
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- memorization
- Vit
- diffusion models
- Programmers
- 3d generation
- DP
- 코딩테스트
- diffusion
- inversion
- flow matching
- 네이버 부스트캠프 ai tech 6기
- image editing
- VirtualTryON
- 프로그래머스
- video generation
- transformer
- video editing
- Python
- segmentation map
- noise optimization
- 코테
- 논문리뷰
- masactrl
- BOJ
- segmenation map generation
- rectified flow
- diffusion model
- 3d editing
- visiontransformer
- flipd
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral) 본문
[평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral)
junseok-rh 2024. 6. 16. 00:47https://arxiv.org/abs/2303.11989
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
We present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outp
arxiv.org
요약
다루는 task : 2D Text-to-Image model을 통해 3D mesh 생성
Input : Text
Output : textured 3D mesh
대충 이런 모델이라고 요약할 수 있을 것 같다.
Introduction
기존 3D 생성에서의 한계점은 3D training data가 부족하다는 것이었다. 하지만 Dreamfusion, Magic3d와 같은 method들은 이미지 도메인에서의 반복적인 최적화 문제로 formulate함으로써 2D Text-to-Image model을 통한 3D 생성을 했다. 하지만 이러한 방식들은 room-scale 3D 구조와 texture를 생성하는 것으로 쉽게 확장할 수 없다. 거대한 크기의 장면을 생성하는 것의 challenge는 output이 outward-facing viewpoints에 따라 dense하고 일관적이라는 것과 이러한 view들이 필요로하는 structure 모두를 포함한다는 것을 보장하는 것이다.

본 논문에서는 이러한 shortcoming을 해결하기 위해, 기존의 2D T2I model로부터 scene-scale 3D mesh를 추출하는 방식을 제안한다. 본 논문의 방식은 inpainting과 monocular depth estimation을 통해 scene을 반복적으로 생성한다. Text로부터 이미지를 생성함으로써 초기 mesh를 제공하고 depth estimation model을 통해 이를 3D로 backproject한다. 그 후, 반복적으로 새로운 viewpoint로 부터 mesh를 반복적으로 렌더링한다. Inpainting을 통해 렌더링된 이미지에서의 구멍들을 채우고 생성된 content를 mesh로 융합한다.
본 논문의 방식은 두 가지 중요한 디자인 고려사항이 있다.
- Viewpoint를 어떻게 선택할지
- 생성된 scene content와 존재하는 mesh를 어떻게 merge할지
1은 많은 양의 scene content를 커버하는 predefined trajectory들로부터 viewpoint를 선택하고 남는 구멍을 메우는 viewpoint들을 adaptive하게 선택하는 것으로 해결한다. 2는 두 개의 depth maps를 부드러운 전환을 생성하기 위해 align시키고 왜곡된 texture를 포함하는 mesh의 부분을 제거하는 것으로 해결한다. 이를 통해 설득력있는 texture와 일관성있는 geometry를 가진 거대한 scene-scale 3D mesh들을 이끈다.
본 논문의 contribution은 다음과 같다.
- Text input으로부터 설득력있는 texture와 geometry를 가진 room-scale indoor scene들의 3D mesh를 생성
- 2D T2I 모델과 monocular depth estimation을 활용해 frame을 3D로 끌어올리는 방식
- 처음에는 room layout과 furniture를 생성하고 그 다음엔 남는 구멍을 메우는 최적의 위치로부터의 camera pose들을 샘플링하는 two-stage tailored viewpoint selection
2. Related Works
- Text-based Generation
- Text-to-3D
- 3D-Consistent View Synthesis from a Single Image
3. Method

본 논문의 method는 text input으로부터 textured 3D mesh를 생성한다. 과정을 간략하게 요약하면 다음과 같다.
- Viewpoint를 선택한다.
- 그 viewpoint에 대한 장면을 생성한다.
- Depth alignment를 이용해 기존 geometry에 장면을 align한다.
- Mesh에 merge하기 위해 새로운 content를 triangulate하고 filter한다.
본 논문 방식의 core idea는 two-stage tailored viewpoint selection이라고 한다.
3.1 Iterative 3D Scene Generation
Scene은 mesh $\mathcal{M} = (\mathcal{V}, \mathcal{C}, \mathcal{S})$로 표현된다. 여기서 $\mathcal{V} \in \mathbb{R}^{N \times 3}$는 vertices(꼭지점 좌표), $\mathcal{C} \in \mathbb{R}^{N \times 3}$는 vertex color, $\mathcal{S} \in \mathbb{N}^{M \times 3}_0$는 face set이다. Input은 text prompt $\{ P_t \}^T_{t=1}$와 그에 대응되는 selected poses $\{ E_t \}^T_{t=1} \in \mathbb{R}^{3 \times 4}$이다. Render-refine-repeat 패턴을 따라 반복적으로 scene을 만든다. 전체적인 과정은 아래의 이미지와 같다.
