

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- transformer
- memorization
- Vit
- flipd
- visiontransformer
- 코딩테스트
- inversion
- rectified flow
- diffusion
- diffusion model
- Python
- flow matching
- 프로그래머스
- DP
- Programmers
- image editing
- diffusion models
- segmenation map generation
- 3d editing
- masactrl
- video generation
- noise optimization
- 3d generation
- 코테
- BOJ
- video editing
- segmentation map
- 네이버 부스트캠프 ai tech 6기
- VirtualTryON
- 논문리뷰
- Today
- Total
평범한 필기장
[평범한 학부생이 하는 논문 리뷰] MagDiff : Multi-Alignment Diffusion for High-Fidelity Video Generation and Editing (ECCV 2024) 본문
[평범한 학부생이 하는 논문 리뷰] MagDiff : Multi-Alignment Diffusion for High-Fidelity Video Generation and Editing (ECCV 2024)
junseok-rh 2024. 10. 31. 02:00Paper : https://arxiv.org/abs/2311.17338
MagDiff: Multi-Alignment Diffusion for High-Fidelity Video Generation and Editing
The diffusion model is widely leveraged for either video generation or video editing. As each field has its task-specific problems, it is difficult to merely develop a single diffusion for completing both tasks simultaneously. Video diffusion sorely relyin
arxiv.org
1. Introduction
기존에는 video를 generation하는 동시에 editing을 할 수 있는 unified model이 존재하지 않았다. 본 논문에서 제안하는 MagDiff는 이 두 task를 동시에 할 수 있는 unified model이다. 본 논문에서 강조하는 contribution은 아래 네가지이다.
- MagDiff는 full image 대신 subject-driven iamge를 extra condition으로 사용해서 video generation과 editing을 한 framework에서 하도록하는 subject-driven alignment를 제안한다.
- MagDiff는 동질적이고 이질적인 condition들의 control strength의 밸런스를 맞추는 adaptive prompt alignment를 발전시켜서 subject image와 text 둘 다에 잘 aligned되는 fine-grained video를 생성하도록했다.
- MagDiff는 multi-scale contextual 정보를 latent space에 통합함으로써 생성되거나 editing된 video의 high-fidelity를 향상시키는 high-fidelity alignment를 도입한다.
- 정량적이고 정성적인 평가에서 좋은 결과를 보인다.
2. Multi-alignment Diffusion (MagDiff)
한 프레임워크에서 high-fidelity video generation과 editing을 성취하기 위해서, 본 논문에서는 Multi-alignment Diffusion (MagDiff) model을 제안한다. 이는 생성된 video, text prompt, subject-image prompt 사이의 multi-alignment를 해결한다. 아래 이미지는 전체 모델의 overview이다.

2.1 Subject-Driven Alignment
Video generation과 editing은 text prompt 베이스로 상응한 content를 생성하려고 한다는 점에서 비슷하다. 하지만 generation은 pure noise로부터 video를 생성하고, editing은 전체 video sequence가 input으로 필요로 하고 unchanged part를 유지해야한다는 점에서 다르다. 이러한 부분에서 두 task를 통합하는 것은 어렵다. 이러한 부분을 해결하기 위해서 MagDiff는 subject-driven alignment를 도입해서 두 task를 통합한다.

Image-Driven Alignment (기존 방식)
기존 방식은 customized appearance를 달성하고 subject의 identity를 유지하려고 했다. 그래서 image-driven video diffusion 모델들은 전체 reference image와 text에 condition돼서 video를 생성했다.
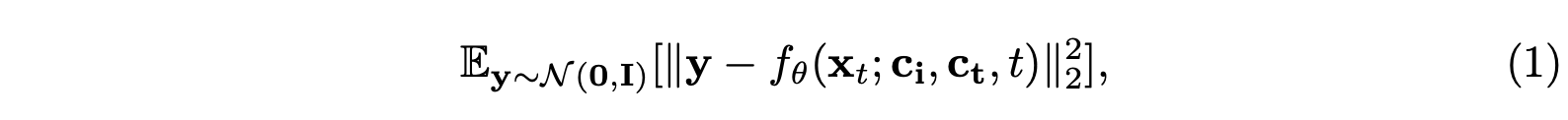
그러나 이 방식은 강하게 reference image base로 video를 생성해서, text와의 misalignment를 보였다. 그래서 image-driven method는 text prompt를 가지고 video content를 editing할 수 없어, generation과 editing을 한 프레임워크에 통합할 수 없다.
Subject-Driven Alignment
이러한 문제점을 해결하기 위해서, 본 논문에서는 text와 image prompt 사이의 tradeoff를 balancing함으로써 그들 둘 다에 대해 condition된 editability를 강화하는 subject-driven alignment를 제안한다. Full image에서 subject를 추출하기 위해서 segmentation을 사용한다. Full image 대신에 subject-driven image를 conditon으로 사용함으로써, MagDiff는 subject image와 text prompt 둘 다를 synthesized videos에 align할 수 있고 single model에 video generation과 editing을 통합할 수 있다.

