
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- controlnext
- diffusion
- 코테
- 3d editing
- Programmers
- video generation
- diffusion models
- 네이버 부스트캠프 ai tech 6기
- 프로그래머스
- score distillation
- BOJ
- 코딩테스트
- Python
- image editing
- segmenation map generation
- transformer
- controllable video generation
- diffusion model
- Vit
- 논문리뷰
- 3d generation
- magdiff
- video editing
- DP
- dreammotion
- visiontransformer
- VirtualTryON
- segmentation map
- emerdiff
- masactrl
- Today
- Total
목록transformer (2)
평범한 필기장
 [모델 구현] Vision Transformer 구현
[모델 구현] Vision Transformer 구현
스터디를 통해 Vision Transformer 논문은 읽어봤지만 구현은 해보지 않았었다. 네붓캠 이번주 강의가 DL Basic이여서 Transformer관련 내용도 나오고 코드로 구현하는 실습도 있었다. 그래서 내가 논문 정리해 놓은 것과 연관지어서 코드구현한 것을 포스팅하면 좋을 것 같아서 이렇게 포스팅하게 되었다. Vision Transformer 논문에 대한 포스팅은 아래 링크에서 볼 수 있다. https://juniboy97.tistory.com/40 [평범한 학부생이 하는 논문 리뷰] An Image is Worth 16X16 Words: Transformers for Image Recognotion at Scale (ViT) Transformer 아키텍쳐가 NLP에서 많이 쓰이지만 Visio..
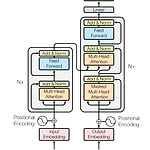 [평범한 학부생이 하는 논문 리뷰] Attention is all you need (Transformer)
[평범한 학부생이 하는 논문 리뷰] Attention is all you need (Transformer)
Transformer 자체는 이 전에 CS231n으로 대충 공부는 해봤지만 그래도 중요한 논문이기에 논문 자체를 읽어봐야겠다는 생각을 했었다. 이번 방학 때 시간이 되어 논문을 읽어보고 블로그에도 정리해보는 시간을 가졌다. 이번 논문 리뷰는 나동빈님의 논문 리뷰영상과 자료를 많이 참고해서 작성했다.https://arxiv.org/abs/1706.03762 Attention Is All You NeedThe dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models als..