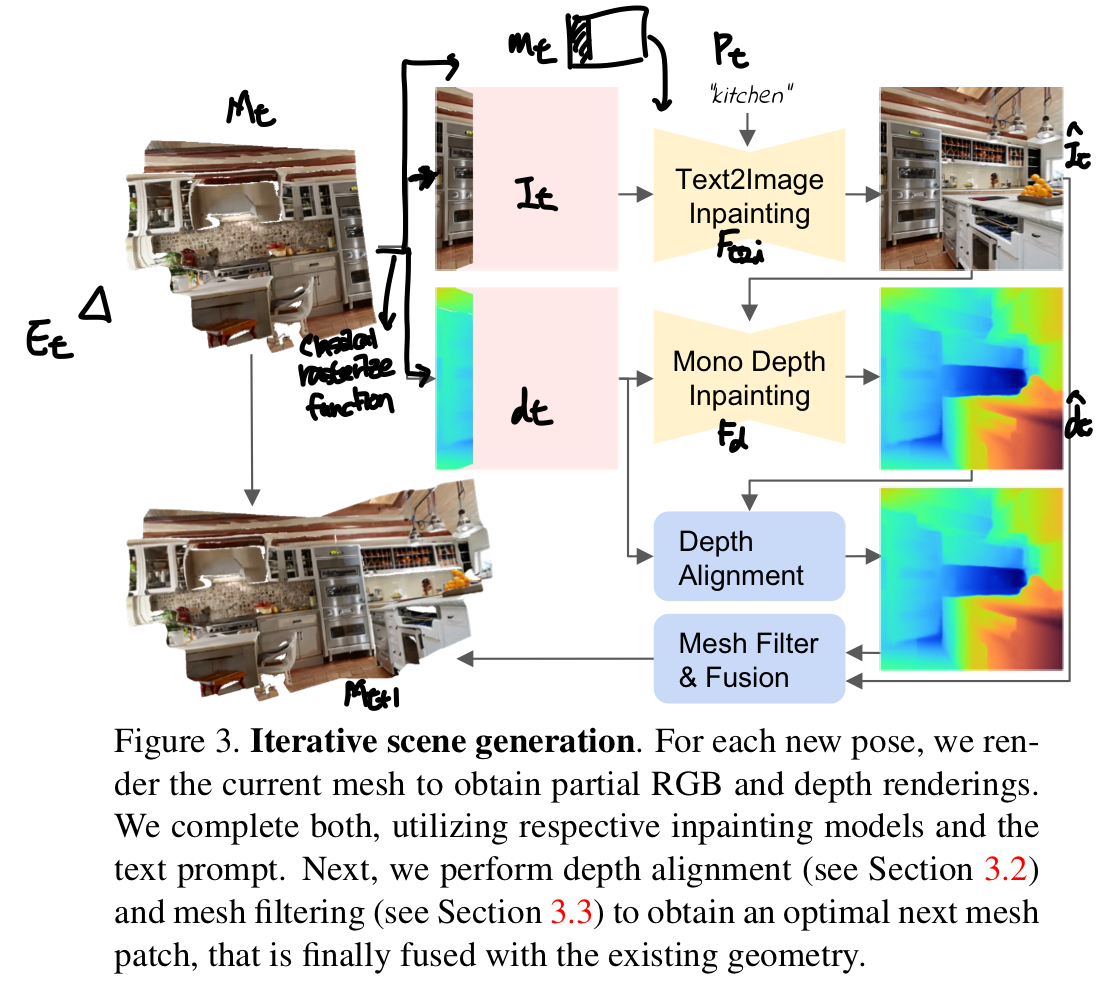
먼저 $t$번째 스텝에서 classical rasterization function $r$을 통해 새로운 view point $E_t$에 대해서 current scene을 렌더링한다.
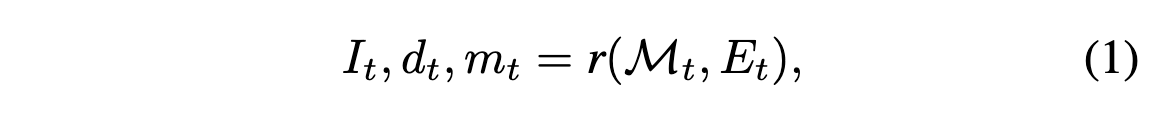
여기서 $m_t$는 image-space mask로 관찰된 cotent가 없는 pixel을 마킹한다. 위 이미지에서는 $m_t$의 흰부분을 마킹한다. 그 다음으로는 fixed text-to-image model $\mathcal{F}_{t2i}$을 통해 text prompt에 따라 관찰되지 않은 픽셀을 인페인팅한다.
