 (4)를 다시 써서 나타내보면 아래와 같이 $x_0$에 대한 prediction을 얻을 수 있다.
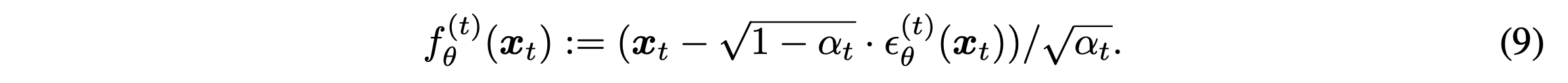
Fixed prior $p_{\theta}(x_t) = \mathcal{N}(0,I)$를 가지고 아래과 같이 generative process를 정의할 수 있다.

t=1인 경우에 $\sigma^2_1I$인 노이즈를 추가해주는데 논문에서는 이를 통해 generative process가 전체 공간에서 support되는 것을 보장해준다고 설명한다.
아래의 variational inference objective를 통해 $\theta$를 최적화한다.
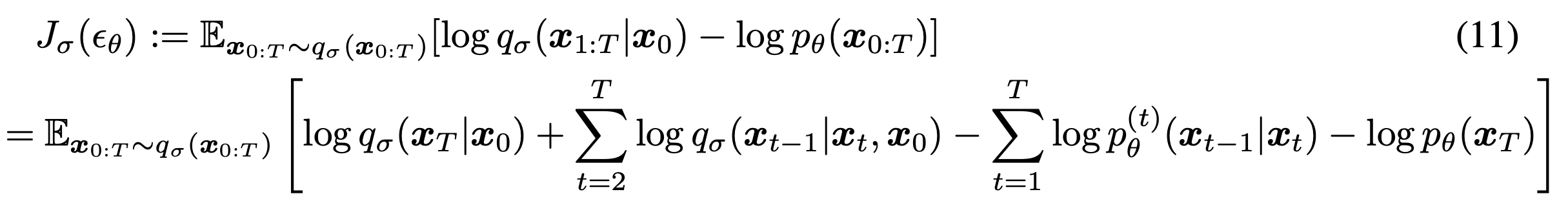
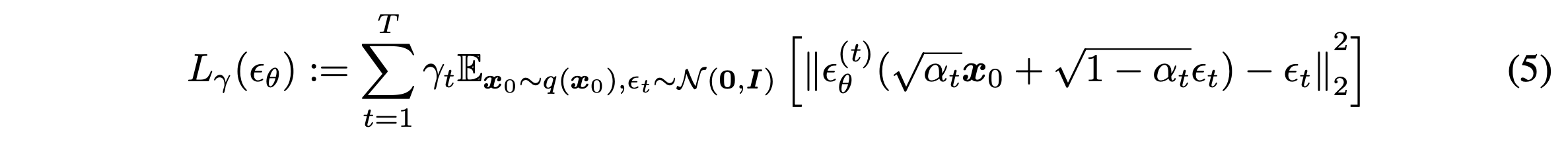
위 정의를 통해 $\sigma$에 따라 objective가 다르기에 다른 모델을 학습 시켜야하는 것으로 보인다. 하지만 아래의 Theorem 1.을 통해 특정 $\gamma$에 대해 $J_\sigma$와 $L_\gamma$가 동일하다는 것을 보인다.

