

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- dreammotion
- controllable video generation
- transformer
- diffusion
- 프로그래머스
- 3d editing
- controlnext
- Programmers
- BOJ
- video generation
- segmenation map generation
- 네이버 부스트캠프 ai tech 6기
- Vit
- visiontransformer
- VirtualTryON
- diffusion model
- emerdiff
- 코테
- video editing
- segmentation map
- 3d generation
- Python
- DP
- style align
- score distillation
- 코딩테스트
- 논문리뷰
- magdiff
- image editing
- diffusion models
- Today
- Total
목록3d generation (3)
평범한 필기장
 [평범한 학부생이 하는 논문 리뷰] DreamGaussian : Generative Gaussian Splatting for Efficient 3D Content Creation (ICLR 2024 oral)
[평범한 학부생이 하는 논문 리뷰] DreamGaussian : Generative Gaussian Splatting for Efficient 3D Content Creation (ICLR 2024 oral)
https://arxiv.org/abs/2309.16653 DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content CreationRecent advances in 3D content creation mostly leverage optimization-based 3D generation via score distillation sampling (SDS). Though promising results have been exhibited, these methods often suffer from slow per-sample optimization, limiting their practiarxiv.org1. Introduction 최근 3D ..
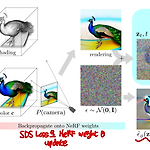 [평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
https://arxiv.org/abs/2209.14988 DreamFusion: Text-to-3D using 2D DiffusionRecent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoiarxiv.org1. Introduction Diffusion model은 다양한 다른 modality에서 적용되는데 성..
 [평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral)
[평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral)
https://arxiv.org/abs/2303.11989 Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image ModelsWe present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outparxiv.org요약다루는 task : 2D Text-to-Image m..