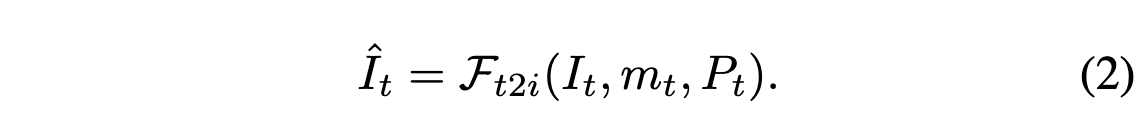
그 후, depth alignment에서 monocular depth estimator $\mathcal{F}_d$를 통해 관찰되지 않은 depth를 인페인팅한다.
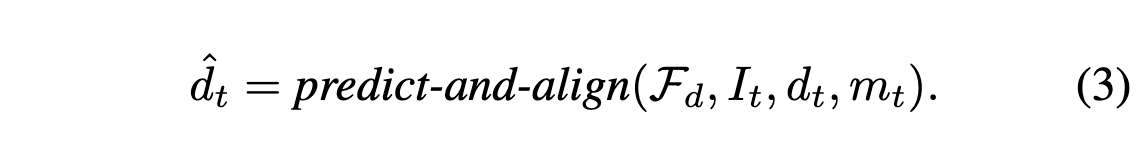
여기서 그림상 $I_t$대신 $\hat{I}_t$가 맞는 듯...??
마지막으로 본 논문의 fusion scheme을 통해 새로운 content $\{ \hat{I}_t, \hat{d}_t, m_t \}$와 기존의 mesh를 결합한다.
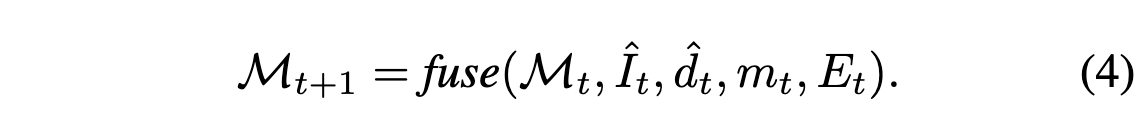
3.2 Depth Alignment Step
2D image $I$를 3D로 만들기위해, 본 논문에서는 per-pixel depth를 예측한다. Old와 new content를 정확하게 결합하기위해, 이미지와 depth를 둘 다 각각에 align시킬 필요가 있다. 즉 비슷한 구역은 비슷한 depth에 위치되어야 한다. 그러나 depth는 후의 viewpoints 사이에 scale에 대해 일치하지 않기 때문에 예측된 depth를 backprojection에 바로 쓰는 것은 3D geometry에서 hard cut이나 불연속성을 야기한다.
이를 위해 본 논문에서는 two-stage depth alignment를 수행한다.
1) SOTA depth inpainting network(Irondepth)를 이용해 이미지의 아는 부분의 ground-truth depth $d$를 input으로 넣고 예측값을 얻는다. 논문에서는 $\hat{d}_p = \mathcal{F}_d(I,d)$라 표기했지만 $\hat{d}_p = \mathcal{F}_d(\hat{I},d)$가 맞는 수식인듯 하다. 2) 아래의 수식으로 예측된 것과 렌더링된 것 사이의 차이를 align하는 것으로 scale과 shift 파라미터 $\gamma,\beta \in \mathbb{R}$를 최적화 함으로써 결과를 향상시킨다.
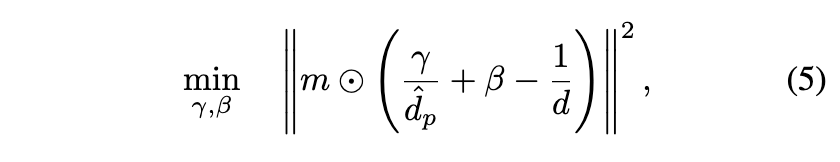
이를 통해 align된 depth $\hat{d} = (\frac{\gamma}{\hat{d}_p} + \beta)^{-1}$를 얻고 rendered depth와 predicted depth사이의 이미지 edge에 $5 \times 5$ Gaussian Blur kernel을 적용해서 smoothing 시킨다.