이를 통해 model은 temporal information뿐만 아니라 spatial dimension에 더 attention 할 수 있다.
2.2 Adaptive Prompts Alignment
Subject-image prompt는 video와 homogeneous(동질적인) modality지만, text prompt는 heterogeneous(이질적인) modality이다. 그렇기에 denoising process에서 video generation을 control하기 위해 subject image와 text prompt는 다른 강도의 alignment를 가진다. 그들 사이의 trade-off를 만들기 위해, 본 논문은 Adaptive Prompts Alignment(APA) module을 도입한다. 이는 visual performance를 향상시키면서 두 prompts를 잘 align한다.

Fixed Prompts Alignment(기존 방식)
기존의 방식은 위 이미지에서 (b)와 같이 text prompt와 image prompt에서 각각 tow feature group $Q_1, K_1, V_1$와 $Q_2, K_2, V_2$를 CLIP을 통해 뽑는다. 그러고 나서 다음과 같이 각각 attention 연산을 거쳐 합한다.

하지만 위 연산은 text prompt와 image prompt 둘 다에 controllability 혹은 editability에 대한 동일한 weight를 할당한다. 그리고 이는 두 modality에 대해서 내재적인 다름을 고려하는데 실패한다. 이는 low-quality와 low-fidelity video를 야기한다.
Adaptive Prompts Alignment
본 논문에서 제안한 Adaptive Prompts Alignment는 위 이미지에서 (a)에서처럼 $K_1, V_1$와 $K_2, V_2$는 유지하고 $Q$를 공유하는 것이다. 여기서 $Q$는 전 layer로부터 온 feature라고 이해했다. 그래서 cross-attention 계산은 다음과 같이 진행된다.

여기서 $\alpha_1, \alpha_2$는 learnable parameter로 각각 visual part와 textual part를 동적으로 컨트롤한다. 본 논문은 두 modality에대한 다른 컨트롤을 주는 것이 중요하다는 것을 발견했다고 한다. 이를 통해, adapted feature는 paired subject-image와 text prompts에 더 의미적으로 correlate된다.
2.3 High-Fidelity Alignment
CLIP은 subject-driven image를 visual detail보다는 high-dimensional semantics의 feature로 encoding시킨다. 그래서 detailed appearance에 대한 loss를 보인다. 이러한 문제를 해결하기 위해서 본 논문에서는 High-Fidelity Alignment(HFA) module을 도입한다. 이는 subject-image prompt에 대해 생성된 video를 align하는 것에 집중한다.
HFA는 다음과 같은 형태로 되어있다.

Subject image $x_s$가 주어지면 이를 세가지 해상도로 샘플링한다. 그리고 VAE를 이용해서 이 셋을 latent features $\{ z^0_s, z^1_s, z^2_s \}$로 각각 projection시킨다. 그리고 convolution layer를 이용해 이 셋을 통해 $z_s$를 만들고 noise $z_n$에 concat 시킨다. 이러한 피라미드 구조는 다른 해상도의 input을 수용하게 해서 다른 scale에 대한 contexts를 fitting할 수 있고 input에 대한 robustness를 상승시킨다.
게다가 이 프레임워크는 VAE를 사용해서 video latent representation을 얻는다. 특히, reference image를 VAE를 통해 encoding시키고 noise를 더하지 않음으로써 denoising step에 appearance를 주입할 수 있다.
3. Experiments
3.1 Experimental Setups
Evaluation Metrics
Video Quality Evaluation : FVD, Video Inception Score
Identity Consistency and Video-prompt alignment : DINO score, cosine similarity(Frame-Consistency), CLIP score(Textual-alignment)
3.2 Comparison with State-of-the-Art
Evaluation of Video Generation

본 논문에서는 subject-driven image를 사용해서 성능이 좋다고 설명하고 있다. 또한 Table2 결과를 보면 좋은 text alignment를 가지고 frame들 사이에 continuity 또한 좋다고 할 수 있다.
Evaluation of Video Editing

Tuning-Free 방식에서는 가장 좋고 Fine-Tuning방식들과 비교해서는 거의 유사할만큼 우수하다라고 말하고 있다.
Human Evaluations

Qualitative Evaluation

3.3 Ablation Studies

SDA는 전체적인 효과를 강화한다.
- 위 이미지를 보면 subject-driven prompt가 없으면 user-definee text prompt와 맞지 않는 video를 생성하거나 주어진 text description에 condition된 video editing이 불가능하다. (SDA의 효과)
- APA 모듈이 없으면 low-fidelity인 visual results를 보인다. (APA의 효과)
- HFA를 붙이면 픽셀 수준의 multiscale 정보가 latent space로 모이기 때문에 video의 fidelity가 상승한다. (HFA의 효과)
Effect of APA

위 결과로 APA의 효과를 볼 수 있다. 또한 APA의 cross-attention map을 시각화한 결과도 있는데 APA가 정확한 단어에 attention하는 것을 볼 수 있다.
Effect of different values for $\alpha_1$ and $\alpha_2$

Supplementary Material
Model

모델은 위 구조로 되어있다. 두 개의 temporal layer와 self-attention layer, APA module만 학습시킨다.
학습 동안에는 첫번째 이미지와 그 마스크만 이용한다. Video editing을 위해 따로 학습할 필요는 없다고 한다.
More Visualizations


Limitations
- Diffusion model을 사용하기 때문에 conputationally intensive하고 time-consuming하다.
- low-contrast하거나 noisy한 이미지와 같은 종류의 이미지들에 적합하지 않다.



