

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- image editing
- Programmers
- transformer
- 논문리뷰
- score distillation
- diffusion
- magdiff
- Python
- 코딩테스트
- diffusion models
- VirtualTryON
- 3d generation
- segmenation map generation
- emerdiff
- video editing
- BOJ
- 네이버 부스트캠프 ai tech 6기
- diffusion model
- Vit
- 코테
- video generation
- segmentation map
- dreammotion
- 3d editing
- 프로그래머스
- visiontransformer
- DP
- style align
- controllable video generation
- controlnext
- Today
- Total
목록분류 전체보기 (91)
평범한 필기장
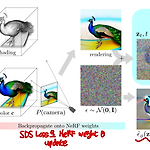 [평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
[평범한 학부생이 하는 논문 리뷰] DreamFusion : Text-to-3D using 2D Diffusion (ICLR 2023)
https://arxiv.org/abs/2209.14988 DreamFusion: Text-to-3D using 2D DiffusionRecent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoiarxiv.org1. Introduction Diffusion model은 다양한 다른 modality에서 적용되는데 성..
네이버 부스트캠프 수료를 하고 약 3개월이 되간다.... 부스트캠프를 시작하기 전에 내가 상상하던 모습은 아니긴하다ㅎㅎ 부스트캠프를 시작하기 전에 1년 휴학을 하고 세웠던 계획은 부스트캠프를 통해 엄청난 성장을 하고 복학 전까지 인턴을 하는 것이 목표였으나 역시 인생은 계획대로 되지 않는다. 부스트캠프를 시작하면서 한 다짐만큼 내가 열심히 하지 않은 탓이 아닐까.. 그래도 그 만큼의 성장은 아니였지만 당연히 5~6개월간 나름대로 성장은 했고 또 많은 경험을 했고 또 많은 사람들은 만나면서 정말 잊지 못할 경험을 한 것은 사실이다. 주변에 네이버 부스트캠프 ai tech를 하고 싶어하는 사람들이 좀 있는데 나는 정말 x100 강추한다. 아무튼 수료하면서 수료 후기? 포스팅을 할려고 했지만 나의 귀차니즘으로..
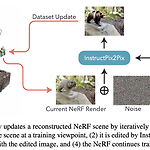 [평범한 학부생이 하는 논문 리뷰] Instruct-NeRF2NeRF : Editing 3D Scene with Instructions (ICCV 2023 oral)
[평범한 학부생이 하는 논문 리뷰] Instruct-NeRF2NeRF : Editing 3D Scene with Instructions (ICCV 2023 oral)
https://arxiv.org/abs/2303.12789 Instruct-NeRF2NeRF: Editing 3D Scenes with InstructionsWe propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an image-conditioned diffusion model (InstructPix2Pix) to iteratively edit the input images whiarxiv.org1. Introduction NeRF와 같은 3D reconstruction 기술..
 [평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral)
[평범한 학부생이 하는 논문 리뷰] Text2Room : Extracting Textured 3D Meshes from 2D Text-to-Image Models (ICCV 2023 oral)
https://arxiv.org/abs/2303.11989 Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image ModelsWe present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outparxiv.org요약다루는 task : 2D Text-to-Image m..
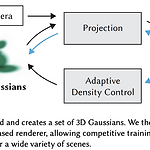 [평범한 학부생이 하는 논문 리뷰] 3D Gaussian Splatting for Real-Time Radiance Field Rendering (SIGGRAPH 2023)
[평범한 학부생이 하는 논문 리뷰] 3D Gaussian Splatting for Real-Time Radiance Field Rendering (SIGGRAPH 2023)
https://arxiv.org/abs/2308.04079 3D Gaussian Splatting for Real-Time Radiance Field RenderingRadiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methoarxiv.org1. Introduction NeRF 기반의 방식들은 high quali..
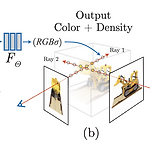 [평범한 학부생이 하는 논문 리뷰] NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV 2020 oral)
[평범한 학부생이 하는 논문 리뷰] NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV 2020 oral)
https://arxiv.org/abs/2003.08934 NeRF: Representing Scenes as Neural Radiance Fields for View SynthesisWe present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-conarxiv.org 랩실 인턴을 시작하기 전에 연구 주제에 대한 레퍼런스..
 [평범한 학부생이 하는 논문 리뷰] SonicDiffusion : Audio-Driven Image Generation and Editing with Pretrained Diffusion Model (arXiv 2405)
[평범한 학부생이 하는 논문 리뷰] SonicDiffusion : Audio-Driven Image Generation and Editing with Pretrained Diffusion Model (arXiv 2405)
https://arxiv.org/abs/2405.00878 SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion ModelsWe are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. Warxiv.org1. Introdu..
 [평범한 학부생이 하는 논문 리뷰] InstructAny2Pix : Flexible Visual Editing via Multimodal Instruction Following (arXiv 2312)
[평범한 학부생이 하는 논문 리뷰] InstructAny2Pix : Flexible Visual Editing via Multimodal Instruction Following (arXiv 2312)
https://arxiv.org/abs/2312.06738 InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction FollowingThe ability to provide fine-grained control for generating and editing visual imagery has profound implications for computer vision and its applications. Previous works have explored extending controllability in two directions: instruction tuning with textarxiv.orghttps://github.com/jack..
 [DEVOCEAN OpenLab] PEEKABOO : Interactive Video Generation via Masked Diffusion
[DEVOCEAN OpenLab] PEEKABOO : Interactive Video Generation via Masked Diffusion
https://arxiv.org/abs/2312.07509 PEEKABOO: Interactive Video Generation via Masked-DiffusionModern video generation models like Sora have achieved remarkable success in producing high-quality videos. However, a significant limitation is their inability to offer interactive control to users, a feature that promises to open up unprecedented applicaarxiv.org1. Introduction 본 논문에서는 PEEKABOO를 도입한다. 이..
 [DEVOCEAN OpenLab] Follow Your Pose : Pose-Guided Text-to-Video Generation using Pose-Free Videos
[DEVOCEAN OpenLab] Follow Your Pose : Pose-Guided Text-to-Video Generation using Pose-Free Videos
https://arxiv.org/abs/2304.01186 Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free VideosGenerating text-editable and pose-controllable character videos have an imperious demand in creating various digital human. Nevertheless, this task has been restricted by the absence of a comprehensive dataset featuring paired video-pose captions and the garxiv.org1. Introduction Text-to..