Importance of Depth Smoothing in Alignment
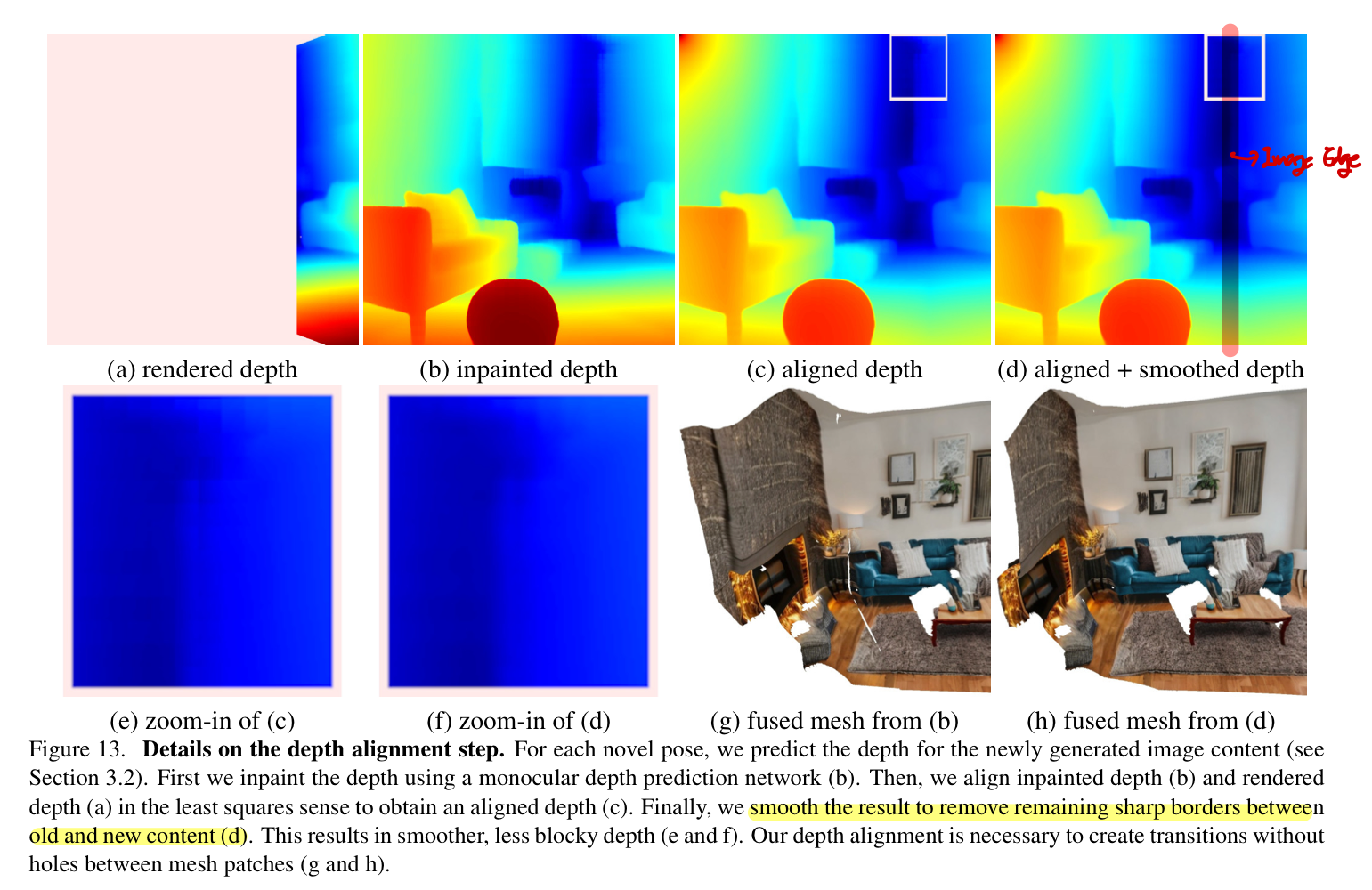
(c)가 two-stage depth alignment에서 1단계를 적용한 결과를 보여주고 (d)는 2단계를 적용한 결과를 보여준다.