Model $\epsilon_\theta^{(t)}$의 parameter $\theta$가 다른 $t$에 대해 공유되지 않는다면 $\epsilon_\theta$에 대한 optimal solution은 $\gamma$에 depend하지 않는다. 이 특성은 두가지를 내포한다. (1) DDPM에서 surrogate objective로 $L_1$의 사용을 정당화 한다. (2)$J_\sigma$의 optimal solution은 $L_1$의 것과 동일하다. 그렇기에 model $\epsilon_t$에서 $t$에 따라 paremeter들이 공유되지 않으면, $L_1$ objective가 $J_\sigma$의 surrogate objective로 사용될 수 있다.
4. Sampling from Generalized Generative Processes
$L_1$을 objective로 할 때, 우리는 Markovian inference preocess에 대한 generative process 뿐만 아니라 $\sigma$로 parameterize된 non-Markovian forward process에 대한 generative process를 학습시키게 된다. 즉 $\sigma$를 바꿈으로써 우리의 필요에 더 맞는 samples subject를 더 잘 생산하는 generative process를 찾는데 집중한다.
4.1 Denoising Diffusion Implicit Models
식 (10)을 통해, $x_t$를 통해 생성된 $x_{t-1}$를 아래와 같이 쓸 수 있다.

동일한 $\epsilon_\theta$를 쓰는 반면에, $\sigma$값을 다르게 하면 다른 generative process를 초래한다. 그러므로 모델을 재학습 시키는 것은 필요하지 않는다. 모든 t에 대해, $\sigma_t = \sqrt{(1-\alpha_{t-1})/(1-\alpha_t)}\sqrt{1-\alpha_t/\alpha_{t-1}}$로 두면 forward process는 Markovian이 되고, generative process는 DDPM이 된다.
$\sigma_t = 0$이면, $\sigma_t\epsilon_t = 0$이므로 forward process가 deterministic해진다. (t=1 제외) 결국 이 모델은 implicit probabilistic model이 된다. 그래서 $x_T$에서 $x_0$를 생성하는 과정이 fixe된다. 이 모델을 논문에서 DDIM이라고 부르는데, DDPM의 objective로 학습된 implicit model이라서 그렇다고 한다. (forward process가 diffusion이 아님에도..)
4.2 Accelerated Generation Process
기존에는 generative process는 reverse process에 대한 근사로 고려됐다. 그렇기에 forward process가 T step이면 generative process또한 T step으로 강요됐다. 하지만 $q_\sigma(x_t|x_0)$가 고정됨에 따라 $L_1$이 특정한 forward procedure에 의존하지 않기 때문에 T보다 작은 길이의 forward process들을 고려할 수 있고, 이는 다른 모델을 학습시키는 것 없이 대응되는 generative process를 가속화한다.
예를 들면, forward process가 모든 latent variable $x_{1:T}$에 대해 정의되지 않고, subset $\{ x_{\tau_1}, \cdots,x_{\tau_s} \}$ 에 대해 정의 됐다고 하자. 저자들은 subset에 대한 sequential forward process를 $q(x_{\tau_i}|x_0) = \mathcal{N}(\sqrt{\alpha_{\tau_i}}x_0,(1-\alpha_{\tau_i})\mathbf{I})$로 정의했고 이는 "marginals"와 일치한다. Generative Process는 reversed($\tau$)에 따라 latent variables를 샘플링하고 논문에서 이를 (sampling)trajectory라고 부른다. 이 trajectory가 T보다 작으면 빠르게 샘플링이 가능하다.

