

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- posterior distillation sampling
- 3d editting
- 3d gaussian splatting
- transformer
- BOJ
- diffusion
- 논문리뷰
- text-to-video diffusion
- sonicdiffusion
- VirtualTryON
- magic clothing
- Programmers
- 네이버 부스트캠프 ai tech 6기
- visiontransformer
- Python
- 코딩테스트
- text2room
- novel view synthesis
- 프로그래머스
- objectdrop
- 코테
- DP
- insturctnerf2nerf
- 3d generation
- 3d editing
- dreamfusion
- instructany2pix
- Vit
- dreamgaussian
- sound-to-image generation
- Today
- Total
목록2024/04 (7)
평범한 필기장
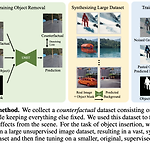 [평범한 청강생의 논문 맛보기] ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
[평범한 청강생의 논문 맛보기] ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
https://arxiv.org/abs/2403.18818 ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and InsertionDiffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approachearxiv.org1. Introduc..
 [평범한 학부생이 하는 논문 리뷰] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen)
[평범한 학부생이 하는 논문 리뷰] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen)
1. Introduction 본 논문은 Imagen을 도입하는데 이는 text-to-image 합성에서 전례없는 정도의 photorealism과 깊은 수준의 언어 이해를 가져오기 위해 transformer language models와 high-fidelity diffusion model을 결합한 text-to-image diffusion model이다. Imagen의 key finding은 text-only corpora로 기학습된 large LM으로부터 text embedding이 text-to-image 합성에서 놀라운 효과적이라는 것이다. Imagen은 input text를 sequence of embeddings로 매핑하기 위한 frozen T5-XXL encoder와 $64 \times 64$..
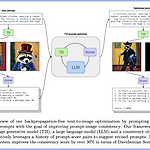 [평범한 청강생의 논문 맛보기] Improving Text-to-Image Consistency via Automatic Prompt Optimization (OPT2I)
[평범한 청강생의 논문 맛보기] Improving Text-to-Image Consistency via Automatic Prompt Optimization (OPT2I)
https://arxiv.org/abs/2403.17804 Improving Text-to-Image Consistency via Automatic Prompt Optimization Impressive advances in text-to-image (T2I) generative models have yielded a plethora of high performing models which are able to generate aesthetically appealing, photorealistic images. Despite the progress, these models still struggle to produce images th arxiv.org 1. Introduction 기존의 T2I 모델들은..
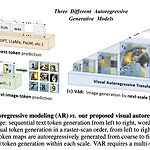 [평범한 청강생의 논문 맛보기] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction (VAR)
[평범한 청강생의 논문 맛보기] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction (VAR)
주재걸 교수님의 DAVIAN Lab에서 진행하는 computer vision study를 청강하게 되었다. 최신 논문들을 다루는 것 같아서 따라가기 힘들겠지만 최대한 스터디 전에 간단하게 어떤 논문인지 맛보고 스터디 청강을 해야겠다는 생각이 들었다. 그래서 이 스터디에서 읽을 논문들은 최대한 어떤 논문인지 간단하게만 정리해보려고 한다. 이번 주의 논문은 "VAR"이다. https://arxiv.org/abs/2404.02905
 [평범한 학부생이 하는 논문 리뷰] Classifier-Free Diffusion Guidance
[평범한 학부생이 하는 논문 리뷰] Classifier-Free Diffusion Guidance
https://arxiv.org/abs/2207.12598 Classifier-Free Diffusion GuidanceClassifier guidance is a recently introduced method to trade off mode coverage and sample fidelity in conditional diffusion models post training, in the same spirit as low temperature sampling or truncation in other types of generative models. Classifier garxiv.org1. Introduction Clasiifier Guidance는 학습된 classifier를 이용해..
 [평범한 학부생이 하는 논문 리뷰] Diffusion Models Beat GANs on Image Synthesis
[평범한 학부생이 하는 논문 리뷰] Diffusion Models Beat GANs on Image Synthesis
1. Introduction 기존 diffusion models는 LSUN과 ImageNet과 같은 어려운 generation에서는 GAN (BIgGAN-deep)에 경쟁이 되지 않는 FID score를 냈다. 본 논문에서 diffusion models와 GANs사이의 차이는 (1) 최신 GAN의 architecture는 고도로 연구되고 refine되었다는 것과 (2) GANs는 다양성을 fidelity로 맞바꿀 수 있다는 것이다. 본 논문에서는 이 두 가지의 이점을 가져오는 것을 목표로 한다. (1)은 모델 아키텍쳐를 향상시킴으로써 (2)는 다양성을 fidelity로 맞바꾸는 계획을 구상함으로써 해결하려한다. 이를 통해 몇 개의 metric과 dataset에서 GAN을 뛰어넘는 sota를 달성했다고 한..
 [평범한 학부생이 하는 논문 리뷰] Denoising Diffusion Implicit Models (DDIM)
[평범한 학부생이 하는 논문 리뷰] Denoising Diffusion Implicit Models (DDIM)
이번에 리뷰할 논문은 DDIM 이다. 붓캠 기간동안 진행한 diffusion 스터디의 마지막 논문이였는데, 이 논문을 읽는 기간이 최종 프로젝트때문에 한창 정신이 없을 기간이어서 제대로 집중해서 읽지 못했었다. 그래서 최종 프로젝트를 제출하고 다시 읽고 리뷰를 남겨야지라고 미루다가 이제야 리뷰를 하게 됐다. https://arxiv.org/pdf/2010.02502.pdf 0. Abstract DDPM은 높은 수준의 이미지 생성할 수 있다. 그렇지만 이미지를 생성하려면 많은 스텝을 거쳐야한다. 그래서 DDPM과 동일한 training 절차를 거치지만 더 효율적인 DDIM을 제안한다. 본 논문은 DDPM을 non-Markovian diffusion 프로세스를 통해 일반화한다. 이러한 non-Markovia..