3.3 Mesh Fusion Step
각 스텝마다 scene에 새로운 내용 $\{ \hat{I}_t, \hat{d}_t, m_t \}$을 추가하게 되는데, 이를 위해 아래의 수식을 통해 image-space pixel들을 world-space point cloud로 backproject해야한다. ($K \in \mathbb{R}^{3 \times 3}$는 camera intrinsic, $W,H$는 이미지 높이와 너비)
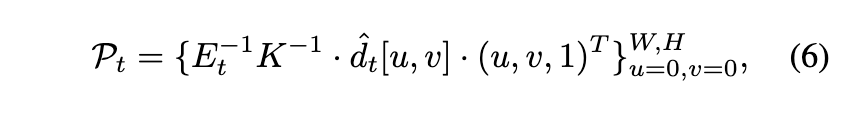
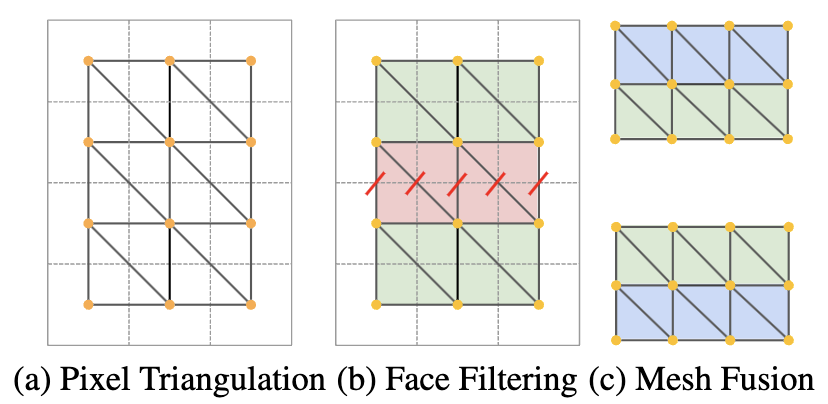
위 이미지에서 (a)와 같이 이웃한 4개의 점으로 triangulation을 진행해 2개의 면을 만든다. 추정된 depth가 noisy하기 때문에, 이 triangulation을 그대로 사용하게 되면 stretched out 3D geometry를 야기한다고 한다. 이 문제를 완화하기 위해 본 논문에서는 두 개의 filter를 이용한다고 한다.
1) edge length를 이용해 면을 filtering하는 것이다. 면에 해당하는 변의 유클리디안 길이가 threshold $\delta_{edge}$보다 크면 그 면을 제거한다.
2) 면의 법선 벡터와 viewing direction사이의 각을 토대로 면을 filtering한다.
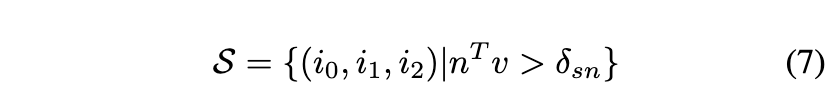
여기서 $n$는 normalized face normal을 나타내는 벡터, $v$는 normalized view direction을 나타내는 벡터이다. 이 두 벡터의 내적이 특정 threshold $\delta_{sn}$보다 큰 면만 취하겠다는 의미이다. 이 때 normalize된 두 벡터의 내적은 두 벡터 사이의 각의 cosine값을 나타내기에 이 값이 너무 작으면 면의 법선 벡터와 view direction의 각이 커져 view direction과 면이 평행에 가까워진다. 이러면 면을 상대적으로 크게 보는? 경향이 띄게 된다. 논문에서는 이렇게 filtering함으로써 이미지에서 상대적으로 적은 수의 픽셀들로부터 mesh의 큰 지역에 대한 texture를 생성하는 것을 피한다고 설명한다.
(c)에서와 같이 filtering을 진행한 후에 남은 면들과 기존에 존재했던 geometry를 융합한다. 간단히 설명하면 이전 단계에서 생성된 3D mesh에 새로 생긴 면들을 붙이는? 느낌으로 이해하면 편할 것 같다. $m_t$의 edge에 triangulation scheme을 하는데 이 때 상응하는 면을 생성하기 위해 vertex의 위치는 $\mathcal{M}_t$를 사용한다고 한다.
3.4 Two-Stage Viewpoint Selection
본 논문의 approach에서 text prompt와 camera pose의 선택은 매우 중요한 부분이다. 아무렇게나 pose를 선택하게 되면 안좋은 결과나 stretch나 hole artifacts를 포함한 결과를 내놓는다고 한다. 이를 위해 본 논문에서는 two-stage viewpoint selection 전략을 제안한다. 이는 최적의 위치로부터 다음 camera pose를 샘플링하고 그 후에 빈 지역을 refine한다.
Generation Stage
이 단계에서 general layout과 furniture를 포함한 장면의 메인 부분을 생성한다. 방 전체를 보는 다른 방향으로 된 predefined trajectory를 렌더링한다. Trajectory의 첫 시작은 관측되지 않은 부분을 가진 viewpoint로 하는 것이 가장 좋다고 한다. 이는 다음 덩어리의 outline을 생성하면서도 장면의 나머지 부분과 연결된다. Trajectory의 끝까지 이동하고 회전시키면서 3D 구조를 완성한다.