본 논문은 식 (12)에서 update를 약간 변화만으로 새롭고 빠른 generative process들을 얻을 수 있다는 것을 보였다. 본 논문 저자들은 임의의 step 수로 모델을 학습시킬 수 있고 그 중 몇 step만으로 generative process에서 sample을 뽑는다.
4.3 Relevance to Neural ODE
식 (12)를 다음과 같이 다시 쓸 수 있다.
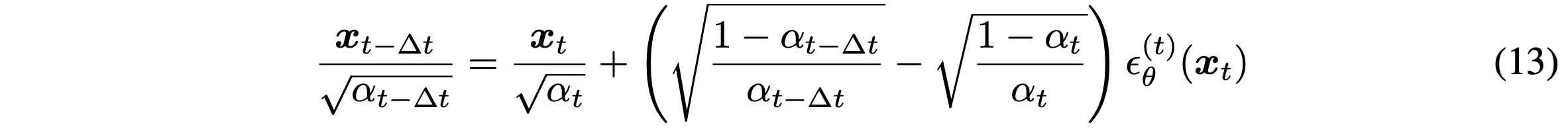
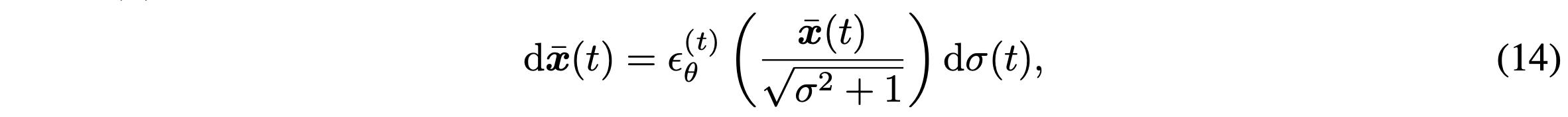
이 때 initial condition은 $x(T) \sim \mathcal{N}(0,\sigma(T))$이다.
충분한 discretization steps를 통해, generation process를 reverse할 수 있다. (t = 0 to T) 즉 $x_0$를 $x_T$로 encode가 가능하다!
5. Experiments
실험을 통해 다음을 보였다.
- DDIM이 DDPM을 능가했다는 것을 더 적은 iterations에서의 image generation 관점에서 보였다.
- DDPM과 다르게, initial latent variables $x_T$가 고정됐을 때 generation trajectory와 관계없이 고수준의 image feature를 얻었다. ( latent space에서 interpolation이 가능)
- DDIM은 sample을 encode할 수 있다. 이를 통해 latent code로 부터 reconstruct가능하다.
모든 실험은 동일한 trained model을 사용했고 training procedure에서는 변화없이 오로지 모델로부터 어떻게 샘플을 생성할 것인지만 바꿨다고 한다.
5.1 Sample Quality and Efficiency

위 결과를 보면, DDIM($\eta = 0$)은 $dim(\tau)$가 작을 때 좋은 성능을 보였고 DDPM은 안 좋은 성능을 보였다.

또한 DDIM은 DDPM과 비슷한 성능을 내는데 훨씬 적은 시간이 드는 것을 볼 수 있다.
5.2 Sample Consistency in DDIMs

DDIM에서 generative process는 deterministic하고 $x_0$는 initial state인 $x_T$에만 의존한다. 위 이미지에서 보면 다른 generative trajectory (다른 $\tau$)에 대해 같은 initial state $x_T$에서 이미지를 생성하면, high level feature가 동일한 이미지가 생성된 것을 볼 수 있다. 20step을 통해 생성된 이미지는 1000 step을 통해 생성된 이미지와 거의 유사하다. 이러한 사실을 통해 $x_T$는 이미지의 informative latent encoding이라고 할 수 있다.
5.3 Interpolation in Deterministic Generative Processes

위 결과를 보면 DDPM과 다르게 DDIM은 interpolation이 가능한 것을 볼 수 있다. DDPM은 stochastic하기 때문에 $x_T$를 통해 생성된 이미지가 다양하기 때문에 불가능하지만 DDIM은 deterministic하기 때문에 latent variable을 통해 interpolation이 가능하고 한다.
5.4 Reconstruction from Latent Space

DDIM은 $x_0$를 $x_T$로 encoding하기 때문에 $x_T$를 통해 $x_0$로 reconstruction하는 것도 가능하다고 한다. 위에 이에 대한 에러를 나타냈는데 step이 커질수록 이에 대한 에러가 낮은 것을 볼 수 있다. 이러한 reconstruction은 stochastic한 DDPM에서는 불가능하다.
이번에는 DDIM을 리뷰해봤는데, ode, sde가 나오는 부분은 여전히 이해를 못했다.. 수학이 여전히 너무 어렵다는 생각이 든다. 기회가 된다면 통계뿐만 아니라 수학 공부도 깊게 해봐야겠다