또한 본 논문에서는 각 pose에 대해 최적의 관측 거리를 보장한다. Camera 위치 $T_0 \in \mathbb{R}^3$를 look-at- direction $L \in \mathbb{R}^3$에 따라 $T_{i+1} = T_i - 0.3L$로 변환한다.(이렇게 함으로써 거리를 멀리 한다.) 이 과정은 mean render depth가 0.1보다 커지면 멈추거나 10번 이상 반복하면 이 camera를 폐기한다. 이 과정을 통해 geometry에 너무 가까운 view를 피한다.

위 이미지에서 초록색 pose는 빈 바닥을 보도록 하기 위해 가능한 뒤로 이동했다.
원점을 중심으로 원형의 다음 덩어리를 생성하는 trajectory를 선택함으로써 위 원칙에 따라 닫힌 방 layout을 생성한다. 원하지 않은 위치에 furniture가 생성되지 않도록 text prompt engineering을 한다고 한다. 예를 들면 천장이나 바닥을 보는 pose들에 대해서는 "floor"나 "ceiling"만 포함하는 text prompt를 선택한다.
Importance of Predefined Trajectories
각 trajectory들은 start pose와 end pose로 구성되고 이 사이를 linear interpolate한다. 가장 unobserved region들을 많이 포함한 viewpoint로부터 시작할 때 가장 좋은 결과를 냈다고 한다.

1. 일단 unobserved content를 가장 많이 보는 start pose를 선택하고 이로부터 다음 장면의 outline을 생성한다.(b)
2. Trajectory의 마지막까지 새로운 pose를 샘플링해서 그 장면을 변환하고 돌려서 3D 구조를 refine한다.(c)
3. 이는 설득력있는 3D 구조를 가진 mesh patch를 생성한다.(d)
위 원칙을 따르지 않고 trajectory를 디자인하면 아래와 같이 안좋은 결과를 만들어낸다.
Completion Stage
첫 단계를 통해 장면 layout과 furniture는 정의된다. 그러나 충분한 pose a-priori를 선택하는 것은 불가능하다. 장면이 실시간으로 생성되기 때문에, mesh는 어떤 camera로도 관찰되지 않은 hole을 포함한다. 본 논문에서는 이러한 hole들을 보는 추가적인 poses a-posteriori를 샘플링함으로써 장면을 완성시킨다.
Dense uniform cell들로 장면을 복셀화한다. 그리고 각 셀에 대한 random pose들을 샘플링한다. 이 과정에서 존재하는 geometry에 너무 가까운 pose들은 폐기한다. 그리고 셀 당 관측되지 않은 pixel들을 가장 많이 보는 pose를 선택한다.
앞선 방식으로 선택된 모든 pose에 대해 장면을 inpainting한다. 이 때 작은 hole들은 classical inpainting algorithm을 통해 inpainting하고 남은 hole들은 팽창시킨다. 추가적으로 팽창된 지역에 있고 rendered depth 주변에 있는 모든 면들은 제거한다.
Importance of Mask Dilation in Completion
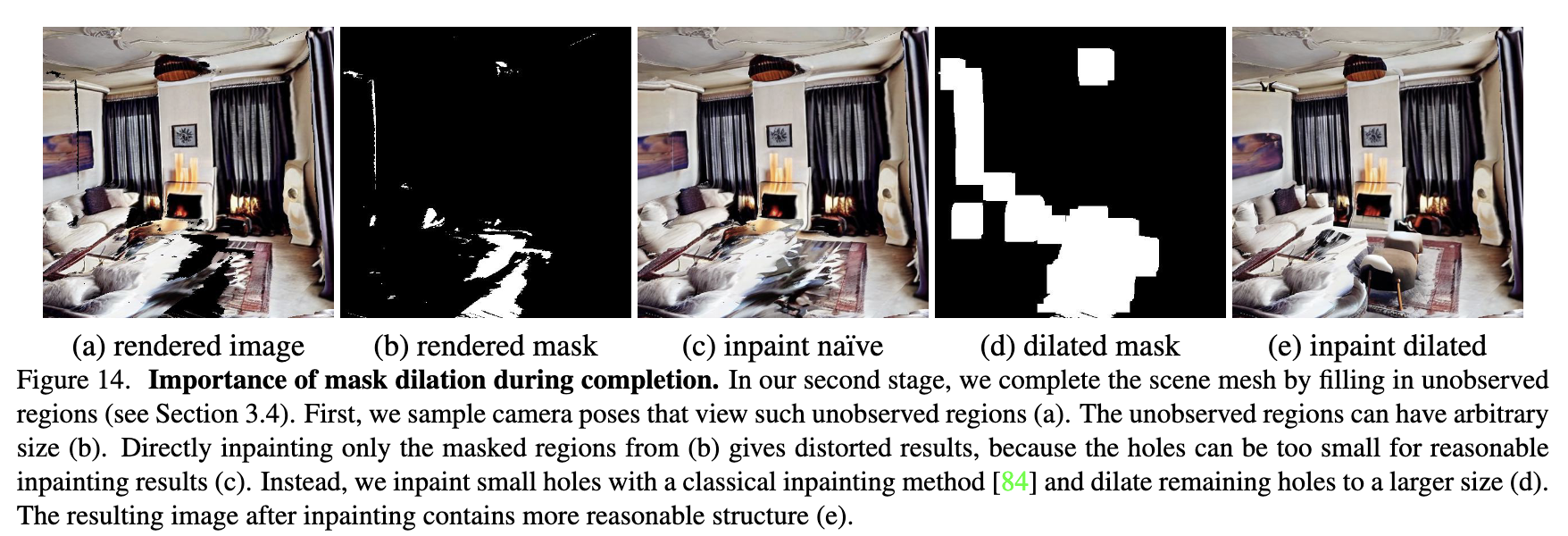
작은 hole들에 대해서는 classical inpainting algorithm을 적용하는데, 이 때 작은 hole은 inpainting mask에 $3 \times 3$ 커널을 이용한 morphological erosion 연산을 통해 분류한다. 그 후 $7 \times 7$ 커널을 이용한 morphological dilation 연산을 통해 남은 hole들의 크기를 키운다.
최종적으로 scene mesh에 대해 Poisson surface reconstruction을 한다. 이를 통해 completion 이후에 남아있는 hole들을 메우고 불연속성을 부드럽게한다. 이를 통한 결과는 생성된 장면의 watertight mesh이고 이는 classical rasterization으로 랜더링될 수 있다.
4. Results
Implementation Details
$\mathcal{F}_{t2i}$ : 추가적인 mask input을 사용하는 inpainting task에 finetuning된 Stable Diffusion
$\mathcal{F}_d$ : IronDepth
$\delta_{edge} = 0.1, \delta_{sn} = 0.1$
Baselines
- PureClipNeRF
- Outpainting
- Text2Light
- Blockade
Evaluation Metrics
- CLIPScore, Inception Score, Userstudy(Perceptual Quality, 3D Structure Completeness)
4.1 Qualitative Results


4.2 Quantitative Results
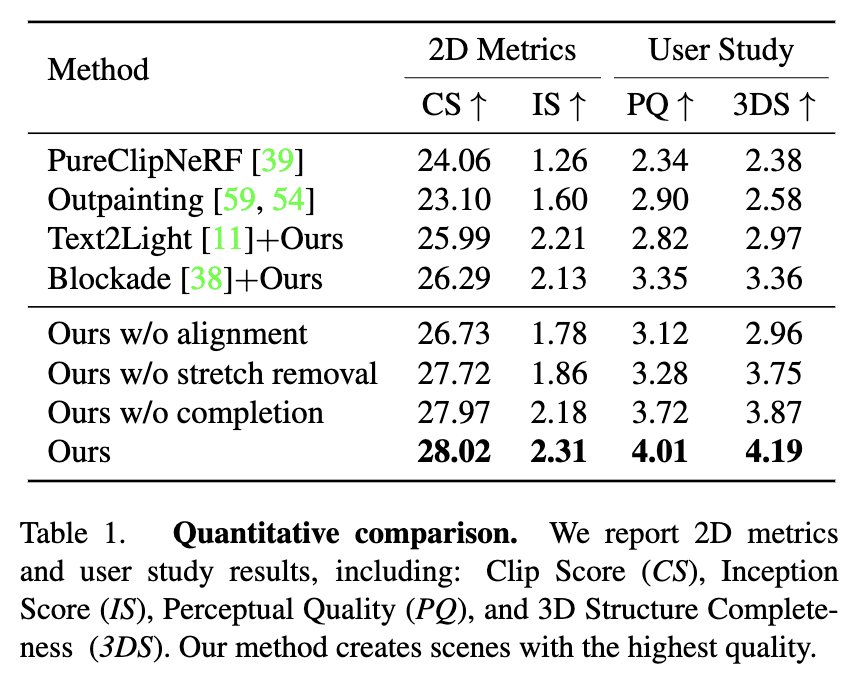
4.3 Ablations

- (a)와 표의 결과에서 볼 수 있듯이 depth alignment는 다량의 frame들을 매끄러운 mesh로 합성한다.
- (b)와 표의 결과에서 볼 수 있듯이 two filters를 통해 stretch를 제거해 undistorted scene geometry를 생성한다.
- (c)에서 볼 수 있듯이 1단계로으로는 부족하다. Completion stage를 통해 refine시킨다.
4.4 Spatially Varying Scene Generation

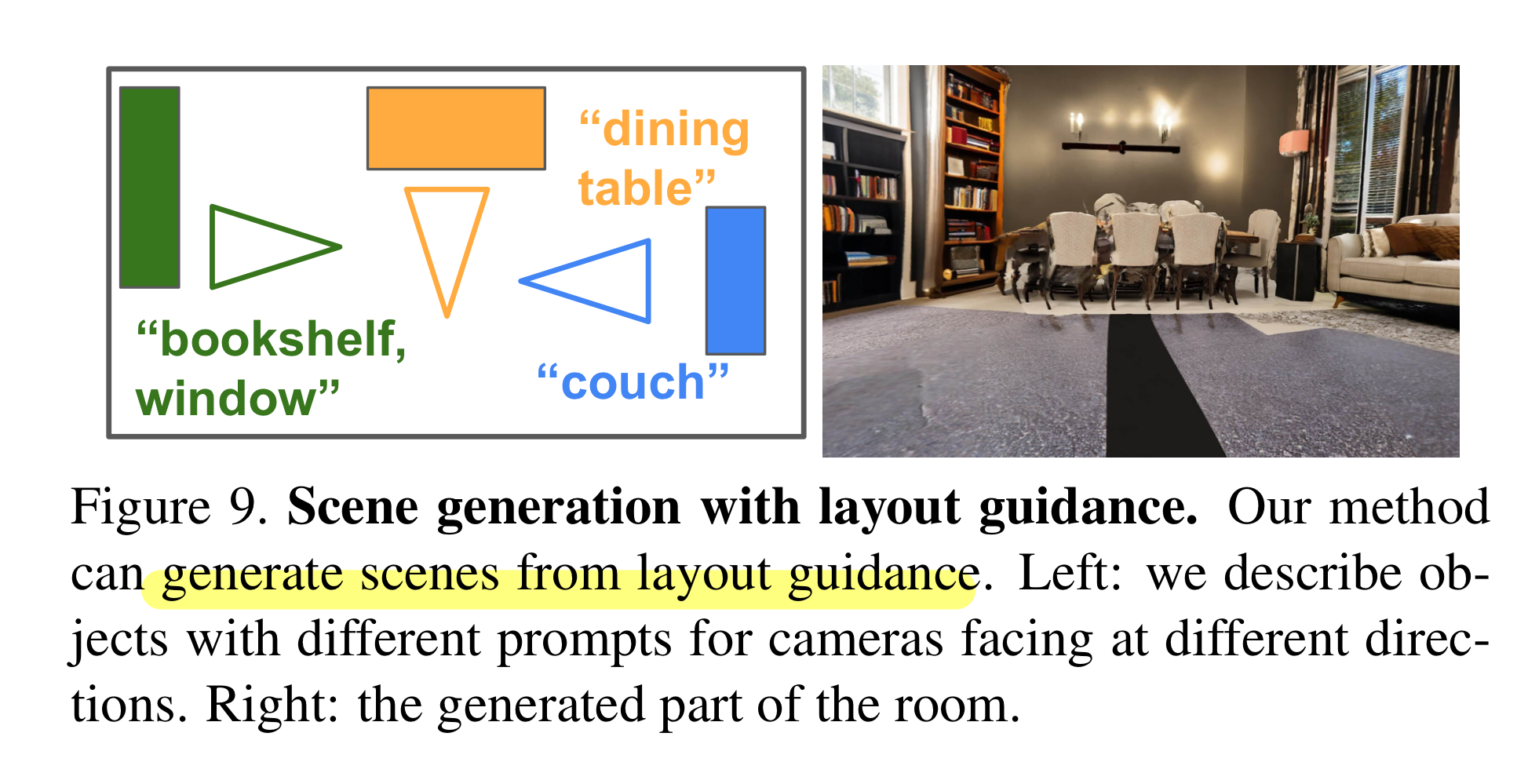
각 camera pose마다 다른 text prompt를 넣은 결과도 보여준다.
4.5 Limitations


논문을 다 읽고...
T2I model을 통한 3D 생성을 처음 공부해본 나로써는 신기했다. 뭔가 이런 분야에 대한 흥미도 생기는 듯한??? 그래도 아직 3D가 어렵기에 무섭기도...



